Clear Sky Science · he
ניתוח השוואתי של ביצועי מודלים לשוניים גדולים בבחינת התמחות בתחום רפואת השיניים
מדוע צ׳אטבוטים חכמים חשובים לרופאי שיניים בעתיד
בינה מלאכותית משנה במהירות את אופן הלמידה והעבודה של רופאים ורופאי שיניים. אחד הכלים הבולטים הוא צ׳אטבוט שיתופי שמופעל על ידי מודלים לשוניים גדולים — אותו סוג טכנולוגיה שעומד גם מאחורי עוזרים דיגיטליים פופולריים. במחקר זה נשאלה שאלה פשוטה אך חשובה: אם סטודנטים לרפואת שיניים ישתמשו בכלים אלה כדי להתכונן למבחן התמחות תחרותי ברדיולוגיה אורו־מקסילופציאלית, עד כמה המכונות יעמדו במבחן בפועל?
בדיקת בינה מלאכותית במבחן אמיתי
כדי לבדוק זאת, החוקרים פנו למבחן כניסה להתמחות ברפואת השיניים (DUS) בטורקיה, שמסייע לקבוע מי יוכל להיכנס לתכניות הכשרה מתקדמות. מתוך שנים קודמות של המבחן הארצי בחרו 208 שאלות רב־ברירתיות המכסות נושאים שעל מומחי רדיולוגיה לשלוט בהם, מפיזיקת הקרינה וטכניקות הדמיה ועד גידולים של הלסתות ומחלות הסינוסים. מרבית השאלות היו טקסטואליות בלבד, אך קבוצה קטנה יותר דרשה פירוש תמונות רדיוגרפיות, המשקף עבודה דיאגנוסטית מציאותית.
שבעה צ׳אטבוטים עונים לאתגר זהה
הצוות הזין לאחר מכן כל שאלה, בטורקית, לשבעה צ׳אטבוטים נפוצים מבוססי מודלים שונים: שתי גרסאות של ChatGPT, וכן Gemini, Copilot, DeepSeek, Claude ו‑Grok. כל שאלה הוזנה בזהירות ובנפרד כדי למנוע זליגה בין שיחות. חוקר שני השווה כל תשובת בינה מלאכותית למפתח הרשמי וסימן כל תשובה כתקינה או לא תקינה. בסוף השתמשו המחברים בבדיקות סטטיסטיות סטנדרטיות להשוואה בין המודלים, הן באופן כללי והן בתוך תחומי הנושא הספציפיים.
מי קיבל את הציון הגבוה — והיכן התקלקלו
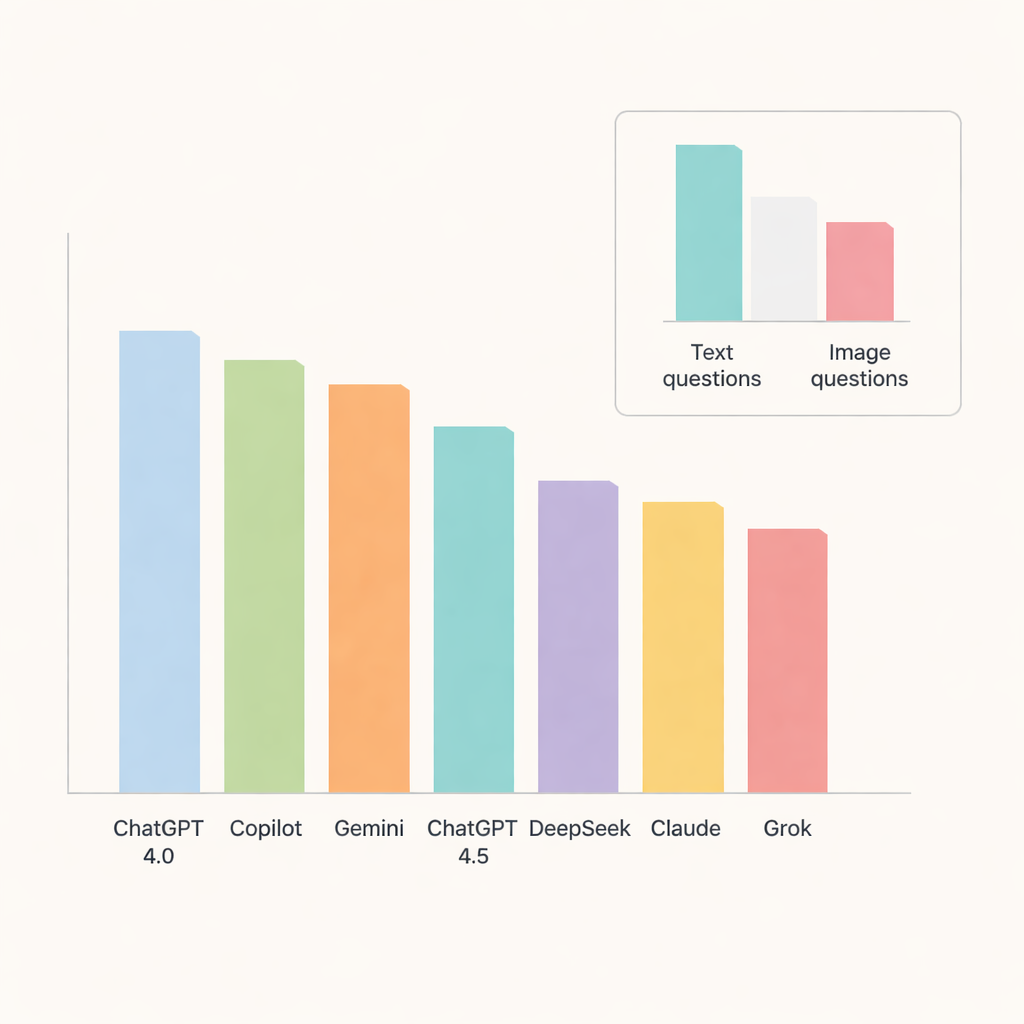
