Clear Sky Science · he
אסטרטגיית בקרה הומנואידית המבוססת על למידה עמוקה מחזקת לנוחות מוגברת ברובוטים לשיקום הגפיים התחתונות
רובוטים שעוזרים לאנשים ללכת שוב
כאשר למישהו קשה ללכת לאחר שבץ מוחי או פגיעה בחוט השדרה, הטיפול עשוי להיות איטי, מתיש ולא נוח. רובוטים לשיקום הגפיים התחתונות מיועדים לתמוך ולהנחות את רגלי המטופל במהלך האימון, אך המכונות של היום לעיתים קרובות מרגישות נוקשות ו"רובוטיות". מחקר זה בוחן כיצד הענקת "מוח" יותר אנושי לרובוטים האלה — באמצעות אלגוריתמי למידה מתקדמים — יכולה להפוך את האימון לרך יותר, טבעי יותר ולבסוף יעיל יותר עבור המטופלים.
מדוע אימון הליכה צריך להרגיש טבעי
עם הזדקנות האוכלוסייה, יותר אנשים חיים עם בעיות משמעותיות בהליכה ורבים פונים לשיקום בעזרת רובוט. רובוטים מסורתיים עוקבים אחרי מסלולי רגליים מתוכנתים מראש ומשתמשים בחוקי בקרה פשוטים להזזת המפרקים. למרות האמינות, שיטות אלה מתקשות עם המציאות המסובכת של התנועה האנושית: ההליכה של כל אדם שונה במעט, ורובוט נוקשה עלול למשוך או לדחוף באופן שירגיש מוזר או אפילו כואב. המחברים טוענים שעבור שיקום יעיל, הרובוט לא צריך רק לשמור על המטופל זקוף ונע אלא גם להסתגל לדפוסי הליכה טבעיים ולמזער את הכוחות שהוא מפעיל על הגוף.
למידה מצעדים אנושיים אמיתיים
כדי ללמד את הרובוט כיצד אנשים באמת הולכים, החוקרים קודם בנו מודל מתמטי מפושט של הרגליים והגוף. לאחר מכן הקליטו נתוני הליכה מחמישה מתנדבים בריאים באמצעות מערכת מדידה תלת־ממדית מדויקת ולוחות כח ברצפה. סימני השתקפות על הירכיים, הברכיים, הקרסוליים והגוף אפשרו להם לחשב איך כל מפרק נע לאורך צעד מלא, בעוד החיישנים מתחת לכפות הרגליים מדדו עד כמה כל רגל לוחצת על הקרקע. מתוך מדידות אלה יצרו עקומות ייחוס חלקות לזוויות הירך והברך ועקבו אחרי שינויי הכוחות במפרקים לאורך הזמן, תוך לכידת גם את הצורה וגם את הקצב של הליכה נורמלית.
בקר חכם שעדיין שומר על בטיחות
הליבה של המאמר היא אסטרטגיית בקרה "הומנואידית" חדשה שמשלבת למידה עמוקה מחזקת (DRL) עם בקר פרופורציונלי-נגזרתי (PD) קלאסי. DRL הוא סוג של בינה מלאכותית שבו סוכן וירטואלי מנסה פעולות, צופה בתוצאות ולומד בהדרגה מה עובד על ידי מקסום אות תגמול. במקרה הזה, הסוכן יושב מעל שכבת ה-PD: הוא רואה את זוויות ומהירויות המפרקים של הרובוט ומחליט אילו מומנטים להפעיל, בעוד שכבת ה-PD דואגת שהמפרקים לא יתנדו הרחק מזוויות יעד בטוחות ודומות לאנושיות. פונקציית התגמול מעוצבת בקפידה כדי לעודד הליכה יציבה קדימה ובמקביל להעניש כל דבר שירגיש רע למטופל — כגון תנועה קופצנית, כוחות גדולים במפרקים או תנוחות לא בטוחות כמו הטיה מופרזת או מרווח רגל נמוך מדי מהרצפה.
