Clear Sky Science · he
מסגרת למידת עומק עם שני זרמים לזיהוי שפת סימנים רציפה לשיפור הנגישות התקשורתית באזור חאיל
גישור על פער התקשורת
עבור אנשים רבים חירשים, שפת הסימנים היא הדרך העיקרית לתקשר, אך רוב המחשבים, הטלפונים והשירותים הציבוריים עדיין אינם מבינים אותה. המאמר מציג מערכת בינה מלאכותית חדשה שיכולה לצפות בכתיבה רציפה בסרטון ולהמיר אותה למילים כתובות בדיוק גבוה יותר. על-ידי התמקדות לא רק בתנועות הידיים אלא גם במיקום הראש ובאותות פנים, המערכת שואפת להנגיש תקשורת מבוססת טכנולוגיה בצורה טבעית ונגישה יותר — במיוחד עבור הקהילות החרשות באזור חאיל בערב הסעודית, שם התמיכה הדיגיטלית עדיין מוגבלת. 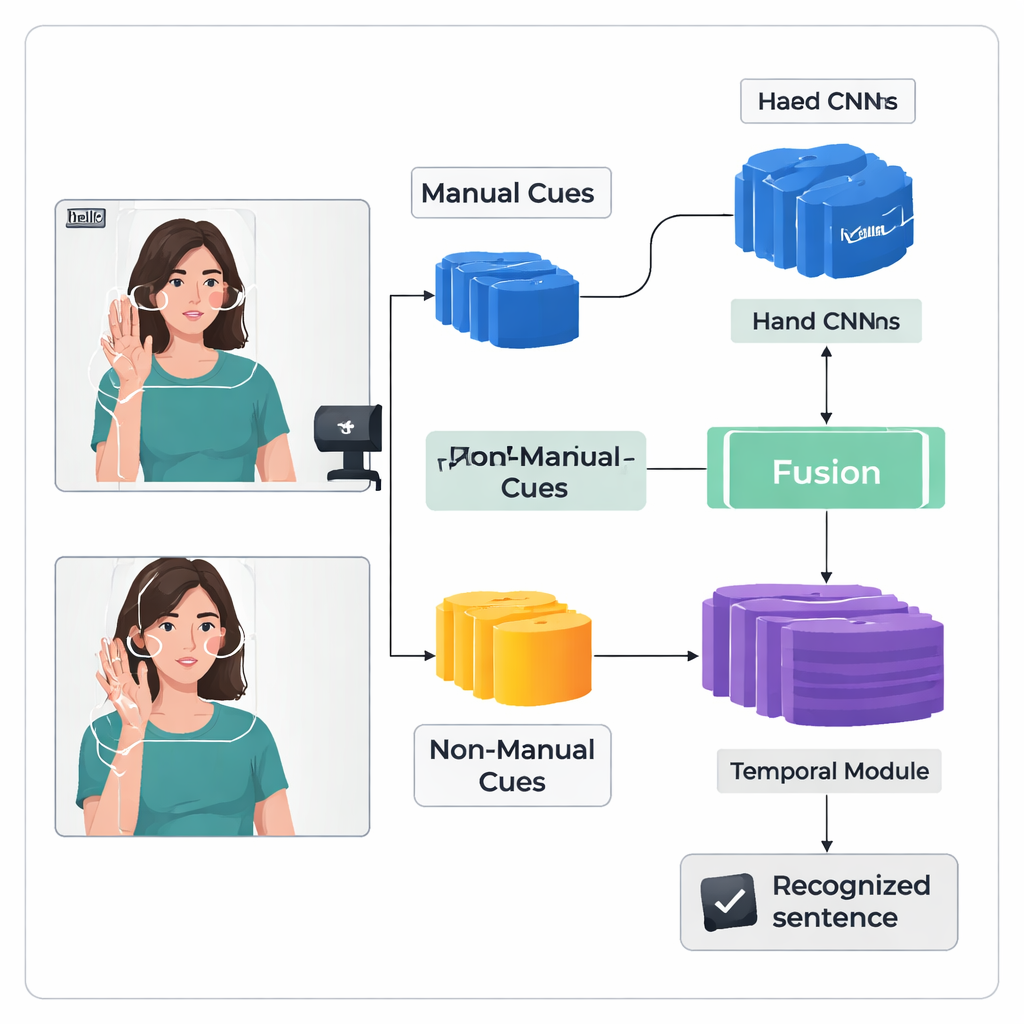
מדוע הידיים אינן מספיקות
שפות סימנים הן מערכות עשירות ומורכבות שמשתמשות בחלק העליון של הגוף כולו. המשמעות אינה נובעת רק מתנועות הידיים, אלא גם מתוך הבעות הפנים, הכיוון שבו החותר מביט וכיווני הנטייה או ההנהון של הראש. אותות שאינם ידיים אלה יכולים לסמן שאלות, שלילה, דגשים או רגשות. בני אדם קוראים את כל אלה ללא מאמץ, אך רוב המערכות הממוחשבות לזיהוי שפת סימנים מתמקדות בעיקר בידיים. קיצור דרך זה מפשט את האימון אך גורם לאובדן רמזים חשובים, במיוחד כאשר הסימנים זורמים יחד במשפטים רציפים ומהירים במקום במילים מבודדות.
