Clear Sky Science · he
שיפור אחזור חוצה-ממשקים באמצעות אופטימיזציה של גרף תוויות ופונקציות אובדן היברידיות
חיפוש חכם יותר בין תמונות ומילים
יום־יום אנו גוללים בים של תמונות, סרטונים וטקסטים. למצוא בדיוק את מה שאנחנו רוצים — למשל את כל התמונות שתואמות כיתוב קצר — תלוי ביכולת המחשבים לקשר בין תמונה לשפה. מאמר זה חוקר שיטה חדשה להגדלת הדיוק בקישור הזה, במיוחד בסצינות ראליסטיות ומסובכות שבהן מופיעות בו-זמנית רעיונות וחפצים רבים. התוצאה היא כלים חכמים יותר לחיפוש שמבינים טוב יותר את הכוונה שלנו, ולא רק את המילים שהקלדנו.
מדוע יש משמעות לריבוי משמעויות בתמונה אחת
תמונה בודדת כמעט ולא מציגה רק דבר אחד. צילום של לווייתן הגועש מהים יכול לכלול בו־זמנית את הים, השמיים, הגלים, הרוח וחיי הבר. כאשר מתייגים תמונה כזו, בדרך כלל מצמידים לה מספר תוויות המקושרות ביניהן בדרכים עדינות. מערכות החיפוש הקיימות נוטות להתייחס לתוויות אלה כאילו היו תיבות סימון בלתי תלויות — פישוט שמבטל רמזים שימושיים: אם "לווייתן" מופיע לעתים קרובות עם "ים", ראיית האחת צריכה להעלות את הסיכוי לאחרת. עבודה זו מתמקדת בלכידה של הקשרים החבויים בין התוויות, כך שחיפוש אחרי רעיון אחד יוכל למצוא גם תמונות וטקסטים שמביעים רעיונות קרובים.

בניית רשת של תוויות מקושרות
המחברים מציגים טכניקה הנקראת רשת קונבולוציה גרפית דו-שכבתית, או L2-GCN, למידול הקשרים בין תוויות. בפשטות, כל תווית (כמו "שמיים" או "לווייתן") מטופלת כצומת ברשת, והקשתות בין הצמתים משקפות עד כמה התוויות מופיעות יחד. השיטה מאפשרת לכל תווית "להאזין" שוב ושוב לשכנותיה, ולשלב מידע מתוויות קרובות תוך שמירה על זהותה הייחודית. לאחר תהליך זה מקבלים תיאורים עשירים יותר של התוויות, המלכדים טוב יותר את אופן מבנה הסצנות האמיתיות — מרעיונות מקבילים ("ים" ו"חוף") ועד לרמות היררכיות יותר ("חיה" ו"לווייתן").
ללמד תמונות וטקסט לחלוק מרחב משותף
כמובן שהתוויות הן רק חצי מהסיפור; המערכת גם חייבת ללמוד מהתמונות ומהטקסטים עצמם. המסגרת משתמשת בכלים מבוססים על מנת להפוך פיקסלים ומילים לתכונות נומריות, ואז לדחוף את שני סוגי הנתונים למרחב משותף שבו ניתן להשוות את משמעותם ישירות. מודול אדברסרי — בהשראת דוחה־מושך של רשתות מתנגדות — מונע מהמודל להיצמד לתכונות ייחודיות של תמונות או טקסט בלבד. זה מסייע שהמרחב המשותף יתמקד בתוכן ולא בפורמט, כך שתמונה של רחוב שוקק וכיתוב קצר שמתאר אותו יגיעו קרוב זה לזה במפת המשמעות המשותפת.
