Clear Sky Science · he
דקומפוזיציית טנזור ללא דרגה באמצעות למדידת מטריקה
מציאת דפוסים בים של נתונים
המדע המודרני טובע בנתונים מורכבים: ערימות של סריקות רפואיות, מפות פעילות מוחית, תמונות אסטרונומיות וסימולציות של חומרים. הבנת נתונים אלה לעתים קרובות מצריכה לכווץ אותם לצורות פשוטות יותר מבלי לאבד את מה שבאמת חשוב. מאמר זה מציג דרך חדשה לעשות זאת. במקום לנסות לשחזר נאמנה כל פיקסל, הוא מתמקד בלכידת הקשרים האמיתיים בין הדגימות – איזה מוח דומה לאיזה, אילו גלקסיות מצויות בקירבה זו לזו – כך שמפת הנתונים המתקבלת משקפת משמעות ולא פרטיות גולמיות.
משחזור תמונות למדידת דמיון
כלים מסורתיים לפישוט נתונים רב־ממדיים, הידועים כדקומפוזיציות טנזור, פועלים קצת כמו פירוק אקורד לתווים. הם מפרקים "בלוק" נתונים למספר קטן של תבניות בסיסיות בתוספת משקלים. כדי לעשות זאת חייבים לציין מראש כמה תבניות — ה"דרגה" — מותרים, והם שופטים הצלחה לפי עד כמה הנתונים המקוריים ניתנים לשחזור. זה אידיאלי לדחיסה או הפחתת רעש, אך לא בהכרח למשימות כמו "האם שני פרצופים שייכים לאותה אישיות?" או "האם סריקת מוח זו שייכת לנבדק עם אוטיזם או לנבדק טיפוסי?" שבהן קיבוץ נכון חשוב יותר משחזור מושלם.
במקביל, למידת עומק הפופולריזציה רעיון אחר: במקום לפרק טנזור באופן אלגברי, לומדים קוד מספרי קומפקטי, או אמבדינג, באמצעות רשת עצבית. אוטואנקודרים קלאסיים עדיין מתמקדים בשחזור. עבודה זו הופכת את המטרה: היא מציעה מסגרת "ללא דרגה" שאינה קובעת דרגה מראש ואינה דואגת לשחזור מדויק של פיקסלים. במקום זאת היא לומדת מדד מרחק כך שנקודות שצריכות להיות קרובות (אותו אדם, אותו אבחון, אותה קבוצה פיזיקלית) יסתיימו שכנות בחלל האמבדינג, ונקודות שצריכות להיות שונות יידחקו זו מזו.
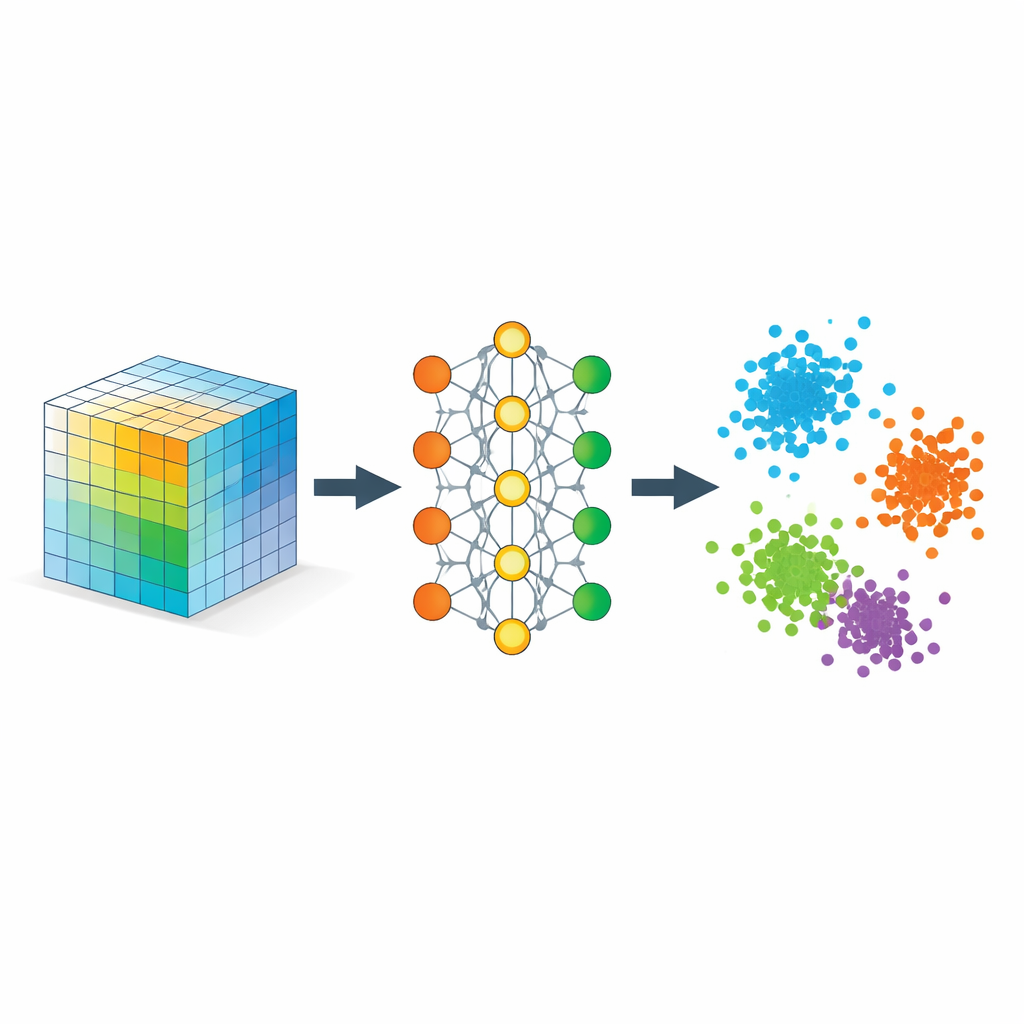
