Clear Sky Science · he
DMSCA: תשומת לב ערוץ-מרחבית דינמית רב-קנה מידה לשיפור ייצוג התכונות ברשתות עצביות קונבולוציוניות
ללמד מחשבים לשים תשומת לב טובה יותר
מערכות מודרניות לזיהוי תמונות יכולות לזהות חתולים, תמרורי תנועה וגידולים בסריקות — אך לא תמיד יודעות על מה להתרכז בתוך התמונה. מאמר זה מציג שיטה חדשה המסייעת למערכות אלו להתרכז בחלקים החשובים ביותר של התמונה, לשפר את הדיוק ולהפוך אותן לאמינות יותר בתנאים הלא-מאוזנים של העולם האמיתי. השיטה, הנקראת תשומת לב ערוץ-מרחבית דינמית רב-קנה מידה (DMSCA), משתלבת ברשתות עצביות קונבולוציוניות קיימות ועוזרת להן לזהות גם את ה"מה" וגם את ה"איפה" בתמונה בצורה חכמה יותר.
מדוע המוקד חשוב לראייה מכונתית
רשתות עצביות קונבולוציוניות, המנועים מאחורי יישומי ראייה רבים, בדרך כלל מתייחסות לכל אות פנימית כאילו היא חשובה באותה מידה. משמעות הדבר היא שגבול חלש של כנף ציפור ופיסת שמיים עלולים לקבל תשומת לב דומה, אף על פי שרק האחד עוזר לזהות את המין. שיטות "תשומת לב" מוקדמות ניסו לתקן זאת על ידי שיקלול אותות פנימיים מסוימים יותר מאחרים — או לאורך ערוצים בדומה לצבע, או על פני פריסת תמונה דו-ממדית. אך