Clear Sky Science · he
שיפור ייצוג הידע הרפואי במודלי שפה גדולים באמצעות אופטימיזציה של טוקנים קליניים
מדוע קריאת טקסט רפואי חכמה חשובה
מאחורי כל עוזר רפואי מבוסס בינה מלאכותית עומדת מיומנות פשוטה אך קריטית: איך הוא חותך טקסט לחתיכות שהוא יכול להבין. כאשר ה"חתיכה" הזו משתבשת — במיוחד במונחים רפואיים סיניים מורכבים — ה-AI עלול לפספס רעיונות מרכזיים בפנקסי רופאים או בשאלות מטופלים. מאמר זה מראה כיצד שינוי קטן וממוקד בשלב הראשון הזה יכול לשפר את היכולת של מודלים גדולים לקרוא, להסיק ולענות על נתונים רפואיים סיניים, מבלי לבנות מערכת חדשה לחלוטין.
לשבור טקסט לחתיכות בצורה הנכונה
מודלים מודרניים לא קוראים תווים או מילים ישירות; הם ממירים טקסט לישויות קצרות שנקראות טוקנים. באנגלית זה עובד די טוב, כי רווחים מסמנים כבר גבולות מילה. בסינית זה מורכב יותר: אין רווחים, ורבים מהביטויים הרפואיים הם ארוכים ומיוחדים. טוקניזרים סטנדרטיים, שתוכננו בעיקר עבור אנגלית, נוטים לחתוך את הביטויים האלה לפרגמנטים שרירותיים רבים. כאשר המודל רואה שם מחלה או בדיקת מעבדה מפוצלים לכמה חלקים מנותקים, קשה לו יותר ללמוד מה משמעות המונח בפועל, ותשובותיו לשאלות רפואיות עלולות להפוך לערפליות או לא מדויקות.
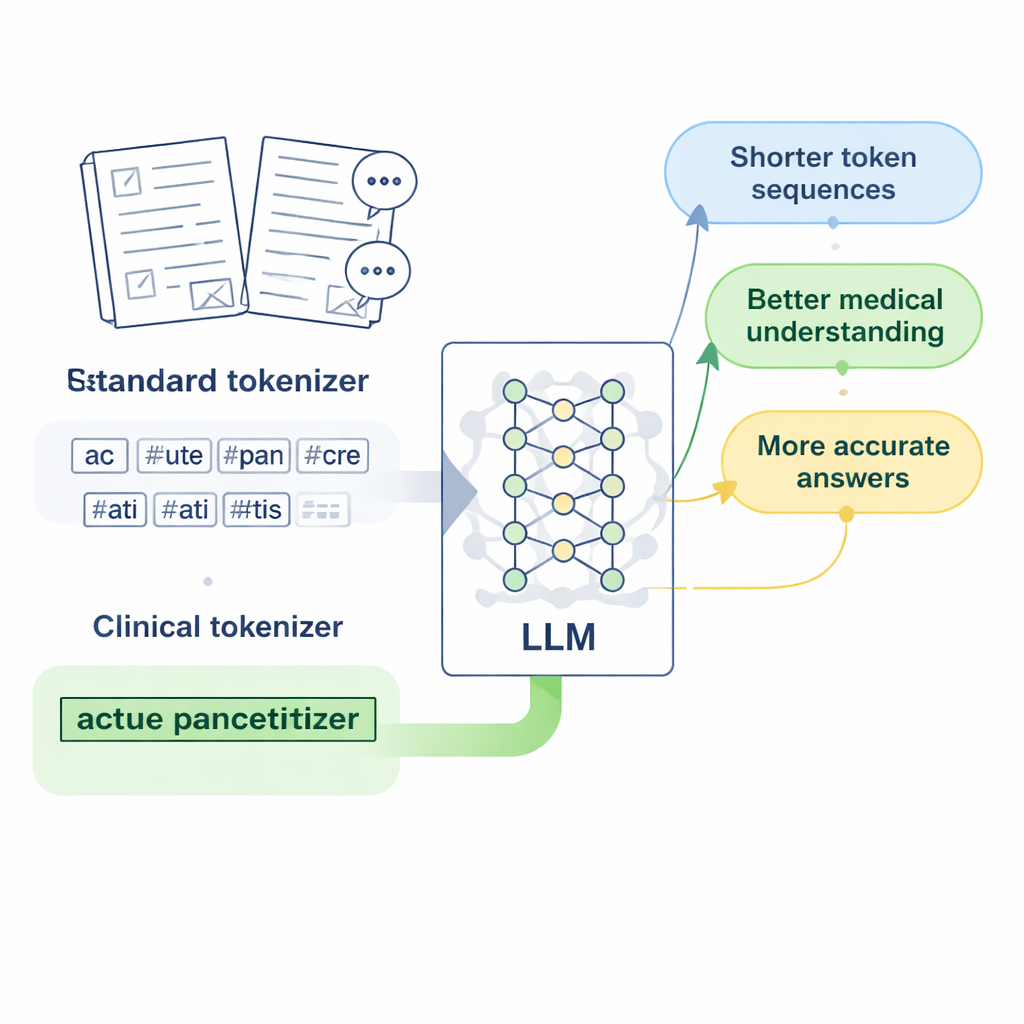
תכנון "טוקנים קליניים" לרפואה סינית
החוקרים מתמקדים ב-LLaMA2, מודל שפה גדול פתוח-מקור פופולרי, ושואלים: מה אם נלמד את הטוקניזר שלו לקסיקון רפואי עשיר יותר? הם אוספים אוספים גדולים של טקסט רפואי סיני, כולל מאגרי רפואה סינית מסורתית שעברו עריכה קפדנית, אלפי תיקים קליניים וזוגות שאלות-תשובות בין רופא לחולה. באמצעות גרסה ברמת בת של אלגוריתם Byte Pair Encoding, המיושמת באמצעות הכלי SentencePiece, הם מאמנים טוקניזר חדש שלומד לשמור ביטויים רפואיים נפוצים יחד כיחידות בודדות. היחידות החדשות הללו, שהמחברים קוראים להן "טוקנים קליניים", מוזגות לאחר מכן לתוך אוצר המילים המקורי של LLaMA2, ומרחיבות אותו כך שיכסה טוב יותר את שפת הרפואה הסינית מבלי לוותר על מה שהמודל ידע כבר.
