Clear Sky Science · he
מחקר על מודולים לשיפור קורלציה פלג-אנד-פליי בלמידה עמוקה מולטי-תווית
להנחות מכונות להתמודד עם יותר מדי תגיות
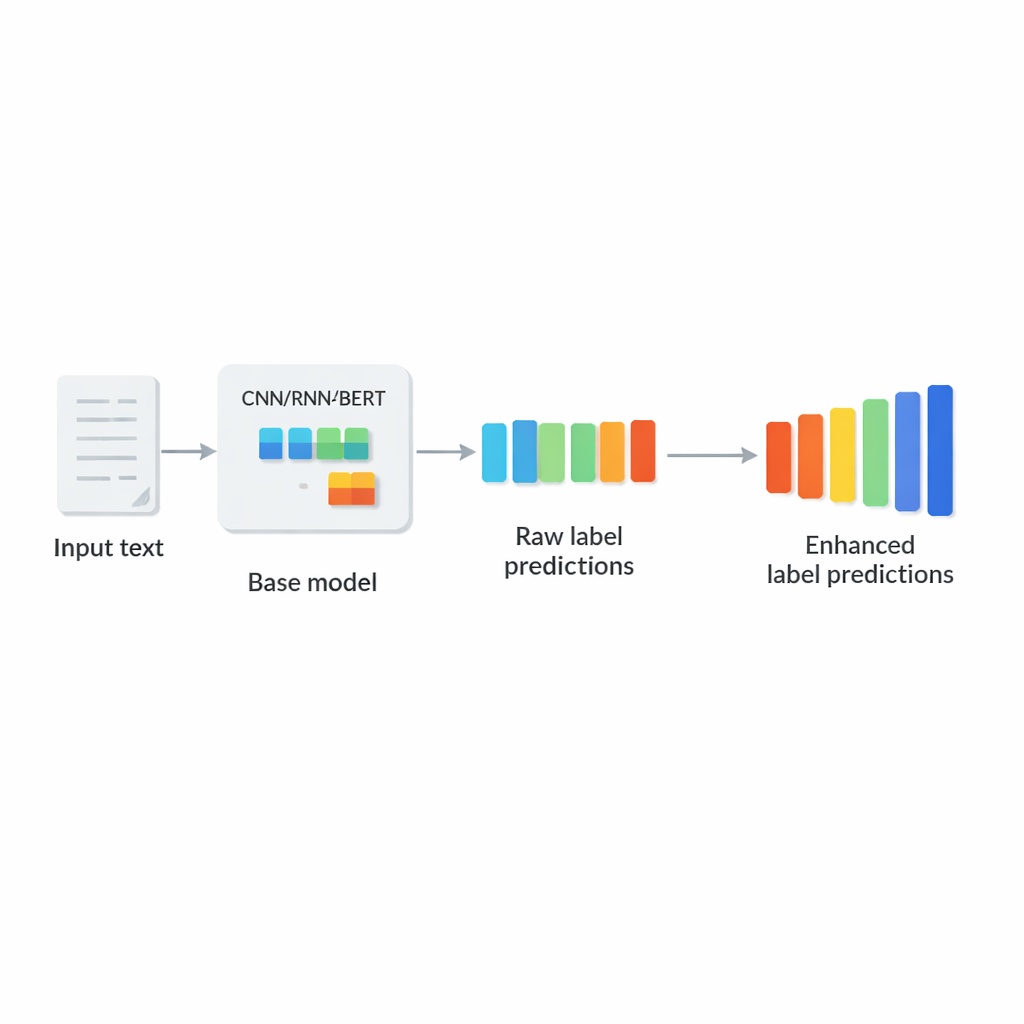
חנויות מקוונות, ארכיונים משפטיים ובסיסי נתונים רפואיים מסתמכים על תוכנה שיכולה לתייג במהירות כל מסמך חדש עם התוויות המתאימות. אבל מערכות מודרניות לעתים קרובות מתמודדות עם עשרות אלפי ואף מיליוני תוויות אפשריות — מקטגוריות מוצר ועד נושאים רפואיים — בעוד שכל טקסט צריך רק כמה תוויות בודדות. המאמר מציג רכיב נוסף חדש, שנקרא רשת שיפור קורלציית התוויות (LCENet), שעוזר למודלים עמוקים קיימים לנצל טוב יותר את האופן שבו תוויות מופיעות יחד בנתונים אמתיים, מה שמביא לתיוג טקסט מדויק ומהיר יותר.
