Clear Sky Science · he
הערכת ביצועי מודלים לשוניים גדולים במבחני המועצה האורתופדית הפרסית בריאומטולוגיה: דיוק וחשיבה קלינית של GPT-4o לעומת GPT-5.1
מדוע זה חשוב לרופאים ולמטופלים
בינה מלאכותית נכנסת במהירות לכיתות הרפואה ולמרפאות, אך רוב הבדיקות של כלים אלה מתמקדות באנגלית. המחקר הזה שואל שאלה החשובה למיליוני דוברי פרסית: עד כמה צ׳אטבוטים מתקדמים של בינה מלאכותית, ובפרט GPT‑4o ו‑GPT‑5.1, מטפלים היטב בשאלות מורכבות במבחני ראומטולוגיה הכתובות בפרסית? התשובה מסייעת למדריכים, למתאמנים ולמטופלים להבין היכן כלים אלה יכולים לסייע בבטחה בלמידה ומהם התחומים שבהם המומחיות האנושית עדיין חיונית.
בחינת הבינה המלאכותית
החוקרים אספו 204 שאלות רב‑ברירה מהמבחנים הרשמיים של מועצת הראומטולוגיה האיראנית לשנים 2023 ו‑2024, אותם מבחנים שמומחים חייבים לעבור כדי לקבל הסמכה. לאחר שהוסרו שבע שאלות פגומות, נשארו 197 פריטים לשימוש. כל שאלה, כולל תמונות או גרפים נלווים, הוזנה בפרסית ל‑GPT‑4o ול‑GPT‑5.1 בשיחות נפרדות וטריות. מן המודלים נדרש לבחור את התשובה הטובה ביותר ולהסביר את טיעוניהם, בדומה לאופן שבו מתלמד עשוי לשאול כלי בינה מלאכותית בזמן לימוד.
בדיקה גם של התשובות וגם של ההיגיון
הביצועים הוערכו בשתי דרכים. ראשית, האפשרויות שנבחרו על ידי המודלים הושוו עם תשובת המפתח הרשמית, מה שהניב מדד דיוק פשוט של נכון/לא נכון. שנית, שישה ראומטולוגים מוסמכים דירגו באופן עצמאי את איכות כל ההסברים בסולם של חמישה‑נקודות, מהיגיון ברור ושגוי ועד היגיון קליני שלם ומוצק. תשובות כל מודל הוערכו על ידי שני ראומטולוגים שונים אשר לא ידעו את דירוגי זה של זה ולא ידעו את תשובת המפתח הרשמית. כך יכולו החוקרים לראות לא רק האם ה‑AI "ניחש נכון", אלא גם האם הלוגיקה שלו דומה לאופן בו מומחים חושבים.
כיצד הביצוע של הדגם החדש יותר
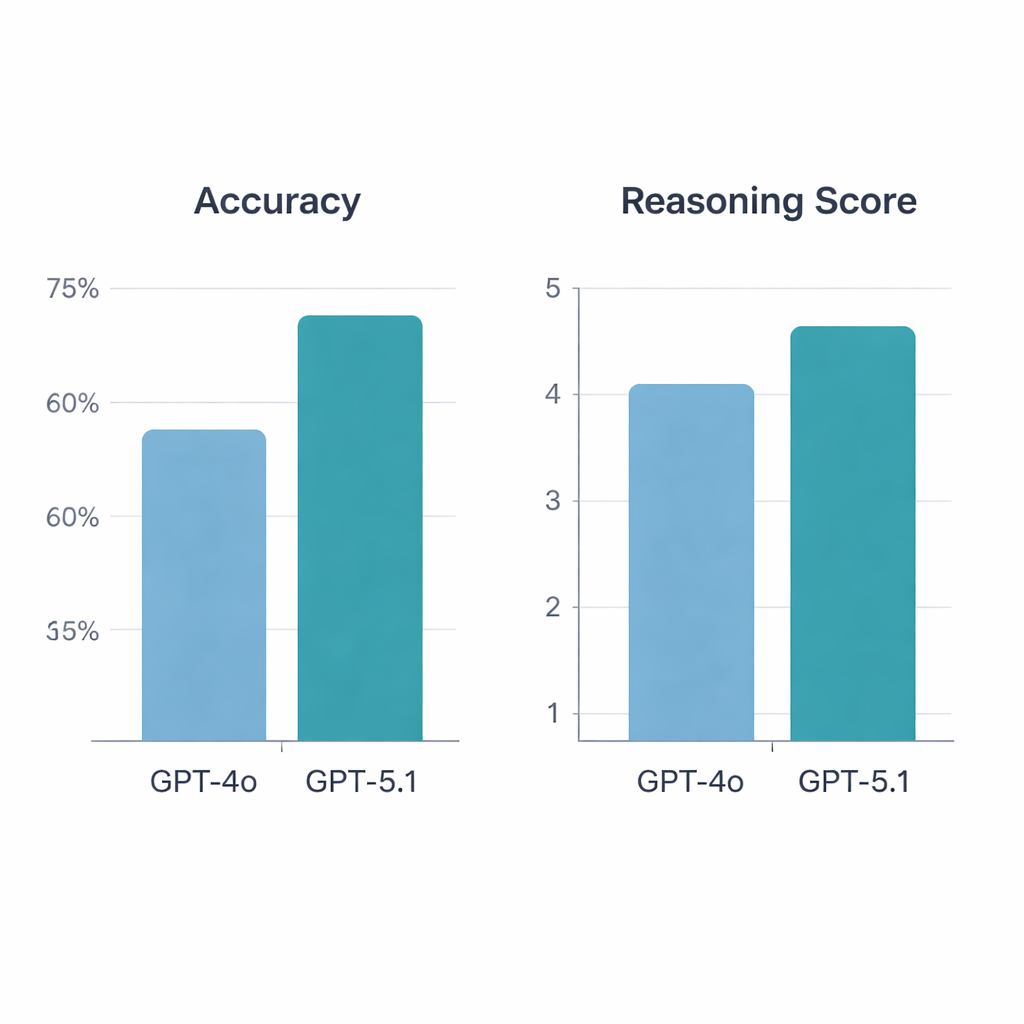
