Clear Sky Science · he
ביקורתניים התפלגותיים תאומים רגישי-סיכון עם גבול סמכות נמוך–למברדה לבקרה רציפה בחיזוק למידה
מלמדים רובוטים זהירות
רבים מהרובוטים והתוכניות המשחקיים המרשימים של היום נשענים על למידת חיזוק, תהליך אימון מבוסס ניסיון וטעייה שבו סוכנים תוכנתיים לומדים על ידי איסוף תגמולים. אך סוכנים אלה לעיתים רודפים אחרי ניקוד מקסימלי תוך התעלמות מסיכון ההחלטות שלהם, דבר שמוביל ללמידה לא יציבה ולפעמים לתקלות. מאמר זה מציג שיטה בשם TDC-λ (ביקורתנים התפלגותיים תאומים עם גבול סמכות נמוך לפי λ) שלומדת לסוכנים לא רק לשאוף גבוה אלא גם לשמור על בטיחות מהימנה בזמן הלמידה.
מדוע יציבות חשובה במכונות לומדות
אלגוריתמים סטנדרטיים לבקרה רציפה, כגון TD3 ו-Soft Actor–Critic (SAC) הנפוצים, איפשרו לרובוטים לרוץ, לקפוץ ולשמור על שיווי משקל בסימולטורים מורכבים. עם זאת, שיטות אלה בדרך כלל מעריכות כל פעולה באמצעות מספר יחיד: אומדן של כמה תגמול היא תביא בטווח הארוך. ציון פשוט זה יכול להטעות כאשר תהליך הלמידה רעשני, מה שעלול להוביל להערכת יתר של פעולות מסוימות. התוצאה היא עקומת למידה שנראית טובה בממוצע אך תנודותיה חזקות מריצה לריצה, מצב בעייתי אם אותו אלגוריתם אמור לשלוט במכונות פיזיות או מערכות קריטיות לבטיחות.
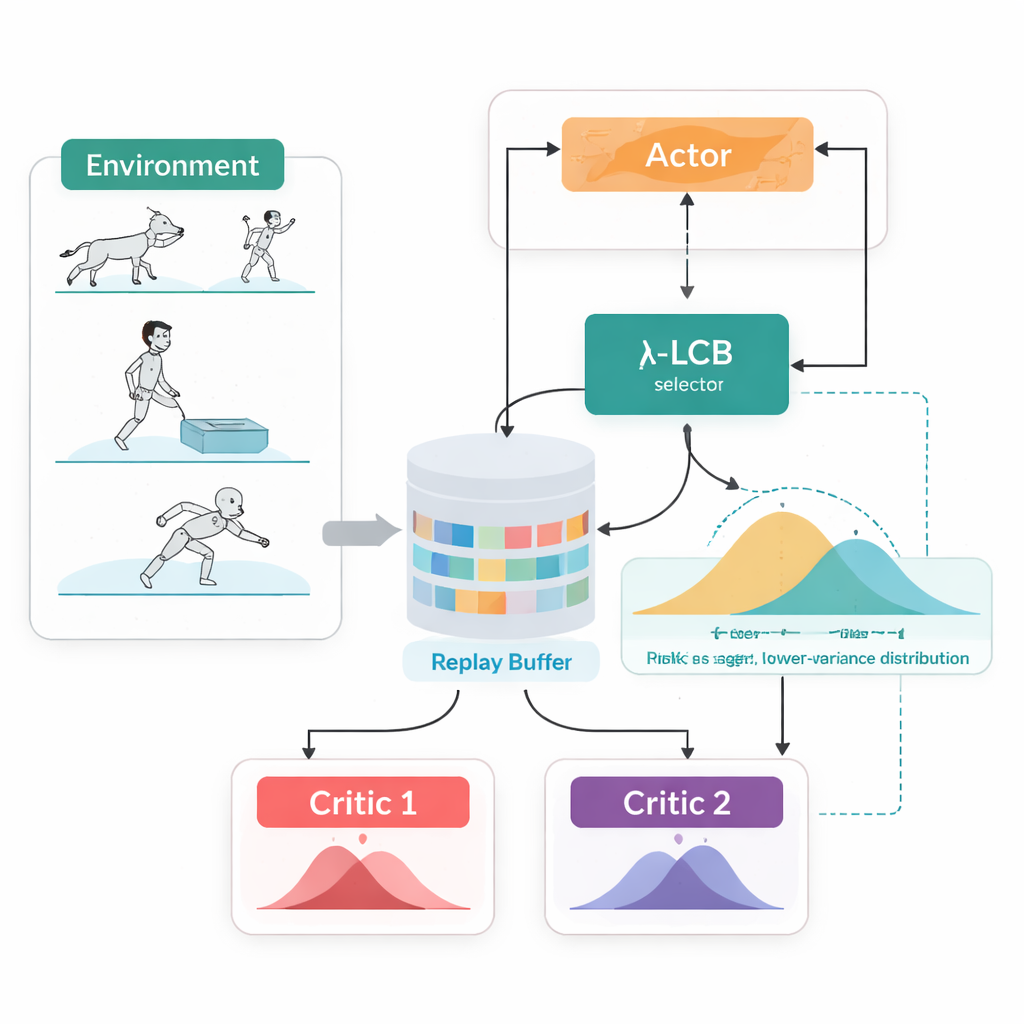
מסתכלים על העתיד הכולל, לא על מספר יחיד
TDC-λ פותר בעיה זו על ידי שינוי האופן שבו הסוכן מעריך את עתידו. במקום לחזות רק תשואה צפויה אחת עבור כל פעולה, הוא לומד שני "ביקורתנים" נפרדים שכל אחד מהם מחזיר התפלגות מלאה של תשואות אפשריות בעתיד. מתוך התפלגויות אלה, האלגוריתם מחשב לא רק את התוצאה הממוצעת אלא גם עד כמה האפשרויות מפוזרות. הפיזור הזה משקף אי-ודאות או סיכון. באמצעות כלל פשוט המסוכם כגבול סמכות