מדוע תיוג בקנה מידה אינטרנטי כל כך קשה
יישומים רבים בעולם האמיתי נכנסים למה שמחקרנים קוראים לו סיווג טקסט רב‑תוויתי קיצוני: נתון תיאור קצר או מסמך ארוך, על המערכת לבחור תת‑קבוצה קטנה של תוויות רלוונטיות מתוך קטלוג עצום. דוגמאות כוללות שיוך קטגוריות למוצרים באתר מסחר אלקטרוני, אינדוקס מאמרים ביומדיים בעזרת מושגי MeSH, התאמת מודעות לדפי אינטרנט או מיפוי טקסטים משפטיים לקודי חוקים מפורטים. בהקשרים אלו יש שלוש בעיות משותפות: רשימת התוויות גדולה מאוד, רוב התוויות נדירות, וכל טקסט משתמש רק בכמה תוויות. טכניקות מסורתיות או מחלקות את הבעיה למספר רב של מסווגים קטנים או מדחסות את התוויות לווקטורים בממד נמוך, אך לעתים קרובות הן מסתמכות על ספירות מילים פשוטות ולא מצליחות ללכוד במלואן משמעות או יחסים בין תוויות.
מה שחסר למודלים עמוקים סטנדרטיים
גישות למידה עמוקה מודרניות, כגון רשתות קונבולוציה, רשתות מחזוריות ומודלים מבוססי Transformer כמו BERT, שיפרו משמעותית את הבנת הטקסט על ידי למידת ייצוגים סמנטיים עשירים. עם זאת, כמעט כולן מבצעות פישוט קריטי בשלב הסופי: לאחר שהטקסט מקודד לווקטור, הן מנבאות כל תווית באופן עצמאי. בפועל, תוויות מתקשרות זו עם זו בעוצמה. מאמר רפואי המתויג כ"סכרת" סביר שיופיע גם עם "עמידות לאינסולין", וגאדג'ט המתויג "סמארטפון" בדרך כלל קשור גם ל"אלקטרוניקה" ו"מכשירי תקשורת". התעלמות מתבניות אלה מונעת מהממודלים להשתמש בתוויות בטוחות כדי לתמוך באלה החלשות, ואף עלולה להניב שילובים שאינם הגיוניים יחד.
תוסף שלומד יחסי תוויות
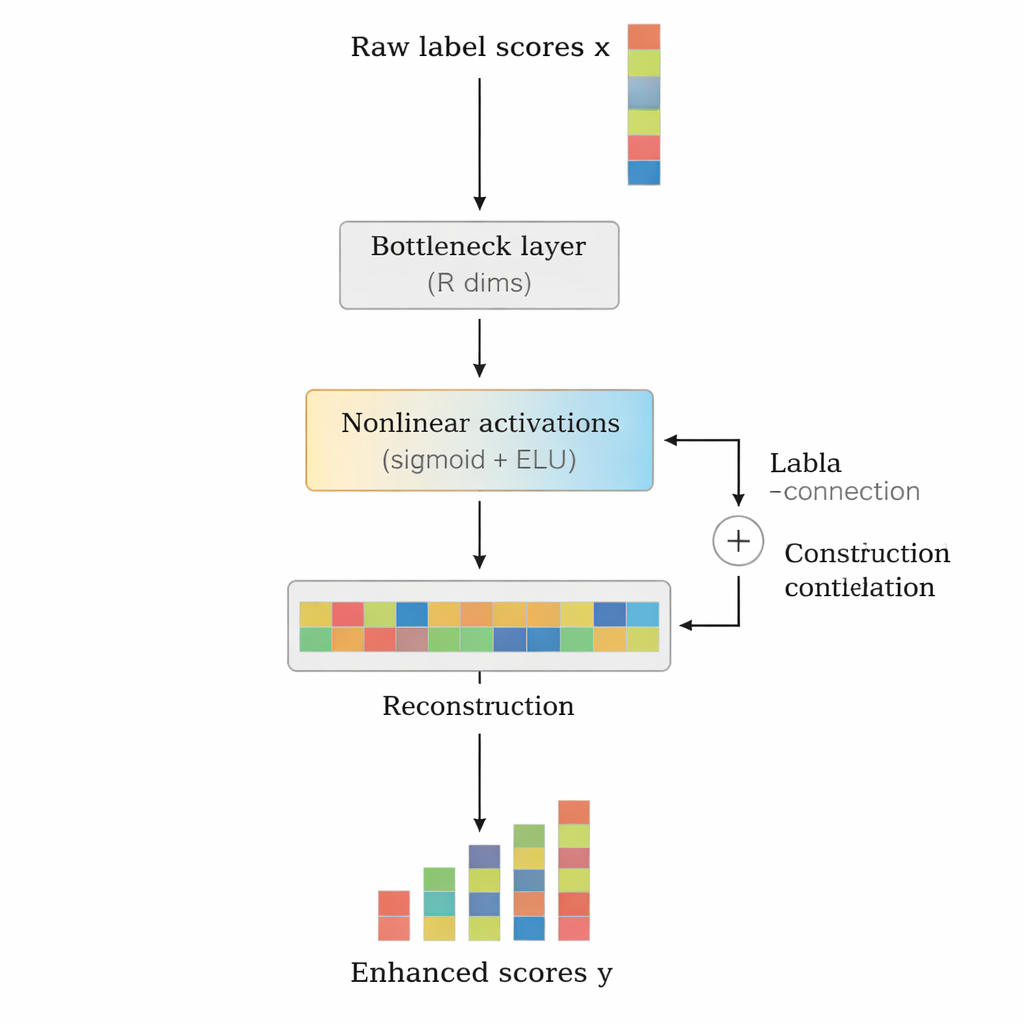
המחברים מציעים את LCENet כרכיב קל‑משקל, פלג‑אנד‑פליי, שממוקם אחרי כל מסווג טקסט עמוק קיים. במקום לשנות את אופן קריאת הטקסט על ידי המודל הבסיסי, LCENet לוקח את ציוני התוויות הגולמיים שהוא מייצר ומעביר אותם דרך "בקבוקון" קומפקטי שמאלץ את המערכת לגלות ייצוג מממד נמוך שבו תוויות קשורות מקבצות זו לזו. פונקציות הפעלה בלתי‑ליניאריות מאפשרות למודול ללכוד קשרים מורכבים מדרגה גבוהה, לא רק זיקות זוגיות פשוטות. חיבור שאריות (skip) מזין את הציונים המקוריים ישירות לפלט לצד הציונים המתוקנים, מה שמייצב את האימון ומבטיח שהתוסף לא יהפוך בקלות את ההופעה לגרועה יותר. באופן מהותי, LCENet מצמצם את מספר הפרמטרים הנוספים ממצב שהיה גדל בריבוע מספר התוויות לגידול ליניארי שניתן לנהל, ולכן הוא נשאר ישים גם במקרים של מאות אלפי תוויות.
הוכחת היתרונות על פני מודלים וסטים שונים
כדי לבדוק האם LCENet אכן כללי, המחברים חיברו אותו לארבעה מודלים עמוקים שונים מאוד, כולל ארכיטקטורות מבוססות CNN ו‑BERT, וכן מערכות שתוכננו במיוחד לסביבות ביומדיות ולמצבי תוויות קיצוניים. הם העריכו את השילובים האלה על שלושה מאגרי מבחן ציבוריים: קורפוס משפטי אירופאי (EUR-Lex), מאגר מוצרי Amazon (AmazonCat-13K) ואוסף ויקיפדיה עצום עם מעל חצי מיליון תוויות (Wiki-500K). ברחבי כל המודלים, הסטים והמדדים הממוקדים דירוג (שישה בסך הכל), LCENet שיפר בעקביות את הביצועים, לעתים הרים דיוק‑טופ‑1 ביותר מחמש נקודות אחוז על הסט הגדול ביותר. עקומות האימון הראו גם כי LCENet לעתים חותך כמעט בחצי את מספר צעדיי האימון הנדרשים להגיע לדייקנות נתונה, מכיוון שמבנה קורלציית התוויות הנוסף מספק אותות למידה ברורים יותר כבר מההתחלה.
מדוע זה חשוב למערכות יומיומיות
לעובדים המיישמים כבר מודלים עמוקים לתיוג טקסט, LCENet מציע דרך מעשית לשדרג דיוק ומהירות אימון ללא תכנון מחדש של המערכות או איסוף סוגי תיוג חדשים. הוא מתייחס למרחב התוויות עצמו כמקור ידע, לומד אילו תגיות נוטות להופיע יחד או להפשיל זו את זו, ואז דוחף את התחזיות בהתאם. למרות שפותח עבור טקסט, אותו רעיון של שיפור תחזיות באמצעות יחסים שנלמדו בין הפלטים יכול להיות מיושם על תמונות, נתונים מולטימודליים ומשימות חיזוי מובנות אחרות. בפשטות, LCENet עוזר למכונות "לזכור" איך תוויות קשורות, כך שהן מנחשות פחות כמו תיבות סימון מבודדות ויותר כמו אדם מבין שמכיר כיצד מושגים מתחברים.
ציטוט: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
מילות מפתח: סיווג טקסט רב-תוויתי קיצוני, קורלציה בין תוויות, למידה עמוקה, סיווג טקסט, רשתות עצביות