GPT‑5.1 הביא לתוצאות גבוהות משמעותית בהשוואה ל‑GPT‑4o. מתוך 197 השאלות התקפות, GPT‑4o ענה נכון על 64.5% מהשאלות, בעוד GPT‑5.1 הגיע לדיוק של 76% — קפיצה סטטיסטית משמעותית. שני המודלים ענו נכון על 113 שאלות וטעו ב‑34, אך GPT‑5.1 פתר באופן בלעדי 36 שאלות נוספות ש‑GPT‑4o החמיץ; GPT‑4o היה נכון באופן ייחודי רק ב‑13 שאלות. כאשר הראומטולוגים דורגו את ההסברים, GPT‑5.1 שוב הוביל, עם ציון ממוצע של 4.47 מתוך 5 לעומת 4.13 ל‑GPT‑4o, והוא קיבל יותר דירוגים של הציון הגבוה ביותר. בניגוד ל‑GPT‑4o, שאיכות ההיגיון שלו השתנתה בהתאם אם השאלה עסקה במדעי יסוד, תיאורי מקרה, אבחנה או טיפול, GPT‑5.1 שמר על ביצועים יותר אחידים בכל הקטגוריות.
חוזקות, פערים ואי‑הסכמות אנושיות
המחקר חשף ניואנסים חשובים. אפילו כאשר התשובה הסופית של המודל הייתה שגויה, לעיתים המומחים שפטו שההיגיון שלו די קוהרנטי, מה שמדגיש פער בין ניקוד מבחן לחשיבה קלינית בעולם האמיתי. יחד עם זאת, ההסכמה בין המדרגים הראומטולוגים הייתה רק צנועה, מה שמדגיש שגם הקלינאים עצמם שונים בדעותיהם לגבי מה נחשב "היגיון טוב". השפה גם נראתה חשובה: מחקרים קודמים באנגלית ובספרדית דיווחו על ציונים גבוהים יותר לדגמים דומים, מה שמרמז כי ה‑AI מטפל עדיין טוב יותר בשפות עיקריות בעולם מאשר בפרסית. הכותבים מדגישים שצ׳אטבוטים אלה יכולים לייצר הסברים משכנעים שמסתירים שגיאות עובדתיות, ושביצועיהם עשויים להשתנות ככל שהמערכות מעודכנות.
מה זה אומר להבא
לקוראים מן השורה, המסר הוא שהדור החדש של צ׳אטבוטי ה‑AI משתפר בטיפול במבחני מומחים רפואיים בפרסית, אך אינו מוכן להחליף הכשרה קפדנית או שיפוט מומחה. GPT‑5.1 יכול לשמש כשותף עזר יעיל ללימוד למתמחים בראומטולוגיה — לסכם נושאים, להדריך דרך מקרים ולספק הסברים מובנים — אך אין לסמוך עליו כעל המילה האחרונה בהחלטה בעלת השלכות גבוהות לגבי אבחנה או טיפול. הכותבים קוראים למחקרים רחבים יותר רב‑לשוניים, לבחינות חוזרות לאורך זמן ולסימולציות קליניות ריאליסטיות כדי לקבוע כיצד ניתן לשלב כלים אלה בבטחה בחינוך הרפואי ולבסוף בטיפול היומיומי בחולים.
ציטוט: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
מילות מפתח: ראומטולוגיה, חינוך רפואי בפרסית, מודלים לשוניים גדולים, חשיבה קלינית, מבחני מועצה