Clear Sky Science · he
ארכיטקטורת רשת עצבית קונבולוציונית קלת משקל לזיהוי אלימות ברצפי וידאו
צופים בהמונים כדי שאנשים לא יצטרכו
ממופעים ומאולמות ספורט ועד תחנות מטרו וקניונים, מצלמות עוקבות היום כמעט אחרי כל מרחב צפוף. ועדיין, רוב הזמות הווידאו האלה נשמרות על ידי עיניים אנושיות עייפות שיכולות בקלות להחמיץ את הסימנים הראשונים של קרב או דחיפה המונית. מאמר זה חוקר כיצד צורה רזה ומהירה של בינה מלאכותית יכולה לסרוק וידאו חי אחר התנהגות אלימה בזמן אמת, אפילו על חומרה זולה, ולסייע לצוותי אבטחה להגיב במהירות לפני שמצב יוצא משליטה.
למה זיהוי אלימות בווידאו כל כך קשה
להתבונן במחשב ולבקש ממנו להבחין בין "קרב" ל"אין קרב" נשמע במבט ראשון פשוט: לזהות אנשים שמכים זה את זה. במציאות הבעיה מורכבת. התאורה עשויה להיות לקויה או להשתנות בפתאומיות, קהל יכול לחסום את שדה הראייה, והמצלמות מותקנות בזוויות שונות. הופעה צפופה בקונצרט רוק נראית כאוטית גם כאשר לא קורה דבר מסוכן, בעוד קרב איגרוף נראה אלים אך הוא תקין בזירה. מערכות ראייה מסורתיות בחנו דפוסי תנועה וקצוות שעוצבו ידנית פר פריים, ובזמן שהן עבדו במעבדה, לעיתים היו איטיות מדי או לא מדויקות די לצורך רשתות פיקוח עמוסות במציאות.
מוח דק יותר להזנות מצלמה
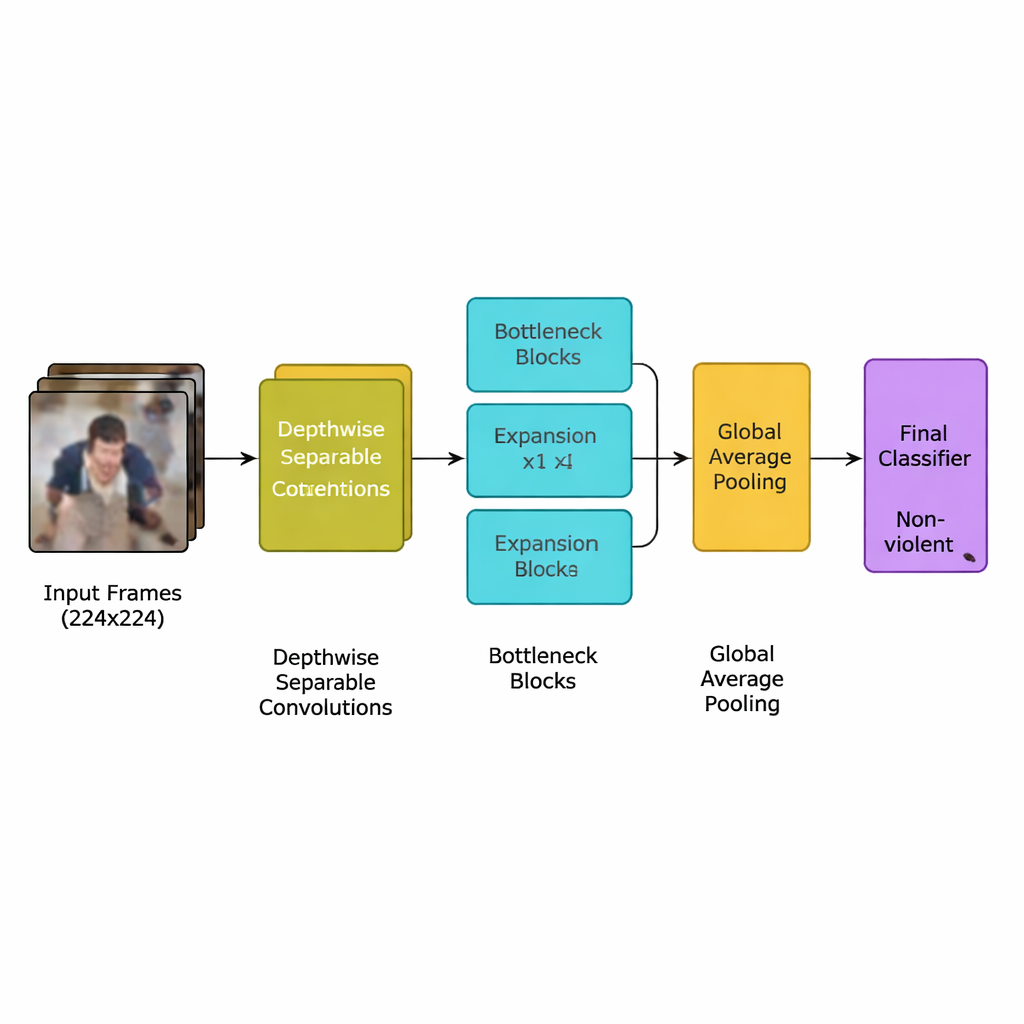
המחברים מציגים מודל למידה עמוקה חדש שעוצב במיוחד למשימה זו: רשת עצבית קונבולוציונית קלת משקל (CNN) הנגזרת ממשפחה יעילה של מודלים הידועה כ‑MobileNetV2. במקום להשתמש בשכבות כבדות רבות שדורשות מעבדי גרפיקה חזקים, הרשת נשענת על קונבולוציות מפרידות לפי עומק — חישובים קטנים וממוקדים שמקטינים משמעותית את מספר החישובים. היא גם משתמשת בבלוקים מסוג "צוואר בקבוק הופכי" (inverted bottleneck), שמרחיבים ואז דוחסים בקצרה את המידע כדי לשמור על רמזי תנועה חשובים תוך ירידת מיותרות. בנוסף לכך, הצוות מוסיף מנגנון תשומת לב הנקרא squeeze‑and‑excitation, שעוזר לרשת להתמקד בדפוסי תנועה במרחב ובזמן שמאפיינים אירועים אלימים, תוך התעלמות מפרטים מבלבלים ברקע.