שני זרמים העובדים במקביל
המחברים מציגים מסגרת למידת עומק "שתי-זרמים" בשם TS-CNN שעובדת על ידיים וראש בנפרד ואז מאחדת ביניהם. זרם אחד מתרכז בתמונות חיתוך של ידיו של החותר, ולומד תבניות של צורה, תנועה ומיקום. הזרם השני מקבל מפת-תמצית של הפנים והראש, המופקת מנקודות סימון ואומדני תנוחת ראש. שני הזרמים משתמשים בסוג רשת ראייתי סטנדרטי להפיכת כל פריים של הווידאו לתכונות מספריות. לאחר מכן המערכת מאחדת את התכונות הללו פריים אחר פריים, תוך שמירה על כך שאותות ידיים וראש מתרחשים באותו הזמן בזיהוי טבעי. מודול זמני מאוחר יותר מסתכל על מסגרות רבות כדי להבין כיצד הסימנים מתפתחים לאורך הזמן, ושכבת זיכרון חוזרת מייצרת רצף של יחידות סימן מתועדות, או "גלוסים".
חידוד זיכרון המערכת של הסימנים
זיהוי כתיבה רציפה קשה כי נתוני האימון מוגבלים והסימנים מתמזגים ללא תוויות ברורות פר פריים. כדי להתמודד עם זאת, המחברים מוסיפים מודול חידוד תכונות שנותן לרשת הדרכה נוספת במהלך האימון. טכניקה נפוצה מיישרת את רצף הגלוסים החזהה עם הווידאו, ומייצרת מיקומים סבירים לכל גלוס בזמן. המודול החדש לוקח הצעות יישור אלה ומשתמש בהן כפיקוח ישיר כדי ללטש את הייצוג הפנימי של תכונות הגלוס. בפשטות, המערכת לומדת לא רק להפיק את הרצף הנכון, אלא גם לבנות "זיכרונות" פנימיים בהירים ועקביים יותר של איך כל סימן נראה בסרטונים שונים.
בדיקת הגישה