אותן שיטות לעתים השתמשו בכללים קבועים שתוכננו ביד, בחנו רק קנה מידה יחיד של פרטים בכל פעם, או שילבו מידע בצורה נוקשה שלא יכלה להסתגל לתמונות שונות. כתוצאה מכך לעתים פספסו פרטים עדינים, התעלמו מכיוונים כמו "אופקי מול אנכי" או התקשו כאשר התמונות היו רועשות או מטושטשות.
תוסף תשומת לב חכם יותר
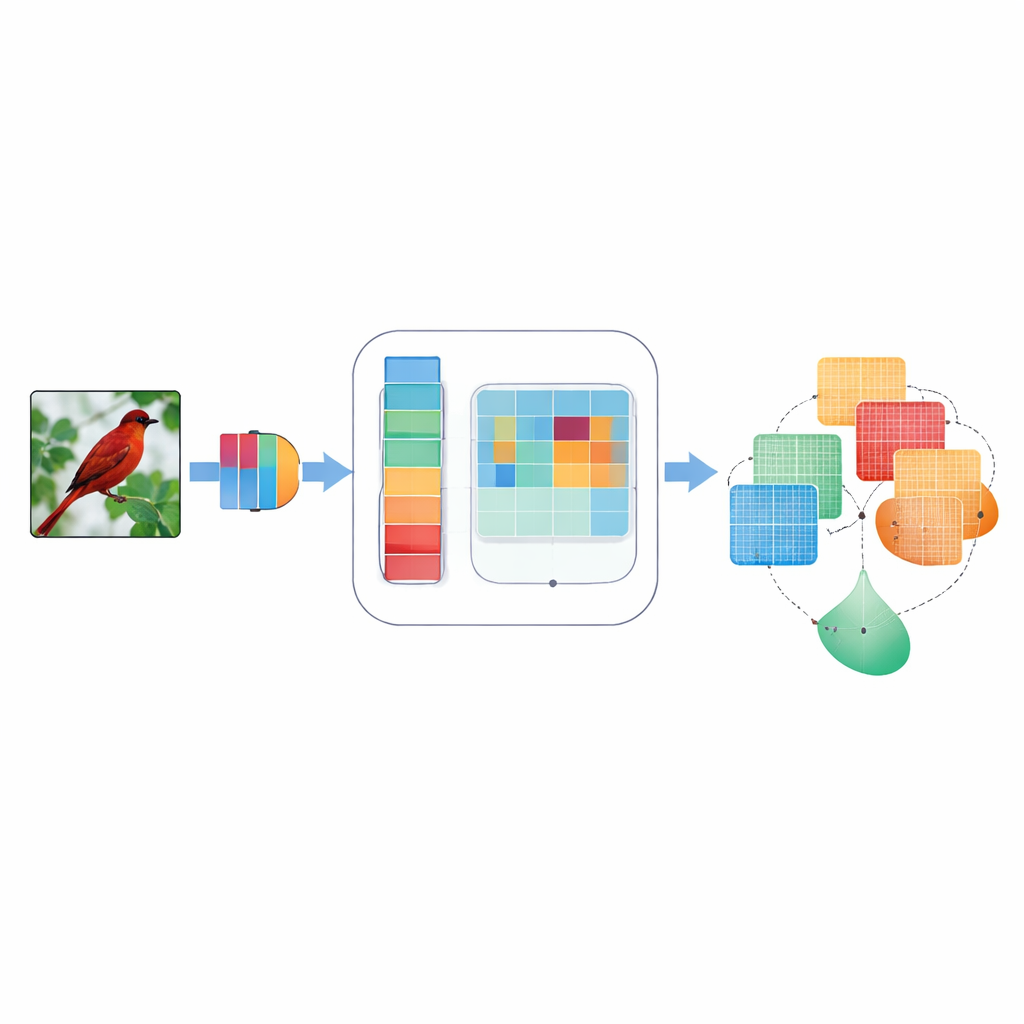
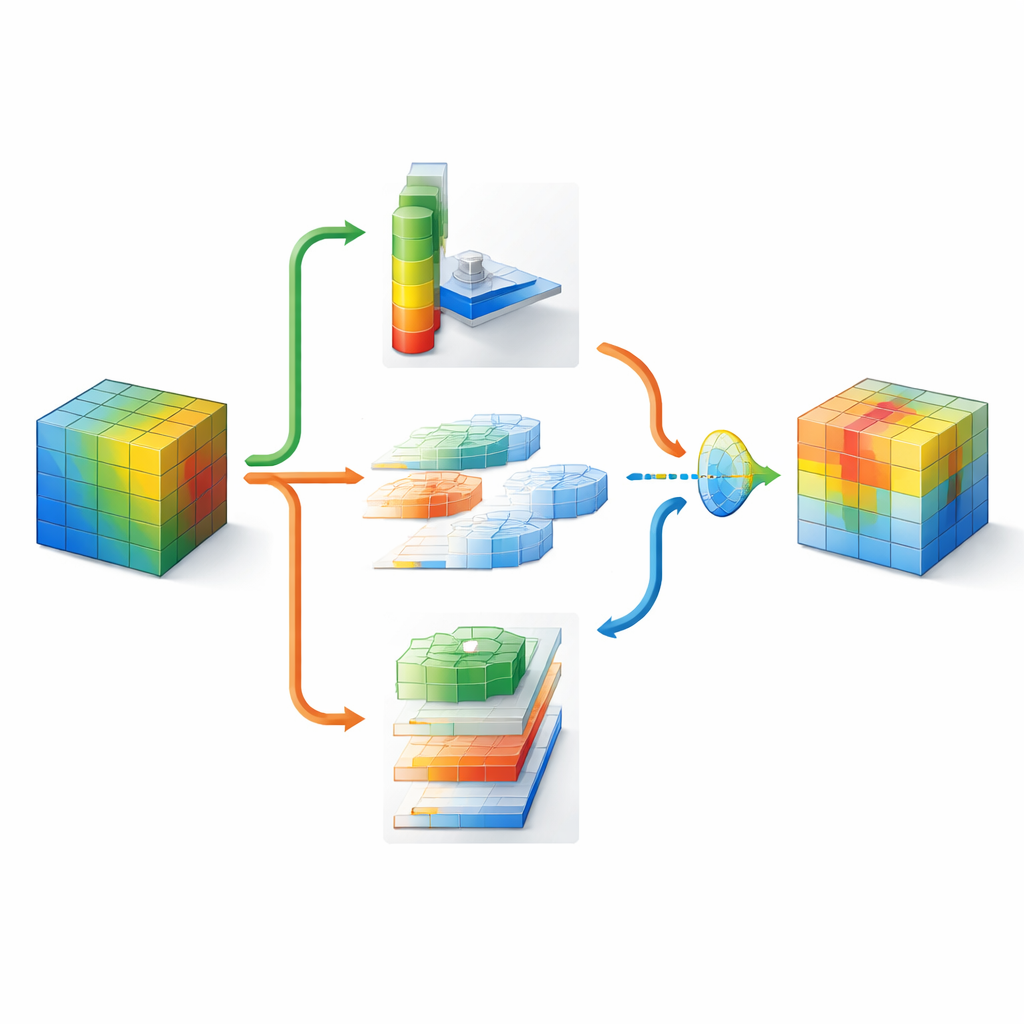
DMSCA מעוצבת כמודול קטן שניתן לחברו לרשתות ידועות כגון ResNet מבלי לשנות את המבנה הכולל שלהן. בתוך המודול היא מתאמת שישה חלקים קשורים היטב שעובדים יחד במקום בנפרד. חלק אחד מסכם את התמונה כולה כדי ללכוד מה קורה בצורה גלובלית, בעוד שאחר לומד עד כמה כל ערוץ פנימי צריך להיות משמעותי, באמצעות "טמפרטורה" ניתנת-בקרה שיכולה להחדות או להחליש החלטות לפי הצורך. מצד המרחב, DMSCA משתמשת בכמה גדלי חלונות במקביל כדי ללכוד גם טקסטורות זעירות וגם צורות גדולות יותר, והיא מתייחסת במפורש לכיוונים אופקיים ואנכיים כדי שמקבצים ארוכים או פסים לא ייטשטשו. לבסוף, במקום לחבר אותות אלה פשוט יחד, המודול לומד, פיקסל-אחר-פיקסל, כמה לסמוך על מידע של ה"מה" מערוצים מול מידע של ה"איפה" מהמרחב.
