Clear Sky Science · he
SAT: טרנספורמר ייחוס הזזה לניקוי רעש בווידאו ללא הערכת זרימה
ווידאו חדים יותר מסצנות מרעישות
כל מי שניסה לצלם בפנים בלילה או בטלפון בתאורה חלשה מכיר את התוצאה: וידאו גרעיני ומתקלף שבו הפרטים מטושטשים והצבעים נראים לא מדויקים. מאמר זה מציג דרך חדשה לנקות וידאו כזה, ולהפוך אותו לרצפים ברורים ויציבים יותר מבלי להסתמך על תוכנות מעקב תנועה כבדות שמקובל להשתמש בהן. השיטה, הנקראת Shift Alignment Transformer, מעוצבת כך שתשמור על פרטים עדינים ועדיין תפעל ביעילות מספקת לשימוש מעשי.
מדוע ניקוי וידאו כל כך קשה
הסרת רעש מתמונה אחת היא כבר אתגר; לעשות זאת עבור וידאו קשה עוד יותר. מצד אחד, כל פריים מושפע מטיפות אקראיות ושינויים צבעיים. מצד שני, הפריימים מקושרים לאורך הזמן: עצמים נעים, המצלמה רועדת ופרטים מופיעים ונעלמים. שיטות מסורתיות לניקוי וידאו נשענות על הערכת תנועה בין פריימים, לעתים באמצעות כלי שנקרא optical flow, שמנסה לעקוב אחר תזוזת כל פיקסל מפריים לפריים. למרות העוצמה שלהן, הערכות תנועה אלה יכולות לקרוס בקלות כאשר הווידאו רעשני מאוד או שהתנועה מהירה ומורכבת, והן גם מוסיפות עומס חישובי גדול שיכול להאט מערכות באופן משמעותי.
דרך חדשה ליישור ללא מעקב