מוידאו גלמי לאתר אזהרות אלימות
המערכת המלאה פועלת לפי צנרת ברורה. ראשית, זרמי הווידאו נשברים לפריימים, ורק כל פריים חמישי נשמר להסרת שכפולים קרובים תוך שמירה על תזוזות פתאומיות שמאותתות לעתים קרובות על קרב. הפריימים משנים גודל לסטנדרט של 224×224 פיקסלים, מטושטשים בעדינות כדי להפחית רעש רקע, ואז מוחלפים או מסובבים באופן אקראי בזמן אימון כדי שהמודל ילמד להתמודד עם זוויות מצלמה שונות. תמונות מוכנות אלה מוזנות ל‑CNN הקל, שממיר בהדרגה פיקסלים גלמיים לדפוסים ברמת‑על של התנהגות ההמון. לאחר שלב pooling סופי המסכם כל פריים, מסווג קטן מפיק החלטה פשוטה: אלים או לא אלים. מאחר שהמודל משתמש בכ־1.94 מיליון פרמטרים בלבד — פחות מאבותיו MobileNet ו‑MobileNetV2 — הוא יכול לפעול בזמן אמת על התקנים צנועים המוצבים בסמוך למצלמות ולא בשרת מרוחק.
מבחן המערכת
כדי לבדוק האם העיצוב הקומפקטי יכול להתחרות ברשתות כבדות יותר, החוקרים אימנו והעריכו אותו על שני מאגרי בדיקה נפוצים. מאגר ה‑Real‑Life Violence Situations מכיל 2,000 קטעים קצרים שנכרו מ‑YouTube ומציגים גם סצנות יום‑יומיות וגם קרבות אמיתיים במקומות שונים. מאגר ה‑Hockey Fight מכיל 1,000 קטעים ממשחקי הוקי מקצועניים, מחולקים בין משחק רגיל וקטטות על הקרח. על מאגרים אלה, המודל המוצע תייג נכון בסביבות 97 אחוז מהקטעים בסצנות מחיי יום‑יום ו‑94 אחוז בקטעי הוקי, התאמה או עליונות מול CNNים גדולים יותר כגון InceptionV3 ו‑VGG‑19 בעודו משתמש בהרבה פחות חישובים. בדיקות חוצי‑מאגר — אימון על אחד ובדיקה על השני — הראו שהמערכת עדיין מבצעת באופן סביר, מה שמרמז שהיא לוכדת דפוסי תנועה כלליים במקום לשנן סביבה יחידה.
מה זה אומר לבטיחות היומיומית
עבור הקהל הרחב, המסקנה המרכזית היא שכעת אפשר לבנות מערכות מצלמות שמסמנות אוטומטית אלימות פוטנציאלית במהירות ובזול, ללא צורך בשרתים ענקיים או בערנות אנושית מתמדת. המחקר מראה שרשת עצבית שמותאמת בקפידה יכולה לצפות במספר זרמים בו‑זמנית, לשלוח התראות כשהיא מגלה התנהגות מסוכנת, ועדיין לפעול על חומרה בעלת צריכת חשמל נמוכה המתאימה לצירי תחבורה ציבוריים, בתי ספר, בתי חולים ורחובות העיר. אמנם קיימים אתגרים שנותרו — כגון טיפול בסצנות חשוכות מאוד, צפיפות קהל גבוהה או הוספת רמזי קול — העבודה מצביעה על עתיד שבו מצלמות חכמות ישמשו כחיישני אזהרה בלתי נלאים, יסייעו לצוותי אבטחה להגן על אנשים ביעילות רבה יותר ויקטינו את העומס על השומרים האנושיים.
ציטוט: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
מילות מפתח: זיהוי אלימות, מעקב וידאו, CNN קל משקל, MobileNetV2, בטחון ציבורי