Clear Sky Science · he
מודל משולב מובן המבוסס על CNN–טרנספורמר לזיהוי שפת סימנים במכשירי קצה באמצעות מיזוג אדפטיבי ודיסטילציה של ידע
מדוע כלים זעירים לשפת סימנים חשובים
מיליארדי שיחות יומיות נשענות על תנועות יד, הבעות פנים ושפת גוף יותר מאשר על מילים מדוברות. ועדיין, מרבית הטלפונים, הטאבלטים והמכשירים ציבוריים אינם מבינים שפות סימנים, במיוחד מחוץ למדינות דוברות אנגלית. מאמר זה מציג את TinyMSLR, מערכת קומפקטית ומוסברת לזיהוי שפת סימנים שנועדה לפעול בזמן אמת על מכשירים קטנים וחסכוניים באנרגיה. מטרתה להפוך חומרה רגילה לעזרים תקשורתיים זולים, אמינים ונגישים לעולמם של אנשים חירשים או עם לקות שמיעה ברחבי העולם.
הבאת שפות נוספות לשיחה
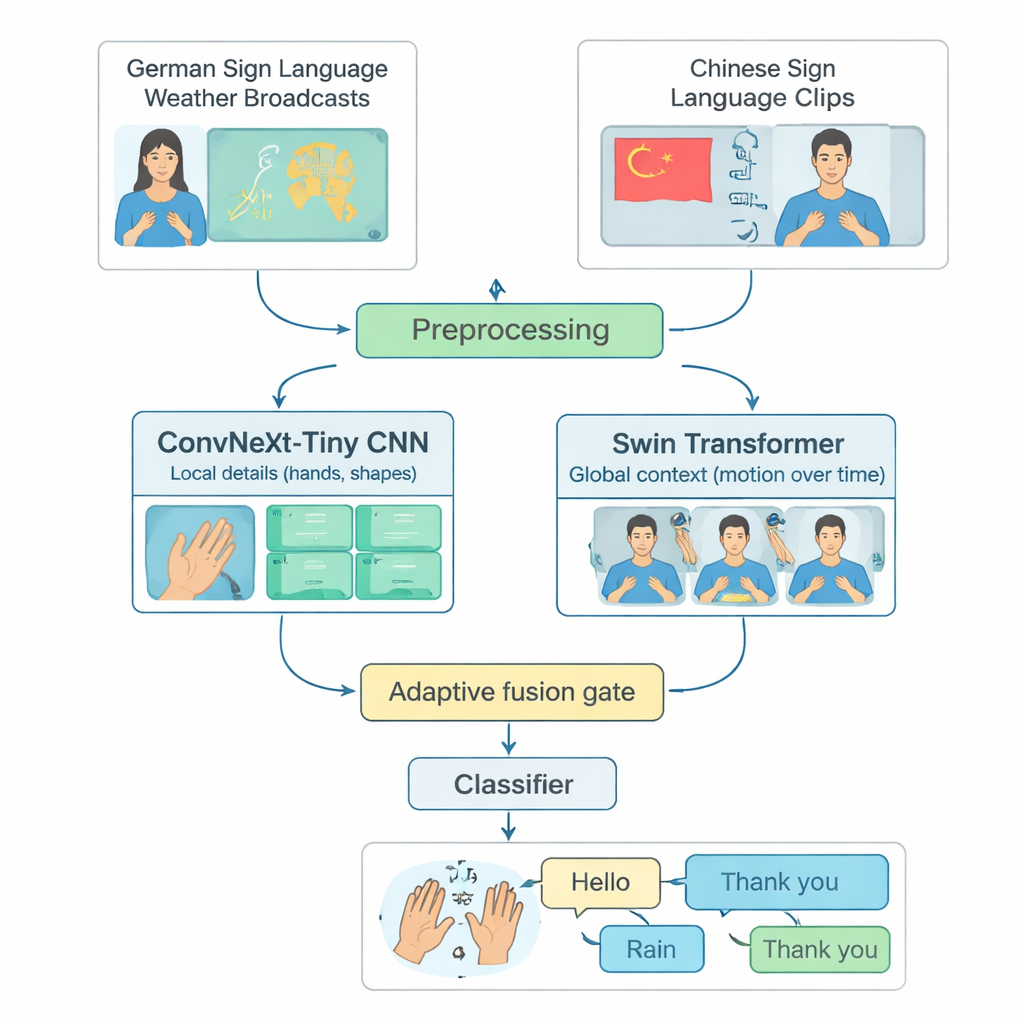
רבים ממערכות זיהוי שפת סימנים המתקדמות מתמקדות בשפה יחידה, בדרך כלל בשפת הסימנים האמריקאית, ופועלות רק על מחשבים חזקים. זה משאיר מצבים בהם משתמשים בשפות סימנים אחרות או באזורים עם משאבי חישוב מוגבלים מחוץ לתחום. המחברים מטפלים בפער הזה על‑ידי בניית מבחן משותף משתי שפות שונות: שידורי מזג אוויר בשפת הסימנים הגרמנית ואוסף נרחב של שפת הסימנים הסינית. הם בוחרים בקפידה 20 סימנים יומיומיים נפוצים — כמו שלום, מזג אוויר, גשם, שמח, כן ותודה — הקיימים בשתי השפות. בעזרת חיתוך סרטונים ארוכים לקליפים קצרים שמכילים סימן אחד בלבד, ואיזון מספר הדוגמאות לפי מחלקה ולפי החותם, הם יוצרים דרך הוגנת ושחזורית להעריך עד כמה מודל מצליח לזהות סימנים מבודדים חוצי‑שפה.