מטוקנים טובים יותר למודל רפואי טוב יותר
הוספת טוקנים חדשים היא רק הצעד הראשון; על המודל ללמוד ייצוגים טובים עבורם. הצוות מתאים את שכבת ההטבעה הפנימית של LLaMA2 כך שתוכל לאחסן וקטורים עבור אוצר המילים המורחב ובודק שתי דרכים לאתחול הווקטורים החדשים. שיטה אחת ממוצעת את הווקטורים של תת-החלקים הקודמים של כל מילה, בעוד השיטה השנייה משתמשת בערכים אקראיים בקנה מידה מבוקר. בניגוד לאינטואיציה, השיטה האקראית מבצעת טוב יותר, כנראה מכיוון שהיא נמנעת מהתקבעות של המודל על ניחוש התחלתי גרוע לגבי משמעות כל מונח. המחברים ממשיכים לאמן את המודל על טקסט רפואי ומדייקים אותו על שאלות-תשובות רפואיות בסגנון הנחייה באמצעות שיטה חסכונית במשאבים שנקראת LoRA, ומפיקים גרסה מומחית שהם מכנים Medical-LLaMA.
מדידת שיפורים במהירות, בהיקף הקשר ובדיוק
עם אוצר המילים המורחב, כל תו סיני דורש כעת בערך חצי מהטוקנים שהיו דרושים קודם, מה שאומר שהמודל יכול לעבד קטעים ארוכים יותר בתוך חלון טוקנים קבוע. בפועל אורך ההקשר הסיני היעיל מכפיל את עצמו בקירוב, וזמני הדייקון על סט גדול של שאלות-תשובות רפואיות מתקצרים בכמעט חצי. כדי לשפוט את איכות התשובות, המחברים משלבים שתי אסטרטגיות הערכה: BERTScore, שמודד עד כמה תשובה שנוצרה קרובה סמנטית לרפרנס, ודגם דירוג מתוחכם (DeepSeek-R1) שמדרג רלוונטיות, דיוק, שלמות ושטף. על פני מדדים אלה, Medical-LLaMA מתעלה בעקביות הן על LLaMA2 המקורי והן על גרסה מותאמת לסינית שלא כללה טוקנים ספציפיים לרפואה. הוא גם מציג שיפורים קטנים אך יציבים במשימות קרובות כגון זיהוי ישויות רפואיות וסיווג טקסט קליני, וכל זה תוך שמירה על ביצועים בשאלות כלליות לא-רפואיות.
מה זה אומר לעתיד ה-AI הרפואי
ללא-מומחים, המסר המרכזי הוא ש"משקפי קריאה" חכמות יותר עבור AI — כאן, דרך טובה יותר לחתוך את שפת הרפואה — יכולות לשפר במידה ניכרת עד כמה הוא מבין ועונה על שאלות בריאות. על ידי הוספת טוקנים קליניים נבחרים היטב לאוצר המילים של מודל קיים, המחברים משפרים גם את היעילות וגם את הדיוק מבלי לדרוש אימונים חדשים עצומים או ארכיטקטורות חדשות לחלוטין. בעוד שהעבודה מוגבלת למודל בגודל 7 מיליארד פרמטרים ולטקסט רפואי סיני, היא מצביעה על מתכון מעשי: להתאים את השכבה המוקדמת ביותר של עיבוד השפה לתחום, ואז לאמן באופן קל. אסטרטגיה זו עשויה לסייע לכלים רפואיים עתידיים להפוך לשותפים אמינים יותר עבור רופאים ומטופלים, במיוחד בשפות ובמומחיות שבהן מודלים סטנדרטיים מתקשים בקריאה.
ציטוט: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
מילות מפתח: מודלי שפה רפואיים, טקסט קליני בסינית, טוקניזציה, לקסיקון קליני, מענה לשאלות רפואיות