להסתכל על תמונות בקנה מידה וכיוונים רבים
כדי להבין היכן להסתכל בתמונה, DMSCA דוחסת תחילה את ערוצי הפנים הרבים למפת שתי-שכבות קומפקטית שמדגישה גם מגמות רקע וגם תכונות בולטות. אחר כך היא מעבירה מפה זו דרך מספר פילטרים מקבילים בגדלים שונים. פילטרים קטנים רואים פרטים דקים כמו פרווה או נוצות, בעוד שפילטרים גדולים תופסים צורות כמו ראש שלם או גוף. במקביל, יחידת כיווניות סורקת לאורך שורות ועמודות בנפרד, ושומרת על המיקום המדויק של מבנים חשובים. תצפיות אופקיות ואנכיות אלו מורשות לאחר מכן להאדיר זו את זו, כך שאות אנכי חזק, למשל, יכול לתמוך במיקומים אופקיים נכונים. התוצאה היא מפת תשומת לב עשירה שאומרת לרשת לא רק שמשהו חשוב, אלא גם איפה הוא ובאיזה קנה מידה.
לתת לרשת להחליט מה חשוב ביותר
מכיוון שחלקים שונים של תמונה עשויים לדרוש אסטרטגיות שונות, DMSCA אינה כופה מתכון קבוע לשילוב מידע ערוצי ומרחבי. במקום זאת היא בונה "שער" זעיר שבוחן את שניהם ומחליט — באופן עצמאי עבור כל פיקסל — כמה משקל לתת לכל סוג מידע. ברקע עמוס, המערכת עשויה להסתמך יותר על אילו ערוצים בולטים, בעוד שבקצות חדים של עצמים היא עשויה להדגיש רמזים מרחביים. שלב הפעלת התאמה סופי פועל לאחר מכן כמו מפסק דימר שנלמד, המחזק אזורים באמת אינפורמטיביים ומכהה רעשי שארית. תהליך רב-שלבי זה עוזר לכוון את תשומת הלב של הרשת לאזורים קוהרנטיים הקשורים לעצמים, כפי שמאושש על-ידי מפות חום ויזואליות ומדדים כמותיים של עד כמה האזורים המודגשים תואמים לאובייקטים בנתוני אמת.
ראייה חדה יותר עם מאמץ נוסף מתון
המחברים בדקו את DMSCA על מספר בנצ'מרקים סטנדרטיים, מקבוצות קטנות של תמונות זעירות ועד מאגר הנתונים הנרחב ImageNet. כשהתוסף נוסף למודלים פופולריים של ResNet, DMSCA שיפרה בהתמדה את דיוק הסיווג — בכ- עד כ-2 נקודות אחוז בקבוצות קטנות וכ-1.5 נקודות אחוז ב-ImageNet — והייתה טובה יותר מטווח שיטות תשומת לב קיימות. היא גם הפכה מודלים לעמידים יותר לשחיקות תמונה נפוצות כמו רעש, טשטוש ודחיסת יתר, ושיפרה ביצועים במשימות קשורות כגון גילוּי עצמים ותיוג סצנות. שיפורים אלה הושגו עם עלייה מתונה בלבד בחישוב ובזיכרון. במילים פשוטות, DMSCA מעניקה לרשתות קונבולוציוניות דרך גמישה יותר ותלויה בהקשר להחליט על מה להסתכל ומה להתעלם, ומביאה את הראייה המכנית צעד אחד קרוב יותר למיקוד סלקטיבי של הראייה האנושית.
ציטוט: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
מילות מפתח: מנגנוני תשומת לב, זיהוי תמונות, רשתות עצביות קונבולוציוניות, ייצוג תכונה, ראייה ממוחשבת חסינה