Clear Sky Science · he
תיקון תוויות רועשות באמצעות זיקוק השוואתי: גישת התאמת תחום
מדוע נתונים מבולגנים הופכים לבעיה גוברת
מערכות בינה מלאכותית מודרניות תלויות בנתונים, אך לעתים קרובות נתונים אלה שגויים, לא-complete או מתויגים באופן בלתי עקבי. כאשר התוויות רועשות — למשל תמונה של חתול המסומנת ככלב — מערכות הלמידה יכולות להתבלבל, להפוך לפחות מדויקות ופחות אמינות. מאמר זה מתמודד עם הבעיה המעשי: איך לאמן מערכות לזיהוי תמונות שעובדות היטב גם כאשר תוויות האימון פגומות והתמונות מגיעות מסביבות שונות, כמו חנויות מקוונות לעומת צילומים מהעולם האמיתי.
למידה בין עולמות שונים
בעשייה המעשית, דגמי AI לעתים קרובות לומדים מעולם "מקור" שבו התוויות נבדקות בקפידה, ואז צריכים לפעול בעולמָּה "יעד" שבה התוויות נדירות ונתונות לשגיאות. לדוגמה, חפצים משרדים שצולמו בסטודיו הם מסודרים ומתויגים נכון, בעוד תמונות מצלמת רשת או תמונות יומיומיות של אותם חפצים הן מבולגנות ומתויגות באופן בלתי עקבי. שיטות התמתנות תחום מסורתיות מנסות לגשר על הפער הזה על ידי יישור הסטטיסטיקות הכוללות של שני העולמות. עם זאת, הן לרוב מניחות שהתוויות בעולם היעד, כשהן זמינות, נכונות — הנחה מסוכנת שמתפרקת ביישומים אמיתיים עם תגים שמקורם בציבור הרחב, חיישנים באיכות נמוכה או כלים לאנוטציה אוטומטית.
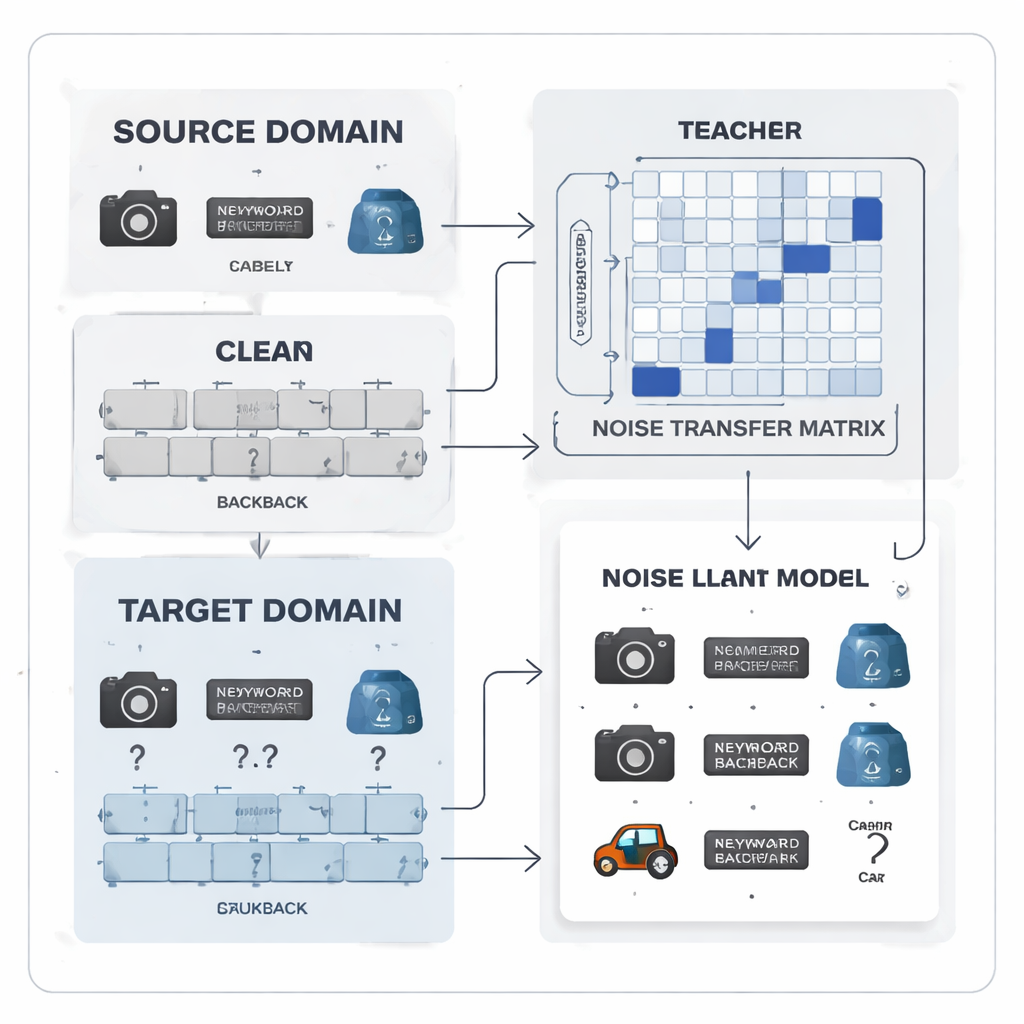
להפוך שגיאות תיוג לדפוס שניתן ללמוד ממנו