לימוד הרשת מה פירוש "קרוב"
מרכיב המפתח הוא אסטרטגיה הנקראת למידת מטריקה, שממומשת כאן באמצעות טריפלטים של דוגמאות: דגימת עוגן, דגימת חיובית מאותו סוג ודגימת שלילית מסוג שונה. במהלך האימון הרשת מתוגמלת כשהעוגן קרוב יותר לחיובית מאשר לשלילית בהפרש שוליים בטוח. לאורך טריפלטים רבים הכלל הפשוט הזה מעצב את חלל האמבדינג כך שמרחקים ישקפו דמיון סמנטי במקום דמיון פיקסלי גולמי. רגולריזרים נוספים מעודדים את הרשת לפזר מידע בצורה שווה על פני הממדים, להימנע מקריסה של הכל לקו אחד ולשמור על שכנויות מקומיות באופן גס, כך שנקודות קרובות בנתונים המקוריים יישארו קרובות אחרי ההטמעה.
מתמטית, המחברים מראים כי אמבדינג זה מתנהג כמו דקומפוזיציית טנזור גמישה, אך ללא דרגה קבועה מראש. הקואורדינטות שנלמדו ניתנות לפרשנות כגורמים בדקומפוזיציה קלאסית של טנזור דמיון שהכניסות שלו מודדות עד כמה חלקים שונים בנתונים מתיישבים. כי המודל מעניש כיוונים מיותרים, הוא נוטה להשתמש בכל ממדי האמבדינג ביעילות, ונותן לנתונים עצמם לקבוע כמה רכיבים משמעותיים נדרשים. יחד עם זאת הם מספקים הבטחות תיאורטיות שההליכי אימון סטנדרטיים מיטביים ושהגאומטריה המתקבלת מפרידה באופן נאמן בין מחלקות מבלי לעוות בחוסר פרופורציה קשרים מקומיים בעלי משמעות.
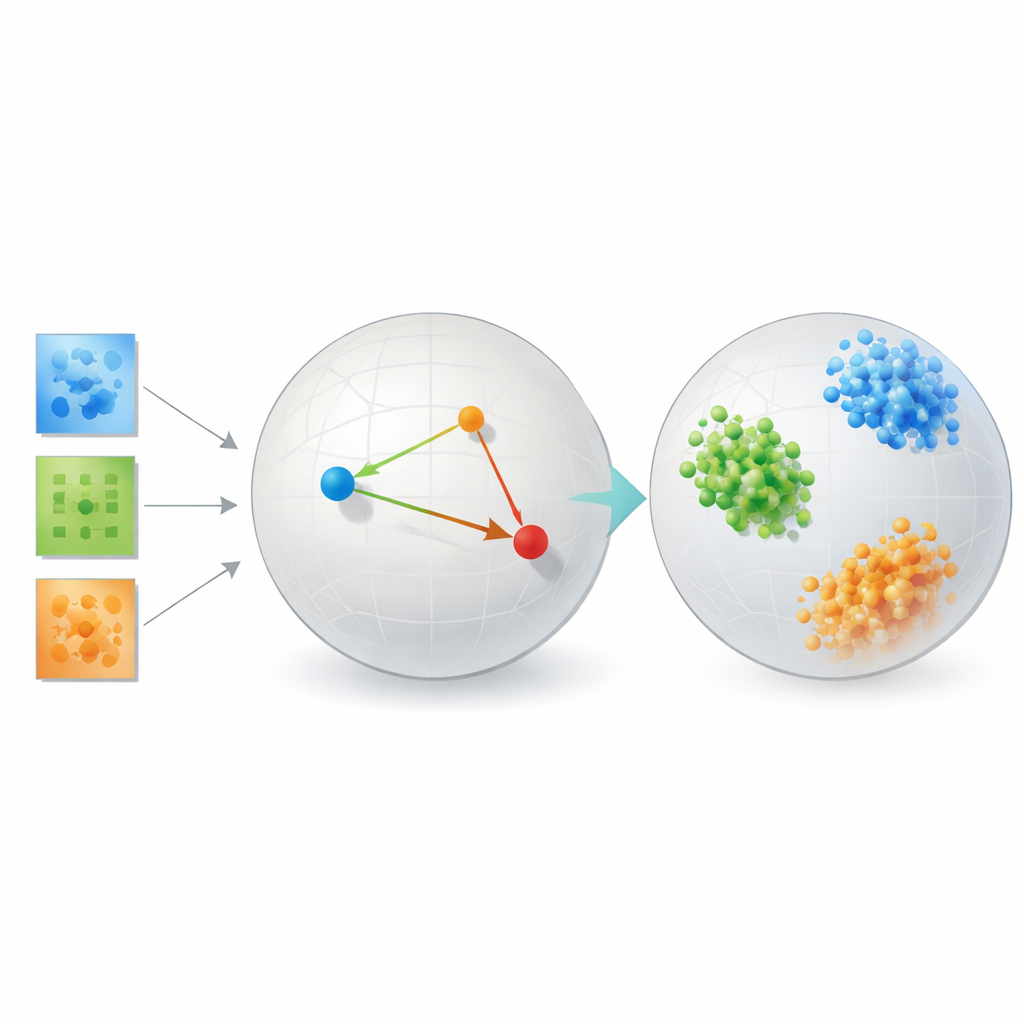
בדיקת המתודה במבחן
כדי להראות שהשיטה אינה רק תיאוריה אלגנטית, המחבר בודק אותה על מספר בעיות שונות מאוד. במבחנים של זיהוי פנים, האמבדינגים הנלמדים מקבצים תמונות של אותו אדם לצברים צמודים ומובחנים היטב, ועושים זאת באופן משמעותי טוב יותר משיטות קלאסיות כגון מרכיבים עיקריים, כלי ויזואליזציה פופולריים כמו t-SNE ו‑UMAP, ודקומפוזיציות טנזור מסורתיות התלויות בדרגות קבועות. בנתוני קישוריות מוחית של אנשים עם וללא אוטיזם, השיטה מגלה מרחב שבו שתי הקבוצות מופרדות בצורה ברורה יותר מאשר עם כלי טנזור ממוקדי־שחזור או רשתות אוטואנקודר, מרמזת שהיא חודרת לדפוסים בעלי חשיבות קלינית באופן פעיל בקשרים בין אזורי המוח.