מבין כל הצ׳אטבוטים, ChatGPT 4.0 בלט והשיב נכון לכ‑91% מהשאלות. Copilot ו‑Gemini הגיעו לאחריו עם דיוק סביב טווח אמצע־עד־גבוה של ה‑80, בעוד ChatGPT 4.5, DeepSeek, Claude ו‑Grok התקבלו במעט אחור. כאשר החוקרים פירקו את התוצאות לפי נושאים, המודלים הצטיינו במיוחד בפאתולוגיה אורלית ובמחלות בלוטות הרוק, שם הדיוק התקרב או עלה על 90%. לעומת זאת אנטומיה רדיוגרפית וספירות רכות היה קשים יותר, וגרמו להורדת ציונים בכל המערכות והצביעו על תחומים שבהם הבינה המלאכותית עדיין מתקשה בפרטים דקים.
תמונות נשארות קשות יותר ממילים
מבחן מרכזי היה האם הצ׳אטבוטים יכולים להתמודד עם תמונות כפי שהם מתמודדים עם טקסט. כאן מגבלותיהם התבררו בבירור. הדיוק ירד בצורה חדה בשאלות מבוססות תמונה, אפילו עבור המודלים הביצועים ביותר. ChatGPT 4.0, Gemini ו‑Copilot הובילו בקטגוריה זו אך עדיין ענו נכון רק לכשלושת‑רבעים בערך של השאלות הוויזואליות. DeepSeek הייתה התשובה הגרועה ביותר בתמונות, עם קצת יותר משליש תשובות נכונות. עבור רוב המודלים, ההבדל בין ביצוע טקסט לביצוע תמונה היה גדול מספיק כדי להיות מובהק סטטיסטית, מה שהדגיש שפיענוח תמונות רפואיות נשאר משימה קשה לבינה המלאכותית הכללית של היום.
מה המשמעות לסטודנטים ולמטופלים
המסקנה של המחקר היא שצ׳אטבוטים מודרניים יכולים להיות עוזרים רבי‑עוצמה בהכשרה דנטלית, במיוחד עבור חזרה על עובדות ותרגול שאלות בסגנון מבחנים ברדיולוגיה. עם זאת, גם המערכות החזקות ביותר עושות מספיק טעויות — במיוחד בנושאים עם דרישה ויזואלית גבוהה או בעלי פירוט רב — כך שלא ניתן להחליף בהן בביטחה שיפוט מומחה. עבור סטודנטים ומטפלים, כדאי לראות בכלים אלה שותפים חכמים ללמידה או סיוע בהחלטה, לא סמכות עצמאית. בשימוש זהיר ומתחת לפיקוח הולם הם עשויים לזרז את הלמידה ולהרחיב את הגישה להסברים איכותיים, בעוד שהאחריות הסופית לאבחון ולטיפול נשארת בידי אנשי מקצוע מיומנים.
ציטוט: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
מילות מפתח: הכשרה בדנטליה, בינה מלאכותית, מודלים לשוניים גדולים, רדיולוגיה אורו־מקסילופציאלית, מבחנים רפואיים