Clear Sky Science · he
גיזום יער עצים ודגימה מחדש לבעיה של חוסר איזון מחלקות
מדוע מקרים נדירים חשובים בחיזויים חכמים
הרבה החלטות שמונעות על ידי בינה מלאכותית תלויות בזיהוי האירוע הנדיר: חיוב כרטיס אשראי מזויף, סימן מוקדם למחלה או תקלה מסוכנת במכונה. במצבים אלה המקרים החשובים מועטים בהשוואה לאירועים השגרתיים, ולרוב האלגוריתמים הלימודיים נוטים להתעלם מהם. מאמר זה מציג דרך לגרום לשיטה פופולרית אחת, יערות אקראיים, להיות קשובה יותר לאותם מקרים נדירים אך קריטיים—ובמקביל להפוך את המודל לזריז וקל יותר.
בעיית הדוגמאות הלא שוות
למידת מכונה סטנדרטית עובדת הכי טוב כאשר הנתונים מאוזנים—כשמספר הדוגמאות לכל תוצאה דומה. במציאות, לעומת זאת, אירועים נדירים שולטים במשימות רבות. למשל, רק חלק קטן מסריקות רפואיות מציג גידול, ורק אחוז זעיר מהעסקאות הוא הונאה. חוסר האיזון הזה מאפשר לאלגוריתם להיראות טוב מבחינה סטטיסטית על ידי חיזוי רוב הזמן של התוצאה השכיחה, אפילו אם הוא מפספס שוב ושוב את הנדירה. ככל שהפער בין מקרים שכיחים לנדירים גדל, גבול ההחלטה של המודל נוטה לכיוון הרוב והכיתה הנדירה נעשית קשה יותר לזיהוי.
איזון המשקלות באמצעות דגימה חכמה
חוקרים לעתים קרובות מנסים לאזן מחדש את הנתונים לפני אימון המודלים. אפשרות אחת היא לקצץ את מחלקת הרוב (under-sampling), להשליך חלק מהמקרים השכיחים כדי להתאים למספר המקרים הנדירים. אפשרות שנייה היא לשכפל או לייצר דוגמאות נדירות נוספות (over-sampling), להגדיל את נוכחותן מבלי לאבד נתונים מקוריים. גישה שלישית, היברידית, משלבת בין שתי הרעיונות, חותכת חלק ממקרי הרוב ומגבירה את המיעוט. לכל טקטיקה יש תשלומים: הקיצוץ מסכן איבוד מידע שימושי, בעוד שכפול של דוגמאות יכול להאט את האימון ולגרום להתאמה מדי. המחברים משתמשים בכל שלוש האסטרטגיות ליצירת מערכי אימון מאוזנים יותר המותאמים לנתונים הקונקרטיים.
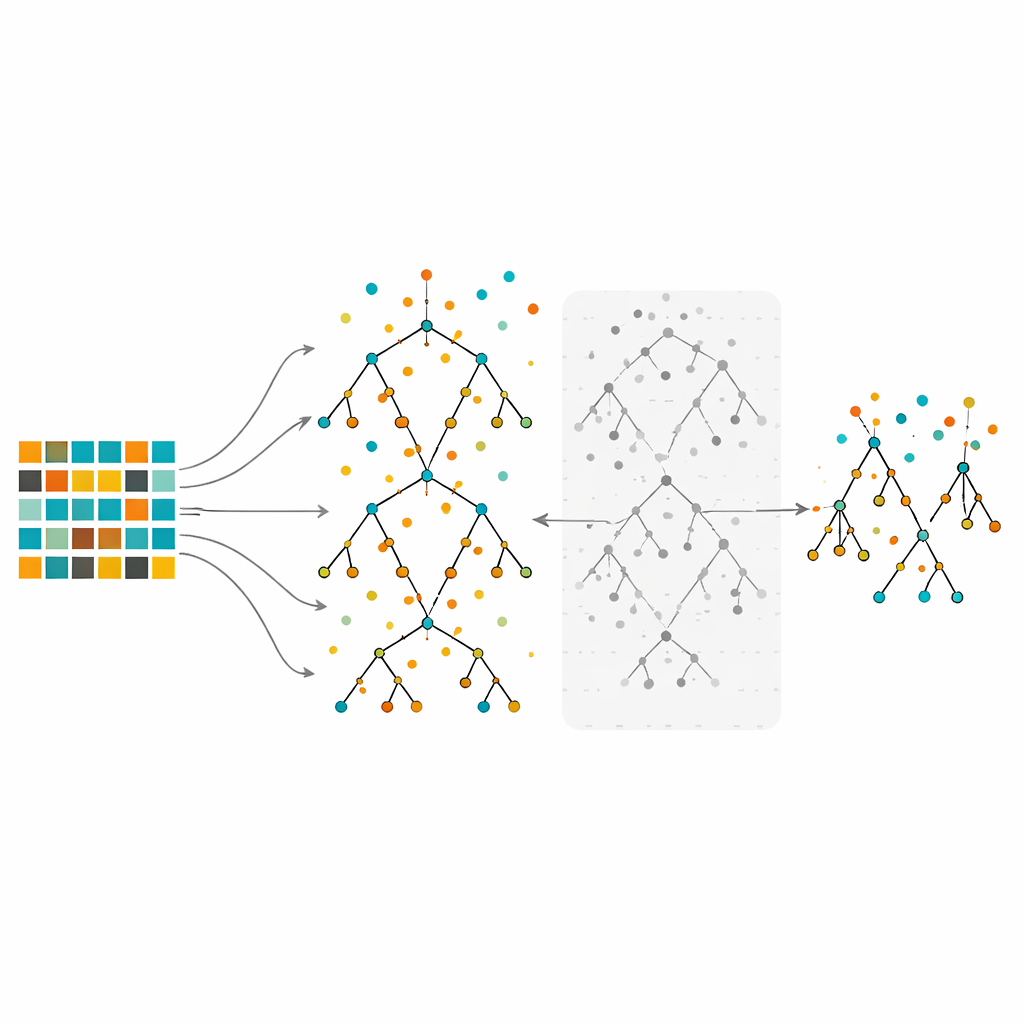
לימוד וגיזום יער של עצי החלטה
המחקר מתמקד ביערות אקראיים, שיטה אנסמבל שבונה עצי החלטה רבים על פרוסות נתונים מעט שונות ואז משלבת את קולותיהם. היערות האקראיים ידועים ביכולתם להתמודד עם נתונים מורכבים ולהבליט אילו תכונות חשובות. עם זאת, כאשר מאמינים על נתונים בעלי חוסר איזון חזק, גם יערות גדולים עלולים להיטה לטובת מחלקת הרוב. בשיטה