במקום לנסות במפורש לעקוב אחרי כל פיקסל, ה-Shift Alignment Transformer (SAT) נוקט בגישה אחרת: הוא מאפשר לרשת לגלות באופן משתמע כיצד הפריימים קשורים זה לזה על ידי הזזות והשוואת תכונות באופן חכם. המודל בנוי סביב ארכיטקטורה מודרנית הידועה כטרנספורמר, שמצטיינת בזיהוי קשרים לטווח ארוך בנתונים. במסגרת זו, המחברים מציגים מודול הזזה מרחבי-זמני שמערבב בעדינות מידע בזמן ובמרחב. בזירה הזמן, המודל מזיז מחזורית תכונות של פריימים כך שבשכבה אחר שכבה כל פריים יכול "לראות" רחוק יותר אל העבר והעתיד. במרחב, הוא מחלק תכונות לקבוצות קטנות ומזיז כל קבוצה בכיוונים שונים. השילוב הזה מחקה ביעילות כיצד עצמים עשויים לנוע בווידאו, ומאפשר לרשת ליישר מידע מפריימים שונים מבלי לחשב שדה תנועה מפורש.
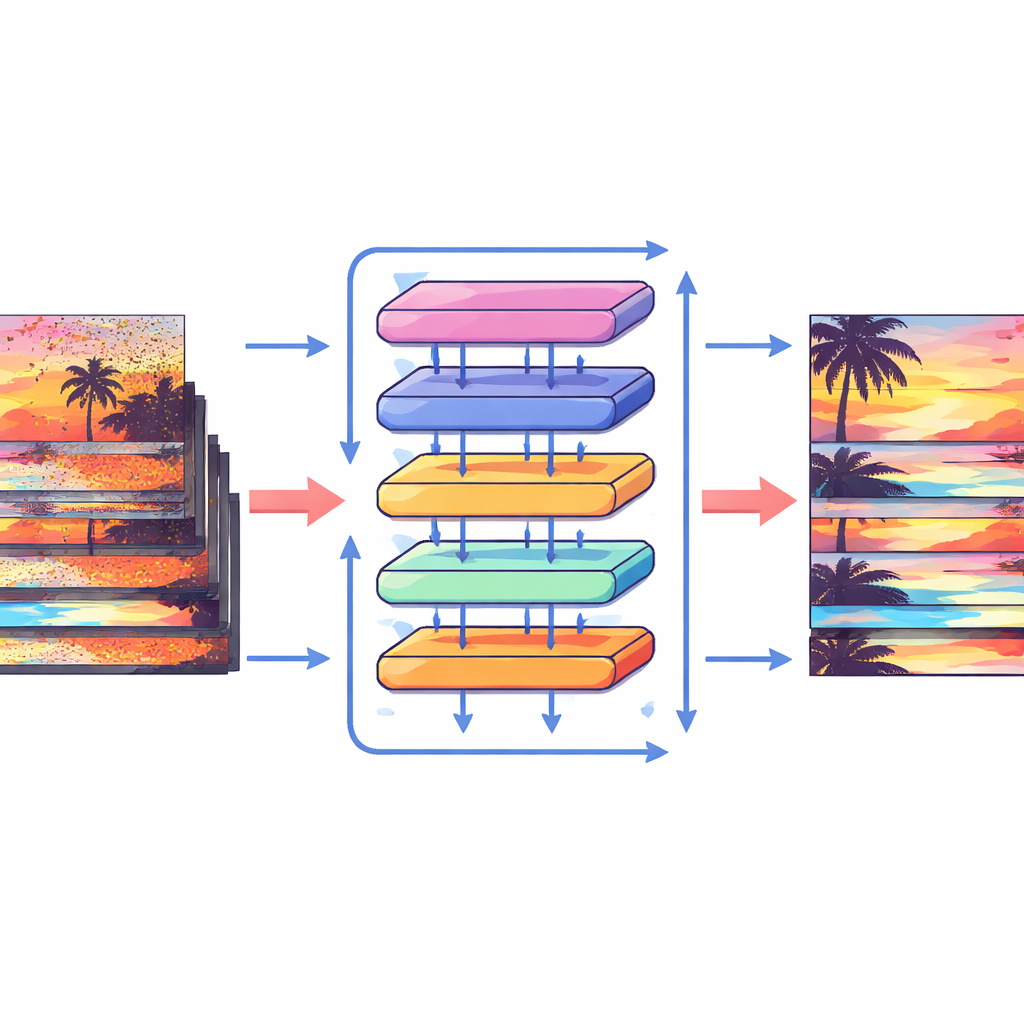
כיצד החלקים החדשים עובדים
כדי למצות את יתרונות ההזזות הללו, המחברים תכננו בלוק תשומת לב מיוחד שמערבב מידע בתוך פריימים ובעברם. ראשית, התכונות שהוזזו מפריימים שכנים נאספות ומושוו בשיטת cross-attention: המודל לומד אילו אזורים בפריימים אחרים תומכים בצורה הטובה ביותר בפריים הנוכחי בכל מיקום. במקביל, פעולה נפרדת של תשומת לב מתמקדת בקשרים בתוך כל פריים בודד, ומחזקת מבנה וטקסטורה מקומיים. שני הזרמים האלה מאוחדים ומעוברים דרך שכבות עיבוד פשוטות ברשת בצורת U רב-קנה מידה, המתחילה ברזולוציה גסה ומתקדמת לדקה וחוזרת חזרה. פריסת עבודה זו מאפשרת למערכת להתמודד גם עם תנועות מצלמה גדולות וגם עם פרטים זעירים כמו קצוות דקים או דפוסים קטנים, ולבנות בהדרגה גרסה נקייה של כל פריים.