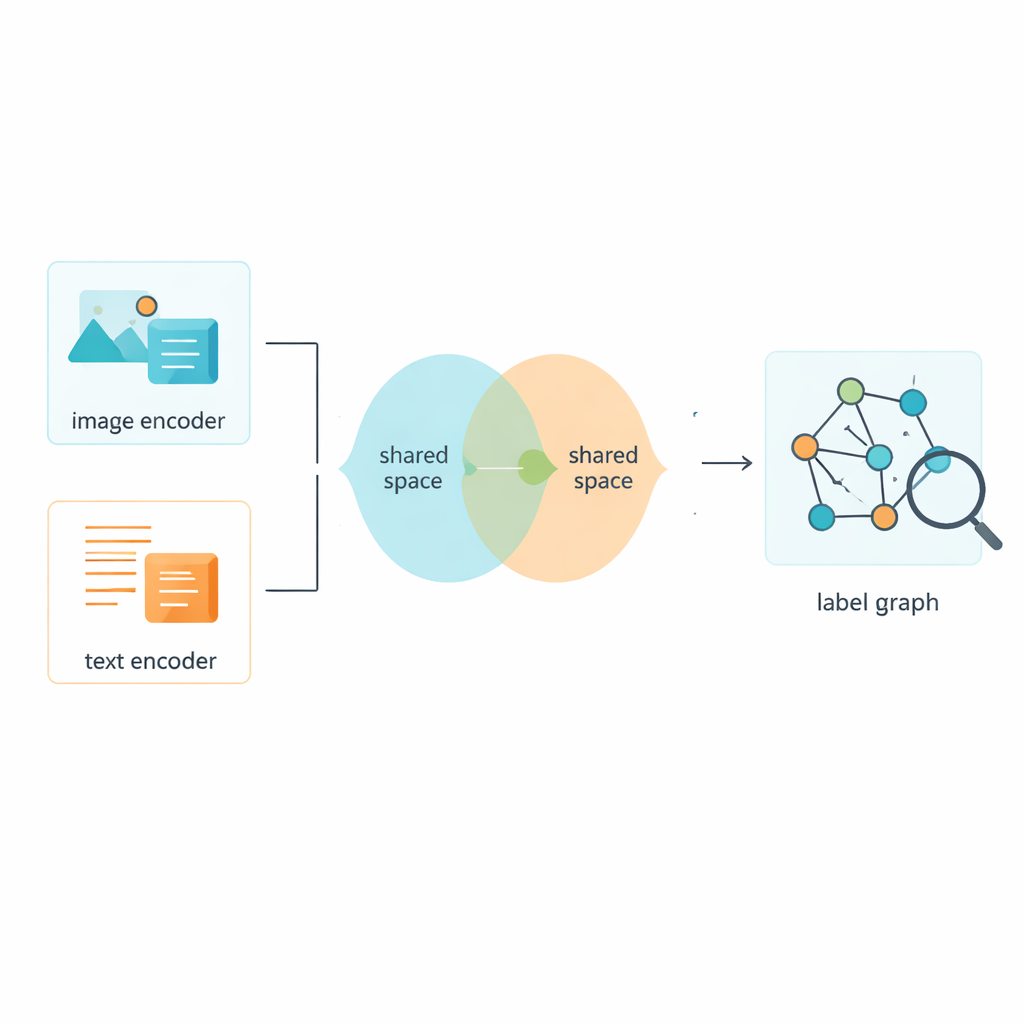
אסטרטגיית אימון היברידית להבחנות חדות יותר
אימון מערכת כזו דורש יותר מכלל למידה אחד. המחברים מעצבים פונקציית אובדן משולבת, שנקראת Circle-Soft, הממזגת שתי רעיונות משלימים. חלק אחד מעודד דוגמאות מאותה קטגוריה להתקבץ בצפיפות בעוד שחלק אחר דוחק קטגוריות שונות זו מרוחקת באופן גמיש והתאמתי. החלק השני מתמקד עד כמה תמונות וטקסטים שמתארים את אותה סצנה מתיישרים בין הפורמטים. משקל ניתן לכוונון מאזן בין שתי המטרות הללו כדי שהמודל לא יתאמן יתר על המידה על גבולות קטגוריה חדים או על התאמה חוצת־ממשקים בלבד. אובדנים נוספים של סיווג ואדברסרי מעודדים עוד יותר עקביות בין התוויות המעושרות לבין התכונות המשותפות של תמונה–טקסט.
כמה זה משפר את החיפוש?
כדי לבחון האם רעיונות אלו מתורגמים לשיפור בחיפוש, המחברים בדקו את שיטתם על שלושה אוספים פופולריים של זוגות תמונה–טקסט מהעולם האמיתי: MIRFlickr, NUS-WIDE ו-MS-COCO. מאגרי נתונים אלה מכילים אלפי עד מאות אלפי תמונות עם תגים או כתוביות נלוות, המכסים סצנות יומיומיות מרחובות עירוניים ועד לחיי בר. בכל שלושת הבנצ'מרקים הגישה החדשה עקפה בעקביות טווח רחב של שיטות מתחרות, כולל מערכות מתקדמות אחרות שגולשות כבר במודלים גרפיים של תוויות. השיפורים — בסביבות חצי אחוז עד אחוז מלא בציון אחזור קפדני — עשויים להישמע צנועים, אבל בבנצ'מרקים מבוססים אפילו עליות קטנות מצביעות על הבנה מדויקת יותר של התוכן. במילים מעשיות, זה אומר שכאשר משתמש מזין שאילתה טקסט קצרה או שולח תמונה, המערכת תוציא ככל הנראה את ההתאמות החוצות־ממשקים הרלוונטיות ביותר בראש תוצאות החיפוש.
מה זה משמעותי למשתמשים יומיומיים
עבור לא-מומחים, המסר המרכזי הוא שטיפול חכם יותר בתוויות ובכללי האימון יכול לשפר במידה ניכרת את הדרך שבה מכונות מקשרות בין תמונות למילים. על־ידי התייחסות לתוויות כרשת מקושרת במקום תגיות מבודדות, וכשרקיפת האופן שבו מידע חזותי וכתוב נפגשים במרחב משותף, מסגרת זו עושה את החיפוש החוצה־ממשקים אמין יותר בסצנות מורכבות ורב־נושאיות. עם הזמן, טכניקות כאלה יכולות להניע ספריות תמונות אינטואיטיביות יותר, פלטפורמות מדיה ועוזרים חכמים שמוצאים את מה שאנחנו מתכוונים לו — גם כאשר המילים שלנו אינן תואמות באופן מושלם את התמונות שבראשינו.
ציטוט: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
מילות מפתח: אחזור תמונה-טקסט, חיפוש מולטימודלי, רשתות עצביות גרפיות, תוויות סמנטיות, למידת מכונה