המחקר כולל גם סימולציות מבוקרות של צורות גלקסיות ומבני גביש, שבהן הקטגוריות "האמיתיות" ידועות בדיוק. כאן מסגרת למידת המטריקה מקבצת כמעט ללא שגיאות את הגלקסיות והגבישים הסינתטיים לפי הסוגים הפיזיקליים הבסיסיים שלהם. בכל המתרחשין הללו השיטה באופן עקבי מסחרת קצת מנאמנות למרחב הפיקסלים המקורי עבור ייצוג שבו דמיון ושונות מתיישרים עם משמעות מדעית. באופן חשוב, היא עושה זאת ללא כמויות אדירות של נתונים ומשאבי חישוב שלגביהם נדרשים לרוב מודלים מבוססי טרנספורמר, אשר התקשו במערכי נתונים מדעיים אליהם יחסית קטנים.
מדוע זה חשוב לעתיד הנתונים המדעיים
למדענים המחפשים דפוסים בנתונים מועטים ובעלי מימד גבוה, עבודה זו מציעה שינוי פרספקטיבה מעניין. במקום לנחש דרגה ולאופטם לשחזור, ניתן לבקש ישירות אמבדינג שמשקף את הקשרים שחשובים: אותו אבחון, אותה פאזה של חומר, אותה קטגוריה אסטרופיזיקלית. מסגרת למידת המטריקה ללא דרגה המוצעת מראה כי אמבדינגים כאלה יכולים להיות גם פרשניים וגם רבי־עוצמה, במיוחד כאשר הנתונים נדירים. כפי שהמחבר מציין, עדיין קיימות אתגרים — כולל התמודדות עם חוסר איזון במחלקות וקנה מידה למספר רב של קטגוריות — אך המסר ברור: ברבים מבעיות המדע, ללמוד מושג טוב של דמיון עשוי להיות בעל ערך רב יותר משחזור כל פרט באות המקורית.
ציטוט: Bagherian, M. No-rank tensor decomposition via metric learning. Sci Rep 16, 8326 (2026). https://doi.org/10.1038/s41598-026-38221-3
מילות מפתח: למידת מטריקה, דקומפוזיציית טנזור, למידת ייצוג, הפחתת מימדים, ניתוח נתונים מדעיים