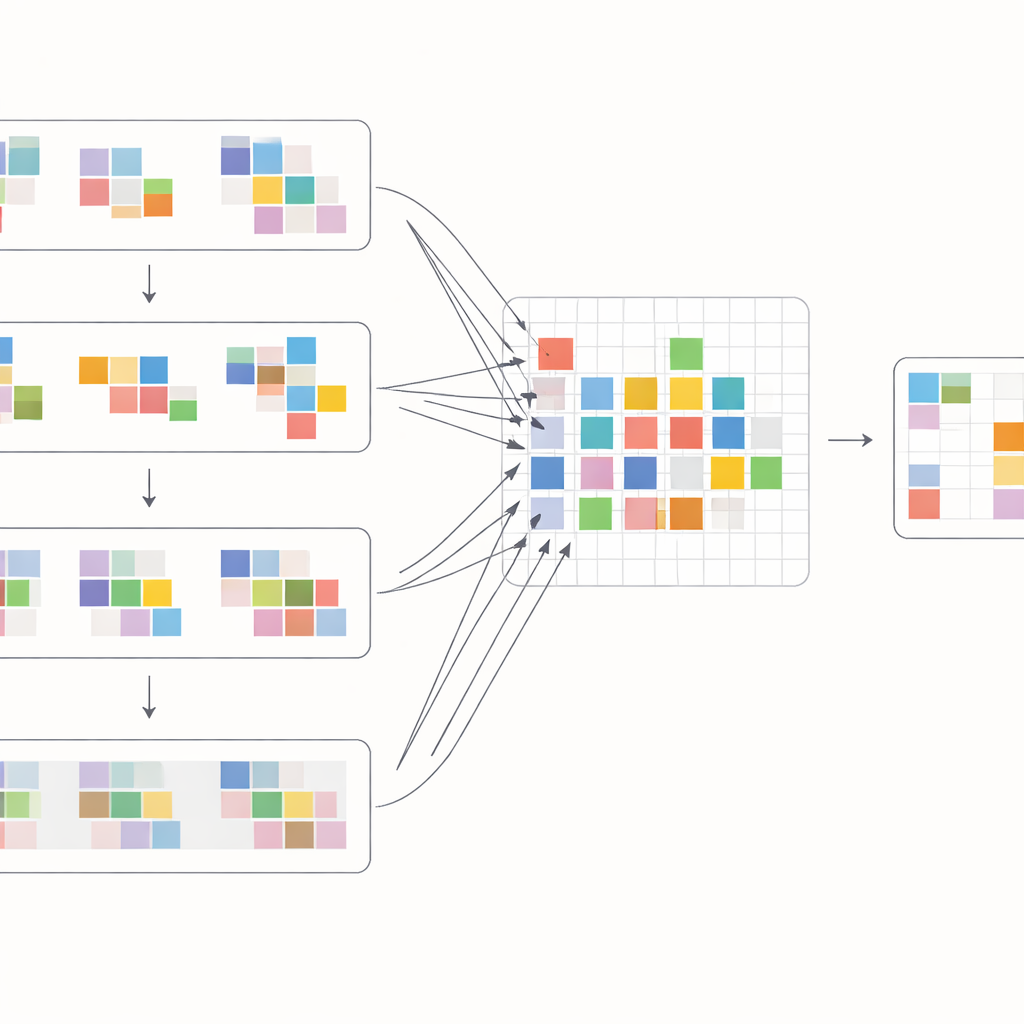
כמה זה טוב בפועל
החוקרים בוחנים את הגישה בשני קווים מאתגרים. הראשון כולל וידאו נקי שהושחת באופן מלאכותי ברמות שונות של רעש אקראי, מה שמאפשר מדידה מדויקת של הקרבה בין הפריימים המשוחזרים למקור. כאן, השיטה החדשה בתדירות גבוהה משווה או עולה על האיכות של רשתות קונבולוציה ורקורסיביות מוקדמות, ומתקרבת לשיא של מודלי טרנספורמר קיימים תוך שימוש בחישוב מופחת. הקו השני משתמש בצילומים אמיתיים שנתפסו מחיישני תמונה בתאורה חלשה, שבהם הרעש אינו אחיד, צבעוני ופחות צפוי. במבחן הריאלי הזה, ה-Shift Alignment Transformer מעניק ביצועים עדיפים בבירור על השיטות המתקדמות הקודמות, ומפיק וידאו שנראה נקי, חד ויציב יותר לאורך זמן, עם פחות תזוזות צבע ופחות ארטיפקטים שנותרים.
מה זה אומר לכלי וידאו עתידיים
במילים פשוטות, המחברים מראים שניתן לנקות וידאו ביעילות מבלי לעקוב במפורש אחרי תנועה, על ידי שילוב הזזות חכמות בזמן ובמרחב עם התאמת תכונות מבוססת תשומת לב. ה-Shift Alignment Transformer מציע איזון חזק בין דיוק ויעילות, במיוחד לצילומי תאורה חלשה בעולם האמיתי, שבה הערכת התנועה המסורתית רגישה ושברירית. ככל שמודלים מבוססי תשומת לב יהפכו ליעילים יותר, שיטות כמו זו עשויות להיכנס למצלמות יומיומיות ולשירותי סטרימינג, ולסייע להפוך צילומים רעשניים וקשים לצפייה לקטעי וידאו חלקים וחדים עם מינימום מאמץ מצד המשתמש.
ציטוט: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
מילות מפתח: ניקוי רעשים בווידאו, טרנספורמר, רעש בתמונה, ווידאו בתאורה חלשה, ראייה ממוחשבת