המחברים מציעים לטפל ברעש בתוויות לא ככאוס אקראי אלא כדפוס שניתן ללמוד. הם מציגים "מטריצת העברת רעש", טבלה שתופסת כמה סביר שכל מחלקה אמיתית תוכחש כמחלקה אחרת. במקום להעריך טבלה זו מתוך כמה דוגמאות עוגן מושלמות — שלא מציאותי כאשר התוויות רועשות והכיתות בלתי מאוזנות — המטריצה נלמדת ישירות במהלך האימון. כדי להניע את הלמידה, השיטה בונה "פרוטוטיפים" לכל קטגוריה, טביעות אצבע ממוצעות של תכונות לכל כיתה המופקות על‑ידי מודל חזק שאומן מראש. הדמיון בין הפרוטוטיפים משמש לאתחול המטריצה כך שקטגוריות הניתנות לבלבול, כמו כלי משרד דומים, יקושרו חזק יותר מההתחלה, מה שמעניק למערכת יכולת מוקדמת לתקן תוויות.
עבודת צוות של מורה–תלמיד לאותות נקיים יותר
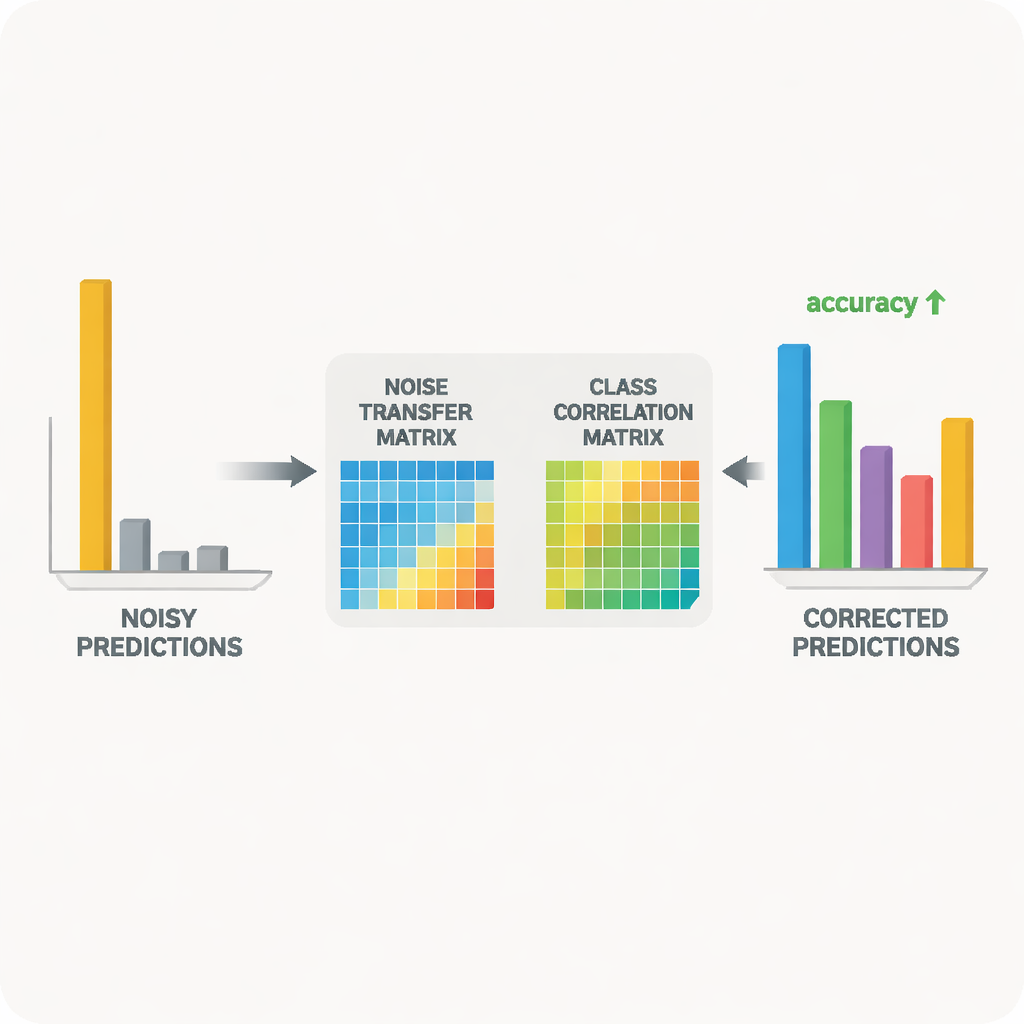
בלב המערכת עומדת זוג רשתות נוירוניות של מורה ותלמיד. המורה מבוסס על מודל ראייה גדול שלמד תכונות חזותיות עשירות מלמידה עצמי על כמות עצומה של נתונים לא מתוייגים. התלמיד הוא רשת קלה יותר שחייבת לתפקד היטב על נתוני היעד הרועשים. המורה מייצר ציוני תחזית רכים שחשיפת איך קטגוריות קשורות זו לזו; מתוך ציונים אלה השיטה בונה מטריצת קורלציה של כיתות שמסכמת אילו תוויות נוטות להתרחש יחד. מטריצה זו משמשת כמדריך, דוחפת את מטריצת העברת הרעש לכיוונים של תיקונים ריאליסטיים יותר. באותו הזמן, התלמיד מאומן להתאים את התנהגות המורה בתהליך הידוע כזיקוק (distillation), בעוד שלמידה ניגודית מעודדת את שתי הרשתות להפיק ייצוגים פנימיים דומים עבור מבטים משופרים שונים של אותה תמונה וייצוגים מובחנים לאובייקטים שונים.