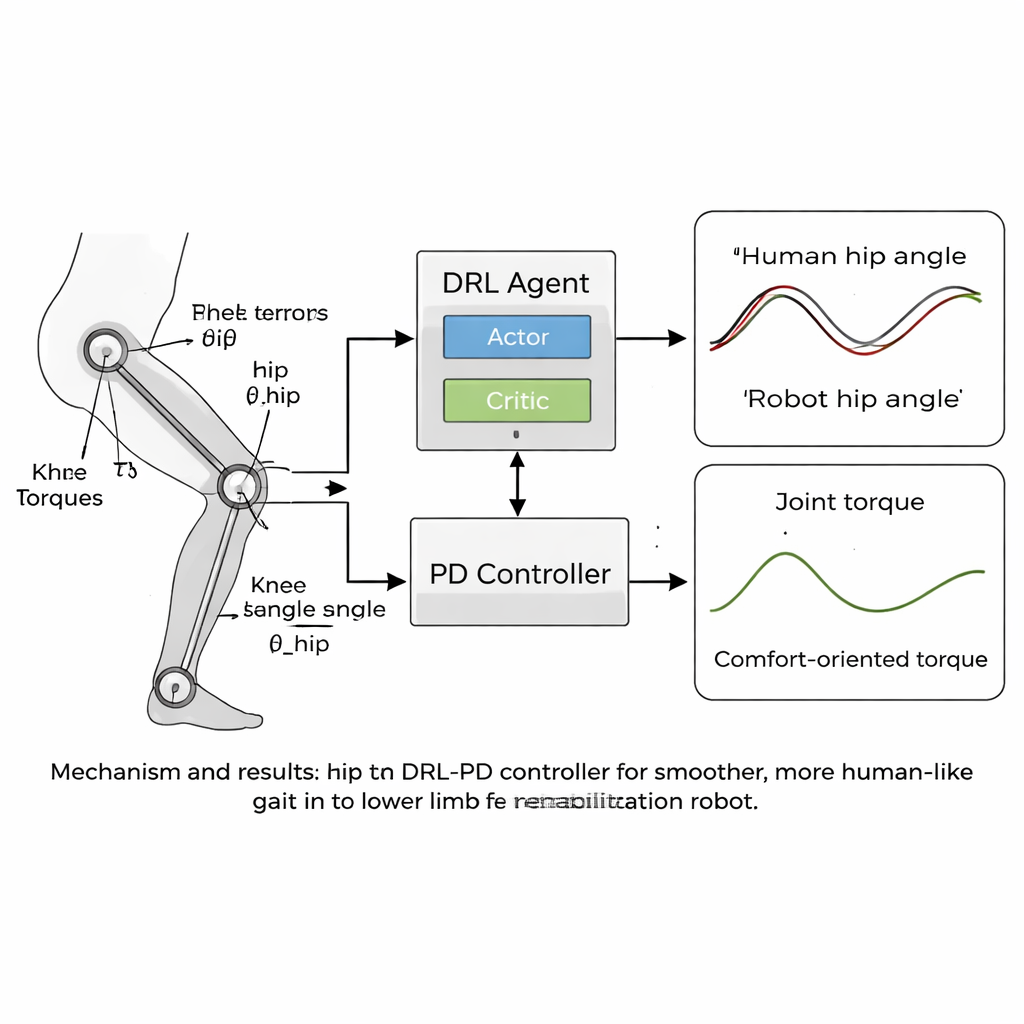
תנועה חלקה יותר, קרובה יותר להליכה אנושית
הצוות בחן את הגישה שלהם בסימולציות ממוחשבות באמצעות מודל של רובוט שיקום לגפיים תחתונות עם מפרקי ירך וברך שתואמו לנתוני ההליכה שלהם. במהלך אלפי פרקי אימון, בקר ה-DRL-PD למד ליצור מחזור הליכה חוזר שבו זוויות המפרקים עקבו מקרוב אחרי דפוסי הייחוס האנושיים. הירכיים והברכיים של הרובוט נעו בלופים קבועים ויציבים, סימן לליכה אמינה וחזרתית. באופן משמעותי, המומנטים הנדרשים להזזת המפרקים הפכו לחלקים וקטנים יותר בהשוואה לבקר PD סטנדרטי. מדדים כמותיים הראו כי שגיאות המעקב ירדו לכמה עשיריות רדיאן בלבד, וקצב השינוי של מומנטים המפרקים — מדד לפריכות התחושות של הכוחות עבור המטופל — הצטמצם ביותר מחצי. בנוסף, הבקר נשאר יציב גם כאשר מסת הרגלים במודל השתנתה בכמה אחוזים, מה שמעיד על יכולת עמידה בשונות אמיתית בין משתמשים.
מה זה אומר עבור רובוטי שיקום בעתיד
ללא מומחיות טכנית, המסר העיקרי פשוט: על ידי מתן אפשרות לרובוט ללמוד את הקצב והגבולות של ההליכה האנושית מתוך נתונים אמיתיים, ומתן תגמול על חלקות ועדינות, ניתן לעצב מכונות שעוזרות לאנשים להתאמן על הליכה בצורה שמרגישה טבעית ופחות מלחיצה. מטופלים עשויים להיות מוכנים יותר להשתתף במפגשים ארוכים ותכופים יותר אם הרובוט נע איתם במקום נגדם. למרות שהתוצאות הנוכחיות מבוססות על סימולציות ודורשות מחשבים רבי־עוצמה לאימון, לאחר שהלמידה הושלמה ניתן להפעיל את הבקר ביעילות על מכשירים אמיתיים. המחברים רואים בעבודה זו צעד לקראת רובוטי שיקום מותאמים אישית ומסתגלים שמכוונים לכל דפוס הליכה וצרכי נוחות של המטופל, מה שעשוי לשפר הן את ההתאוששות והן את איכות החיים.
ציטוט: Jin, Y., Zhang, J., Li, W. et al. A humanoid control strategy based on deep reinforcement learning for enhanced comfort in lower limb rehabilitation robots. Sci Rep 16, 7370 (2026). https://doi.org/10.1038/s41598-026-39011-7
מילות מפתח: רובוטים לשיקום, אימון הליכה, למידה עמוקה מחזקת, שלד חיצוני (אקסוסקלטון), נוחות המטופל