Clear Sky Science · he
מודל צימוד רשת מונחה VLM למידול הדרדרות למיזוג תמונות אינפרא-אדום ונראות
ראיית לילה חדה יותר לעולם רועש
מצלמות מודרניות רואות בחושך, מזהות חום ומשגיחות על הכביש — אבל התמונות שלהן לעיתים רחוקות מושלמות. מנורות רחוב זוהרות, צללים בולעים פרטים וחיישנים מוסיפים רעש מחולק. המחקר הנוכחי מציג דרך חדשה למזג וידאו צבעוני רגיל עם תמונות אינפרא-אדום חושות חום כך שהתוצאה תהיה ברורה ואמינה יותר, גם כאשר שני המידע הנכנסים מוסתים בצורה קשה. השיטה תוכל להפוך מכוניות אוטונומיות, מערכות תצפית ומצלמות חכמות אחרות לאמינות יותר בתנאים בהם אנחנו זקוקים להן הכי הרבה: בלילה, במזג אוויר קשה ובסצנות מורכבות מהעולם האמיתי.
למה שתי עיניים טובות יותר מאחת
מצלמות אור נראה תופסות את הצבעים והמרקמים העשירים שאנשים רגילים לראות, אך מתקשות בתאורה חלשה, סנוורים וצללים כבדים. מצלמות אינפרא-אדום, לעומת זאת, מרגישות חום ויכולות להבחין בקלות בחפצים חמים כגון אנשים או כלי רכב בחשכה, אף שהתמונות שלהן נראות לעתים שטוחות וחסרות פרטים דקיקים. מיזוג תמונות אינפרא-אדום ונראות שואף לשלב את הטוב משני העולמות: קווי מתאר חדים של מטרות חמות מהאינפרא-אדום עם פרטי רקע והצבעים מאור נראה. עם זאת, באופן מסורתי רוב שיטות המיזוג מניחות ששתי התמונות הנכנסות כבר נקיות ובאיכות גבוהה — הנחה שאינה מתאימה לרחובות, ערים ואתרי תעשייה שבהם טשטוש, רעש, תאורה חלשה ותאורה מוארת יתר הם הנורמה ולא החריג.
כאשר קדם-עיבוד אינו מספיק
מנסרות קיימות מטפלות בתמונות פגומות בדרך כלל בשני שלבים מנותקים. ראשית, כלי שיפור נפרדים מבהירים סצנות חשוכות, מצמצמים רעש או מתקנים ניגודיות. רק לאחר מכן רשת מיזוג משלבת את התמונות המשופרות. גישה זו בת שני שלבים סובלת ממספר חסרונות. היא מחייבת מהנדסים לבחור ולכוון כלי שיפור שונים עבור כל סוג פגם וכל חיישן, מה שהופך את תהליך העבודה לשברירי ומורכב. חשוב לא פחות, כל מידע שאבד או עוות במהלך הניקוי הנפרד לא יוכל להתאושש בשלב המיזוג. מחקרים אחרונים הציגו רשתות מיוחדות המותאמות לסוג אחד של הדרדרות או השתמשו במודלים מונחי שפה כדי לטפל במודאליות פגומה אחת בכל פעם. עם זאת, כאשר גם תמונות האינפרא-אדום וגם תמונות הנראות נפגמות — ולעתים באופן שונה — אסטרטגיות אלו עדיין תלויות בקדם-עיבוד ידני ומתקשות להתמודד עם תנאים מעורבים מהעולם האמיתי.