איך המודל ההיברידי ‘‘רואה’’ ידיים ותנועה
TinyMSLR משלב שתי דרכי הסתכלות משלימות על וידאו. ענף אחד משתמש ברשת קונבולוציה מודרנית (ConvNeXt‑Tiny) שמצטיינת בזיהוי פרטים עדינים, כמו צורות אצבעות ומרקמים עדינים. הענף השני משתמש ב‑Swin Transformer, משפחה חדשה של מודלים שמצטיינת במעקב אחרי דפוסים במרחב ובזמן — איך ידיים, פנים ומעליון הגוף נעים על פני פריימים מרובים. כל קליפ קצר מומר ל‑32 פריימים ברזולוציה של 224×224 פיקסלים, מועשר בעדינות (למשל סיבובים קטנים או שינויי בהירות), ואז מוזן לשני הענפים במקביל. כל ענף מפיק סיכום בן 768 מספרים של מה שהוא “ראה”; יחד שתי הסיכומים הללו לוכדים גם פרטים מקומיים חדים וגם תנועה והקשר רחבים יותר.
להניח למודל להחליט מה חשוב יותר
מכיוון שסימנים מסוימים מובחנים בעיקר לפי צורת היד בעוד שאחרים נשענים על תנועת זרוע רחבה או רמזי פנים, TinyMSLR אינו מקבע נוסחה אחת לשילוב שתי התצפיות. במקום זאת הוא משתמש ב"שער מיזוג" קטן שלומד, עבור כל קליפ קלט, כמה לסמוך על הענף המתמקד בפרטים לעומת הענף המתמקד בהקשר. השער מסתכל על שני סיכומי התכונות ומייצר שני משקלים שתמיד מסתכמים לאחד; הייצוג הסופי הוא תערובת משוקללת של השניים. במהלך האימון כל ענף גם מקבל ממיר קטן משלו כדי שיילמד להיות שימושי באופן עצמאי, וזוג רשתות "מורה" גדולות יותר (אחת CNN, אחת Transformer) מלוות בעדינות את המודל הקטן על‑ידי הצגת לא רק התווית הנכונה אלא גם אילו תוויות חלופיות נראות דומות. טכניקה זאת, שנקראת דיסטילציה של ידע, מסייעת למערכת הקומפקטית להתקרב לדיוק של מודלים כבדים יותר תוך שמירה על גודלה ומהירותה המתאימים למכשירי קצה.
לראות מדוע המערכת מקבלת כל החלטה
מעבר לדיוק הגולמי, המחברים מדגישים כי משתמשים ומפתחים צריכים להיות מסוגלים לבחון למה המודל נותן תשומת לב. הם מאמצים את SHAP, משפחת כלים שמספקת ערך חשיבות לכל חלק בקלט. למעשה, הם מחשבים הסברים אלה על תכונות ביניים וממפים אותם חזרה לפריימים כמפות חום ותרשימי זמן. זה חושף, למשל, אילו פריימים ואיזורים מניעים את ההחלטה בין סימנים דומים חזותית כמו גשם ושלג או קר וגרוע. איסוף של הרבה הסברים מגלה דפוסים רחבים יותר: רמזים שאינם‑מאנואליים כגון הבעת פנים ותנועת ראש, כמו גם כיוון שורש כף היד וצורת היד, בולטים כמשפיעים במיוחד. תובנות אלה עוזרות לאמת שהמערכת נשענת על היבטים משמעותיים של ההחתמה ולא על ארטיפקטים ברקע.

מהירות, חיסכון וחלל לצמיחה
בבנצ'מרק הבילינגואלי של 20 הסימנים, TinyMSLR מגיע לכ‑99% דיוק באימון ובאימות ולציון F1 קרוב ל‑99%, כשהוא משתמש בפחות מ‑2.7 מיליון פרמטרים ובכ‑1.9 מיליארד פעולות לכל קליפ. על GPU מודרני הוא מעבד סימן בכ‑13.5 מילישניות ומשתמש בפחות מ‑30 מיליג'אול של אנרגיה; המודל המאוחסן תופס רק כ‑7.2 מגהבייט. נתונים אלה מרמזים כי זיהוי סימנים בזמן אמת על‑מכשיר הוא אפשרי על לוחות ועל מערכות משובצות בעלות נמוכה. המחברים מדויקים לציין שעבודתם מתמקדת בסימנים קצרים ומבודדים ובשתי שפות בלבד, ומטפלת בהבעות פנים באופן עקיף ולא כאות מובחן. הרחבת הגישה לאוצר מילים עשיר יותר, משפטים רציפים, שפות נוספות ומודלינג מפורש של תנועות פנים וראש נותרו למחקר עתידי. ובכל זאת, TinyMSLR מהווה הוכחה משכנעת לרעיון: כלים מדויקים, יעילים ומובנים להבנת שפות סימנים אינם חייבים להישאר בענן — הם יכולים לפעול ישירות על מכשירים יומיומיים.
ציטוט: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
מילות מפתח: זיהוי שפת סימנים, למידת מכונה זעירה, AI בקצה, AI מובן, מודלים רב‑שפתיים