המוצעת המחברים ראשית מייצבים את הנתונים באמצעות under-sampling, over-sampling או שיטה היברידית. לאחר מכן הם מגדלים הרבה עצים באמצעות נוהל ה-Random Forest הרגיל, אך עם טוויסט חשוב: במקום לשמר כל עץ, הם מעריכים כל עץ באמצעות תצפיות מחוץ-לשק (out-of-bag) — נקודות נתונים שלא שימשו לגדל את אותו עץ — ומוציאים מן היער את חצי העצים עם שיעורי השגיאה הגרועים ביותר. שלב הגיזום הזה מניב יער קטן וממוקד יותר שנבנה מן העצים האמינים ביותר.
בדיקות על מערכי נתונים ממגוון מצבים אמיתיים
כדי לבדוק עד כמה היער המגוזם מבצע היטב, המחברים בוחנים אותו על עשרה מערכי נתונים זמינים לציבור המשקפים טווח רחב של יישומים, ממדידות רפואיות וביולוגיות ועד סינון דואר זבל וסיווג צלילים. לכל מערך יש שתי מחלקות, כאשר אחת ברורה כנדירה יותר מהשנייה, והם משתנים בגודל, במספר התכונות ובמידת חוסר האיזון. השיטה החדשה משווה עם מספר גישות נפוצות: k-nearest neighbors, עץ החלטה יחיד, יער אקראי סטנדרטי, וריאנט Balanced Random Forest ותמכי וקטורים. על פני אסטרטגיות דגימה שונות היער המגוזם משיג בעקביות שגיאת סיווג נמוכה יותר מהרוב האלטרנטיבות ברוב מערכי הנתונים. השילוב של דגימה היברידית וגיזום נותן את התוצאות הטובות ביותר הכוללות דיוק ושליטה ביציבות הביצועים על פני כל עשר המשימות.
מודלים חדים יותר שמבזבזים פחות משאבים
מעבר לדיוק, הגישה משפרת גם את היעילות. על ידי חיתוך העצים הפחות אפקטיביים, האנסמבל הסופי קטן יותר ודורש פחות חישוב לאימון ולתחזית, מבלי להקריב—ולרוב אף משפר—את היכולת לזהות מקרים נדירים. מבחנים סטטיסטיים מאשרים שהשיפורים על פני שיטות מתחרות אינם מקריים. עבור פרקטיקנים המתמודדים עם נתונים לא מאוזנים, עבודה זו מראה כי איזון מדוד של מערך האימון ואחריו גיזום יער אקראי על בסיס ביצועי out-of-bag יכולים להניב מודלים מדויקים ויעילים יותר. במילים יום-יומיות, השיטה עוזרת לאלגוריתמים שלנו לשים לב כראוי לאותות הנדירים אך החשובים שמסתתרים בים של דוגמאות שגרתיות.
ציטוט: Faiz, N., Iftikhar, S., Jan, S. et al. Pruning tree forest and re-sampling for class imbalanced problem. Sci Rep 16, 8087 (2026). https://doi.org/10.1038/s41598-026-38320-1
מילות מפתח: חוסר איזון מחלקות, יער אקראי, דגימה מחדש, למידת מכונה, שיטות אנסמבל