רשת מיזוג שמבינה הדרדרות
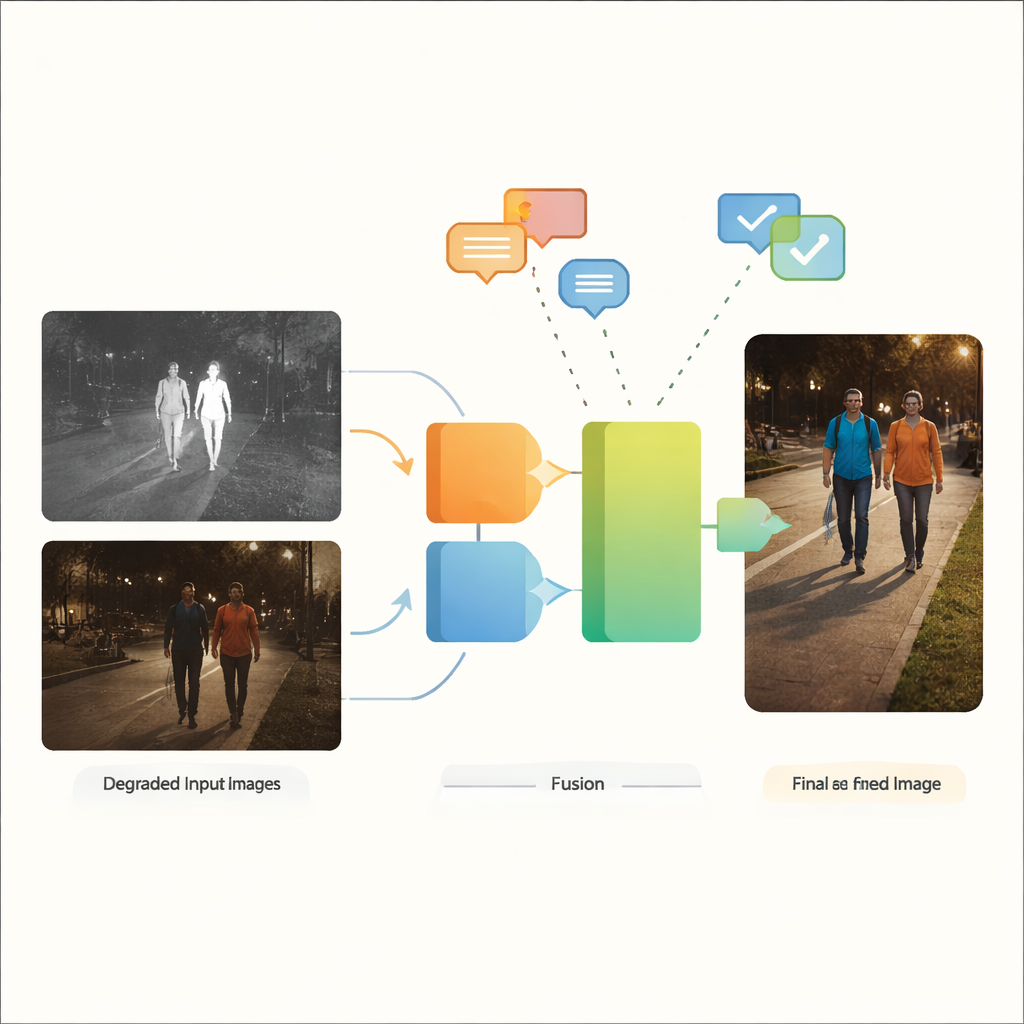
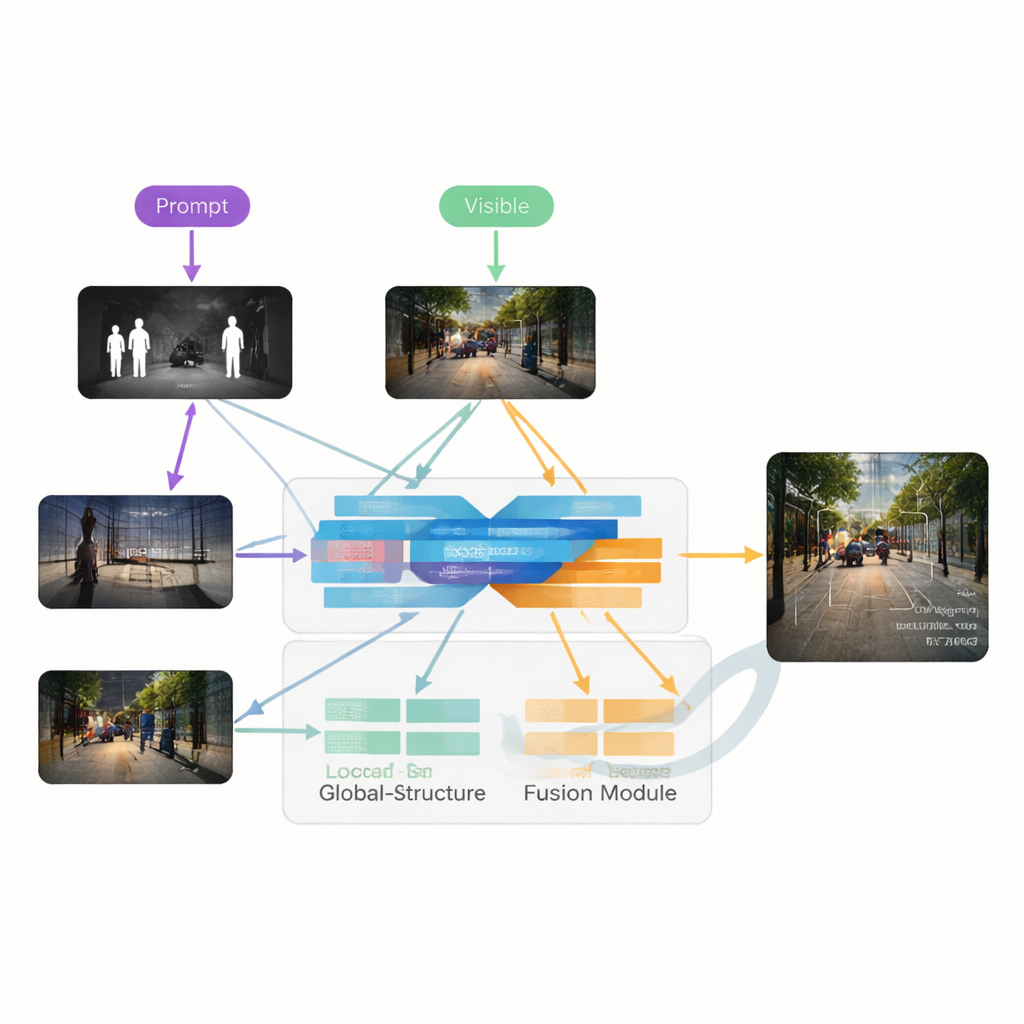
המחברים מציעים את VGDCFusion, מסגרת למידה עמוקה חדשה ששוזרת טיפול בהדרדרות ישירות לתוך תהליך המיזוג. הרעיון המרכזי הוא לאפשר לרשת לדעת במילים אילו בעיות לצפות, ואז להשתמש בידע הזה בכל שלב של חילוץ ותיאום תכונות. קטעי טקסט קצרים מתארים את המשימה (מיזוג אינפרא-אדום ונראות) ואת הבעיות הספציפיות הקיימות, כגון תאורה חלשה, הצפת תמונה, ניגודיות נמוכה או רעש. מודל רב-עוצמתי של ראייה–שפה — בדומה לרוחב מערכות כמו CLIP — הופך את ההנחיות הללו לתיאורים מספריים דחוסים. תיאורים אלה מנחים שני רכיבים מרכזיים: ה-Specific-Prompt Degradation-Coupled Extractor (SPDCE), הפועל בנפרד על כל מודאליות, ו-Joint-Prompt Degradation-Coupled Fusion (JPDCF), שממזג מידע בין המודאליות תוך שמירה על תשומת לב לסוג ההדרדרות שנותרה.