שימור היציבות של התיקונים והימנעות מעודף ביטחון
איפשור חופשי של מטריצת העברת הרעש עלול להפוך אותה לבלתי יציבה או רגישה מדי לערכים חריגים. כדי למנוע זאת, המחברים משתמשים טריק מתמטי המבוסס על פירוק ערכים סינגולריים, שמפרק את המטריצה לכיווני מתיחה בסיסיים. על‑ידי הענשת "הנפח" הכולל שמרמזים הכיוונים הללו, השיטה מדכאת עיוותים קיצוניים שהיו מגדילים את הרעש. בעיה נוספת נוצרת כאשר המודל נעשה בטוח מדי בעצמו, ומקצה כמעט את כל ההסתברות למחלקה אחת; תחת תחזיות חדות כאלה קשה לתקן תוויות שגויות. כדי להתמודד עם זה, השיטה מוסיפה צורה של רגולריזציה של אנטרופיה, המבוססת על אנטרופיית צ'אסלס (Tsallis), ששומרת על הסתברויות הניבוי חלקות יותר. כך קל יותר למטריצת העברת הרעש להעביר חלק מהמסה ההסתברותית ממחלקה שגויה לאלטרנטיבות סבירות יותר.
הוכחת הרעיון על אוספי תמונות אמיתיים
החוקרים בדקו את הגישה שלהם על שני בוחנים נפוצים להכרה חוצת‑תחומים של עצמים: Office‑31 ו‑Office‑Home, הכוללים תמונות של פריטים משרדיים יומיומיים בסגנונות שונים כגון תמונות מוצר, איורי קליפ‑ארט וצילומי העולם האמיתי. במשימות של "לאמן על סגנון אחד, לבדוק על אחר" השיטה שלהם השיגה ביצועים שוות או עליונות על פני האלגוריתמים המובילים, במיוחד במקרים הקשים ביותר שבהם ההעתקה בין התחומים גדולה ביותר. מחקרים מפורטים הראו שכל רכיב — שליטת הנפח על מטריצת הרעש, ההדרכה על ידי קורלציות הכיתות והחליקה על האנטרופיה — תרם שיפורים נמדדים. ויזואליזציות של המטריצה הנלמדת ושל מרחב התכונות אישרו שבעקבות האימון דוגמאות מתויגות שגוי נמשכו בהדרגה לכיוונים הנכונים וכי התפלגויות התמונות של מקור והיעד התיישרו טוב יותר.
מה משמעות הדבר עבור מערכות AI ביום‑יום
לעיני הקורא הלא‑מומחה, המסקנה המרכזית היא שעבודה זו הופכת דגמי AI לסלחניים יותר כלפי טעויות אנושיות ומכאניות בתיוג נתונים, במיוחד כאשר דגמים אלה צריכים לעבור מתנאי מעבדה נקיים לסביבות העולם האמיתי המבולגנות יותר. על‑ידי למידה מפורשת של האופן שבו תוויות נוטות להסתבך ושימוש במודל מורה חזק להנחות תיקונים, השיטה יכולה לנקות אותות אימון רועשים ולהניב מסווגים מדויקים וחסינים יותר. למרות שהגישה דורשת חישוב נוסף, היא מצביעה על עתיד שבו מאגרי נתונים גדולים ולא מושלמים הנאספים "ברחבי הטבע" יכולים להיות מנוצלים באופן בטוח ויעיל יותר, מה שמפחית את התלות באנוטציה ידנית מייגעת.
ציטוט: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
מילות מפתח: תוויות רועשות, התאמת תחום, זיקוק ידע, סיווג תמונות, למידה חצי‑מנוטרת