נמוך, TDC-λ מעדיף את הביקורתן שחוזה תוצאה בטוחה יותר: אחד שעשוי להיות מעט פחות אופטימי אך מגובה בראיות עקביות יותר. הגדרה אחת, הפרמטר של סיכון λ, מכוונת בצורה חלקה עד כמה הבחירה תהיה זהירה — מתנהגות בדומה לשיטת TD3 קונבנציונלית כאשר λ שווה לאפס ועד להיענות שמרנית יותר ככל ש-λ גדל.
לולאת אימון אחת, שתי דרכים לפעול
תכונה מעשית נוספת של TDC-λ היא שהיא תומכת גם בבחירה דטרמיניסטית וגם בבחירה סטוכסטית של פעולות במסגרת מאוחדת אחת. במהלך האימון המשתמשים יכולים לבחור במדיניות דטרמיניסטית קלאסית או במדיניות גאוסיאנית מכווצת-tanh שמדגמנת פעולות ובכך מקדמת חקר. ללא קשר לבחירה זו, שני הביקורתנים ההתפלגותיים התאומים נלמדים באותה הדרך, וההערכה תמיד משתמשת בפעולה הממוצעת הדטרמיניסטית. עיצוב זה מנצל ממצאים קודמים שמראים שהתנהגות דטרמיניסטית בזמן בדיקה לעיתים קרובות מתפקדת לא פחות טוב ואף טוב יותר מהדגימה, בעוד שהוא מאפשר מדיניות עשירה וידידותית לחקר בזמן הלמידה.
מעמידים את השיטה למבחן
המחברים העריכו את TDC-λ על חמש משימות תקן נפוצות ב-MuJoCo שבהן רובוטים מדומים כגון HalfCheetah, Hopper, Ant, Walker2d ו-Humanoid צריכים ללמוד לנוע ביעילות. במשימות אלה, השיטה החדשה השוותה או שיפרה את ביצועי הסיום של קווים בסיס חזקים כולל TD3, DDPG, SAC וגישה מתקדמת מבוססת זרימה הנקראת MEOW, תוך שהיא מציגה בקלות פחות שונות בין הרצות. במשימות קשות יותר ומממדיות גבוהות כמו Humanoid, ערכי λ מעט גבוהים יותר — כלומר הערכות יעד זהירות יותר — הובילו לתשואות ארוכות טווח הטובות ביותר ולרצועות ביצועים הצרות ביותר. ניסויים נוספים בסימולטורים אחרים (PyBullet ו-NVIDIA Isaac) ואבחונים שעוקבים אחרי שונות אות הלמידה חיזקו את הממצא ש-TDC-λ מייצרת למידה יציבה יותר מבלי להאט אותה.