הצוות מעריך את TS-CNN על שתי קבוצות נתונים מוכרות של שפת סימנים: RWTH-PHOENIX-Weather 2014 לשפת הסימנים הגרמנית ו-CSL Split II לשפת הסימנים הסינית. הם מודדים ביצועים באמצעות שיעור שגיאות מילים, מדד סטנדרטי המקביל לזה שבזיהוי דיבור. בהשוואה לבסיס שמתמקד רק בתנועות ידיים, הוספת נתוני תנוחת הראש מקטינה את השגיאות בכ-4 נקודות אחוז בנתונים הגרמניים ובכ-3–4 נקודות בנתונים הסיניים. הוספת מודול חידוד התכונות מביאה לשיפורים גדולים אף יותר, עם הפחתת שגיאות של כ-10–14 אחוזים בסך הכל בשתי קבוצות הנתונים. המערכת גם פועלת ביעילות, מגיעה למהירויות זמן-אמת על מעבד גרפי מודרני, דבר קריטי אם היא מיועדת לשימוש בפרשנות חיה או בכלים ניידים. 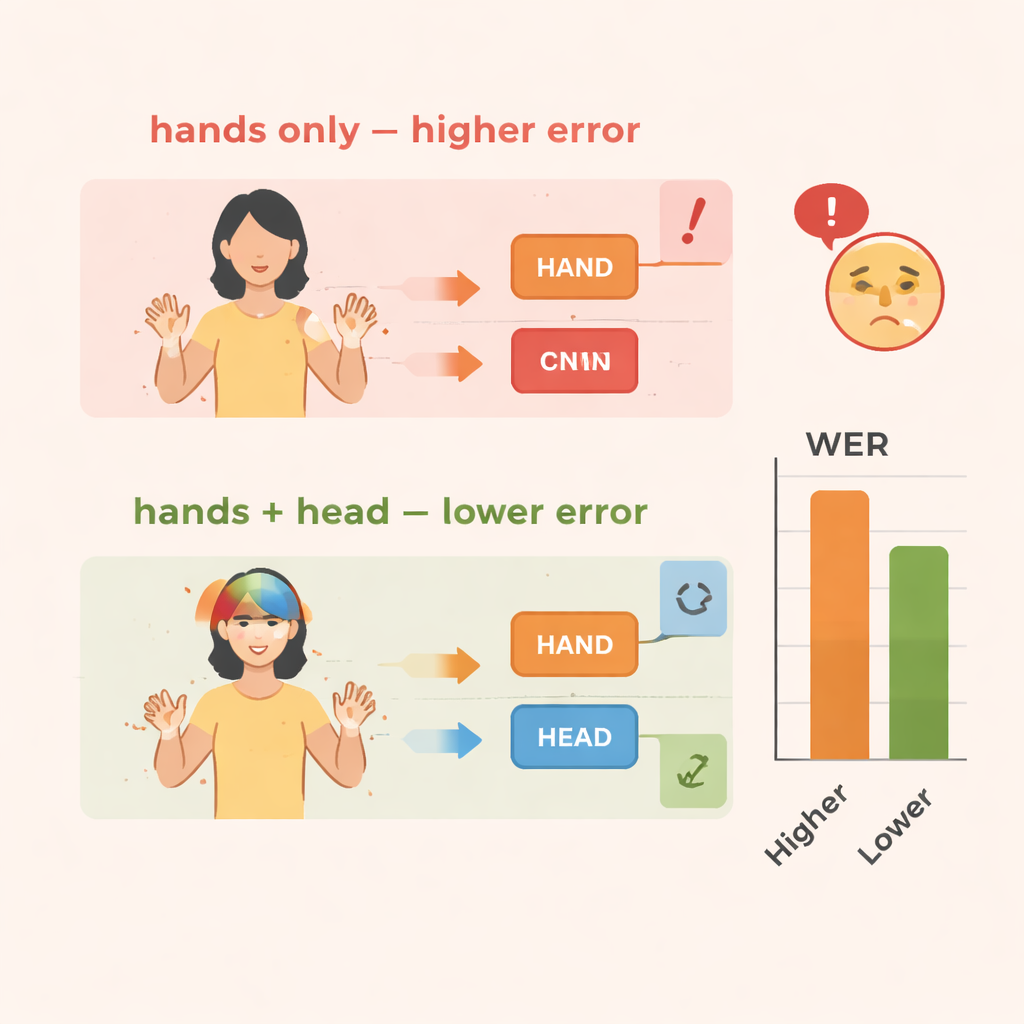
מה משמעות הדבר לחיי היומיום
במונחים יומיומיים, המחקר מראה שמחשבים יכולים להבין שפת סימנים בצורה אמינה יותר כאשר הם צופים בכל החותר, לא רק בידיים. על-ידי דגם תנועות ראש ואותות פנים לצד תנועות הידיים, ובאמצעות ליטוש זהיר של האופן שבו המערכת לומדת מנתוני אימון מוגבלים, מסגרת TS-CNN מתקרבת למערכות מעשיות שיכולות לסייע לאנשים חירשים בכיתות, בבתי חולים ומשרדים ציבוריים. עבור אזורים כמו חאיל, שבהם מתורגמנים אנושיים נדירים ופרויקטים טכנולוגיים עדיין בתחילת הדרך, מערכת כזו עשויה בסופו של דבר לתמוך בתקשורת מכלילה יותר — לסייע בגישור בין דוברי שפת הסימנים לעולם השומעים מבלי להחליף את החוויה האנושית העשירה של השפה עצמה.
ציטוט: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
מילות מפתח: זיהוי שפת סימנים, למידת עומק, נגישות, ראייה ממוחשבת, אינטראקציה אדם–מחשב