איך פועל תהליך המיזוג המונחה
בתוך כל מודול SPDCE, ההנחיה המופקת מההנחיה הטקסטואלית מנווטת את הרשת לעבר תכונות חשובות ולהתרחק מתופעות לוואי. שכבות קונבולוציה רב-סקלריות מסתכלות על שכנות קטנות כדי לשמר קצוות ומרקמים, בעוד ששכבות טרנספורמר לוכדות מבנה וקונטקסט בקנה מידה גדול יותר. יחד הן לומדות להדגיש, למשל, חתימות חום חשובות במסגרת אינפרא-אדום רועשת או סימוני נתיב חלשים בתמונה נראית חשוכה, תוך דיכוי רעש חיישן ופגמי תאורה. במקביל, מודולי JPDCF לוקחים את התכונות המתוקנות משני הענפים ומשלבים אותן, שוב תחת הנחיה טקסטואלית. הם משתמשים בתשומת לב מרחבית ובתשומת לב ערוצית כדי להבליט אזורים אינפורמטיביים, לסנן הדרדרות שנותרה ולחבר רמזים משלימים — כמו יישור קווי מתאר בהירים מאינפרא-אדום של הולך רגל עם הצבע ומבנה הרקע מהמצלמה הנראית — לפני בנייה מחדש של תמונת פלט ממוזגת בת שלוש ערוצי צבע.
בדיקת השיטה במבחן
כדי להדגים את היעילות, הצוות העריך את VGDCFusion על מספר מערכי נתונים ציבוריים הכוללים תמונות נראות בתאורה נמוכה ובהצפה כמו גם תמונות אינפרא-אדום רועשות או בעלות ניגודיות נמוכה. הם השוו את שיטתם למגוון טכניקות מיזוג חדשות, כולל אוטואנקודרים, רשתות קונבולוציה, רשתות נגד גנרטיביות וטרנספורמרים. באמצעות מדדי איכות תמונה סטנדרטיים, VGDCFusion הפיק בעקביות תמונות ממוזגות עם קצוות חדים יותר, ניגודיות טובה יותר וצבעים טבעיים יותר, גם כאשר לשיטות המתחרות ניתנה יתרון של קדם-עיבוד מכוּון בקפידה. הגישה החדשה שיפרה מדדים מרכזיים בכ-15% בממוצע בתרחישים של הדרדרות כבדה. כאשר התמונות הממוזגות הוזנו למערכת זיהוי עצמים פופולרית, זה גם הוביל לדיוק זיהוי גבוה יותר מאשר שימוש באינפרא-אדום או בנראות בנפרד, או משימוש ברשתות מיזוג אחרות.
ראייה בהירה יותר למערכות בטוחות יותר
במילים פשוטות, עבודה זו מראה שאם מודיעים לרשת מיזוג תמונות אילו בעיות ויזואליות לצפות — ומאפשרים לה לתקן ולמזג בשלב אחד מחובר היטב — אפשר להשיג תמונות נקיות ואינפורמטיביות יותר מאשר בטיפול נפרד בשיפור ובמיזוג. על ידי צימוד מידול ההדרדרות לתהליך המיזוג ושימוש ברמזים מונחי שפה בכל שכבה, VGDCFusion יכולה להסתגל לצורות שונות ומעורבות של השחתת תמונה ללא כוונון ידני מתמיד. סוג מיזוג חכם ומודע להדרדרות זה יכול לסייע למערכות ראייה עתידיות, מהרכבים אוטונומיים ועד מצלמות אבטחה, לראות באופן אמין יותר בתנאים מבולגנים ולא מושלמים של העולם האמיתי.
ציטוט: Zhao, J., Zhang, T. & Cui, G. A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion. Sci Rep 16, 8249 (2026). https://doi.org/10.1038/s41598-026-38181-8
מילות מפתח: מיזוג אינפרא-אדום ונראות, צילום בתאורה נמוכה, מודלי ראייה-שפה, השחתת תמונה, תפיסת נהיגה אוטונומית