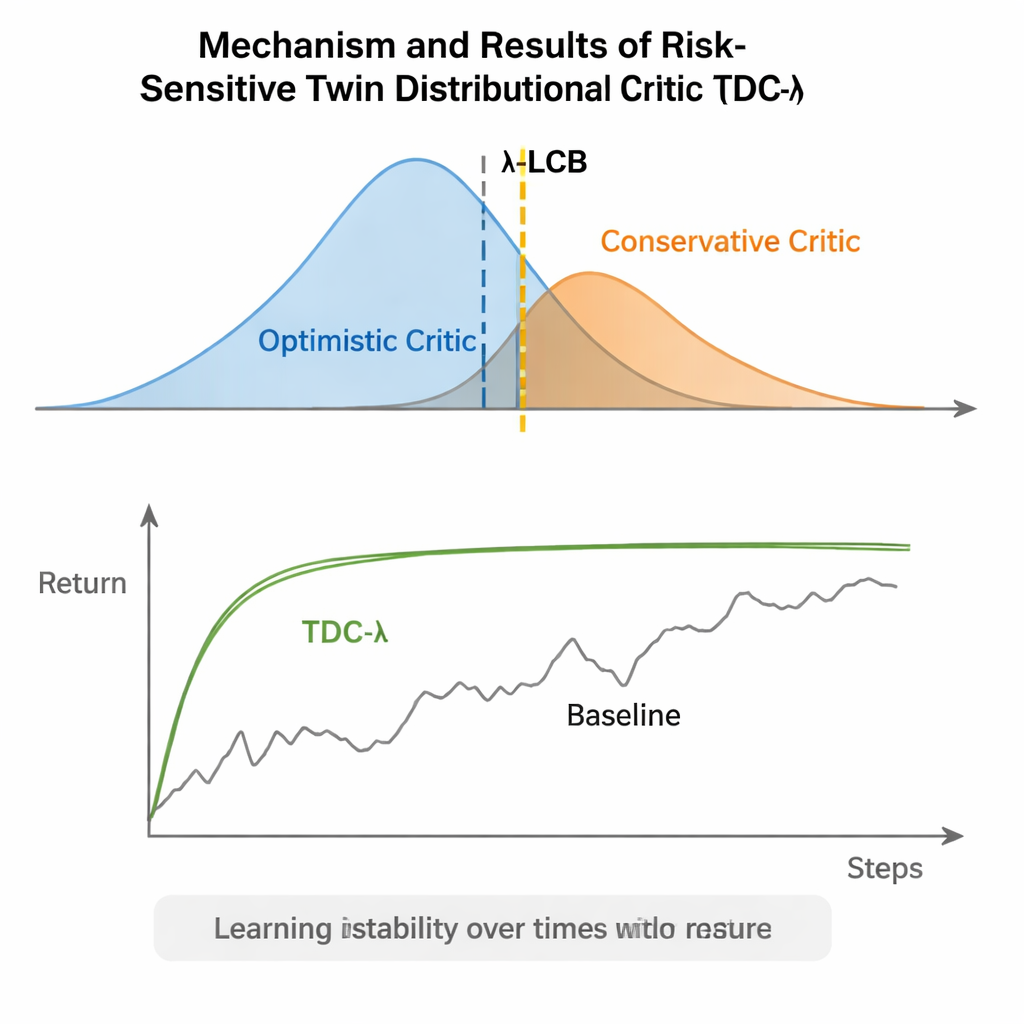
כפתור פשוט ללמידה בטוחה יותר
במונחים יום-יומיים, TDC-λ נותנת למערכות למידת חיזוק "מרווח ביטחון" כשמחליטות עד כמה להאמין באופטימיות שלהן. על ידי לימוד התפלגויות מלאות של תוצאות אפשריות ואז היטהות לכיוון הביקורתן הבטוח יותר באמצעות כפתור λ, האלגוריתם מקטין תנודות קיצוניות באימון תוך שמירה על ביצועים סופיים גבוהים. עבור מיישמים, זה מציע דרך מעשית לבנות בקרים אמינים יותר לרובוטים ומערכות בקרה רציפה אחרות: התחילו עם λ שמרני במידה והתאימו אותו לפי מידת התנודתיות של תהליך הלמידה. המסר הרחב הוא ששינוי מושכל של מה שהסוכן לומד ממנו — מטרות האימון שלו — יכול לספק הרבה מהחוסן שמיוחס לעיתים למבנים מורכבים יותר, ובכך להפוך למידת חיזוק מתקדמת ליציבה ונגישה יותר.
ציטוט: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
מילות מפתח: למידת חיזוק, בקרה רציפה, למידה רגישת-סיכון, ביקורתנים התפלגותיים, רובוטיקה