Clear Sky Science · he
ההשפעה של בחירת K ב-K‑fold cross-validation על ההטיה והשונות במודלים של למידה מפוקחת
מדוע בדיקה כפולה של המודל חשובה באמת
מאבחון רפואי ועד דירוג אשראי, החלטות רבות כיום תלויות במודלים של למידת מכונה המאומנים על נתונים היסטוריים. אבל איך נדע שמודל שנראה טוב על המסך יתנהג היטב במקרים חדשים ובלתי נראים? שיטה נפוצה "לבדיקת" מודלים היא k‑fold cross‑validation, שבה מחלקים את הנתונים שוב ושוב לחלקי אימון ובדיקה. המחקר שואל שאלה שנראית פשוטה אך חיונית: כמה חלקים — כמה גדול צריך להיות k — וכיצד הבחירה הזו מעצבת בשקט את אמינות הדיווח על ביצועי המודל?
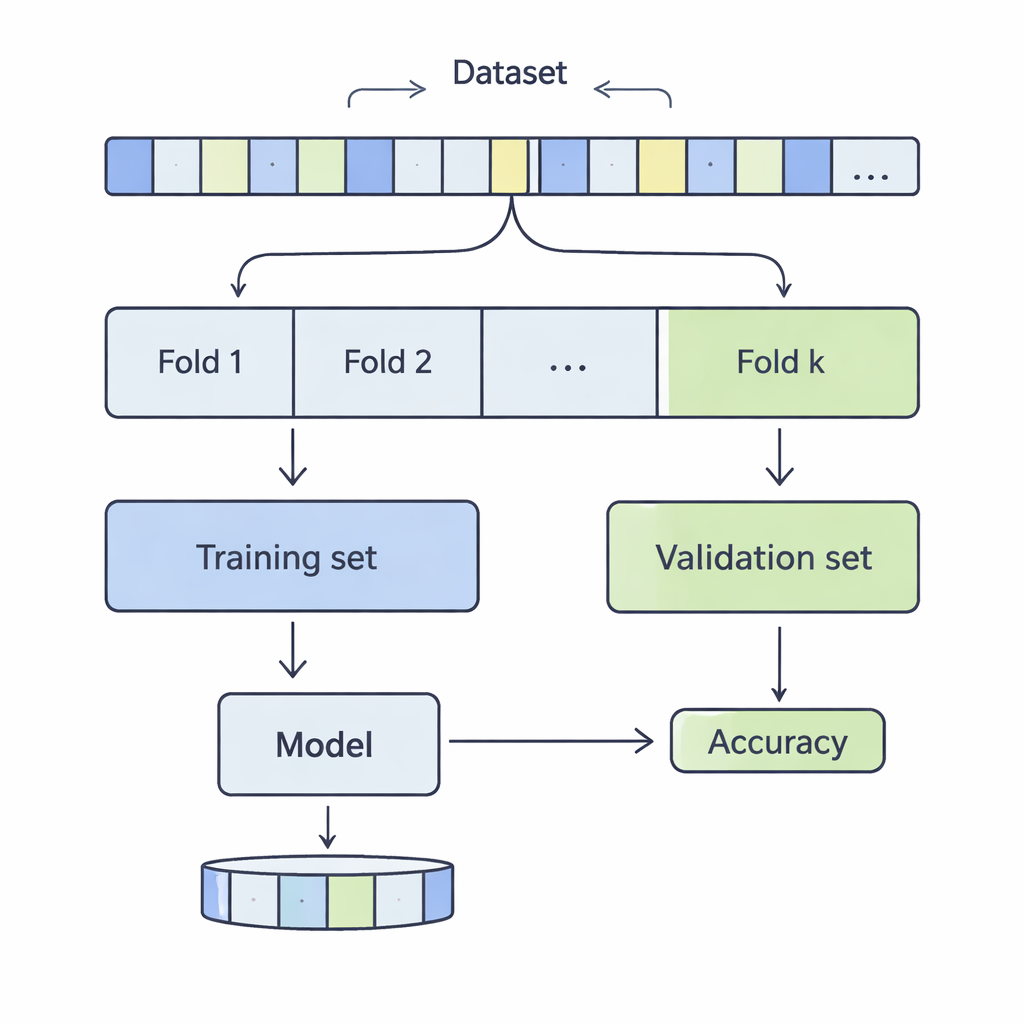
איך חותכים את הנתונים לבדיקת מציאות
ב‑k‑fold cross‑validation מערבבים את מערך הנתונים ומחלקים אותו ל‑k מקטעים שווים, או "קפלים". המודל מאומן על k‑1 מהקפלים ומוערך על הקפל הנותר; התהליך חוזר עד שכל קפל שימש פעם כבוחן. החוקרים בדקו ערכי k מ‑3 עד 20, על פני 12 מערכי נתונים מעשיים שנעו מאלפים בודדים ועד יותר מחצי מיליון רשומות, וכיסו תחומים כמו חיזוי הכנסות, תוצאות רפואיות, התקפות סייבר, משחקים ואיכות יין. הם יישמו ארבע שיטות סיווג מקובלות — Support Vector Machines, Decision Trees, Logistic Regression ו‑k‑Nearest Neighbours — ומדדו בקפידה כיצד הבחירה של k השפיעה על שני היבטים מרכזיים של ביצועים: הטיה ושונות.
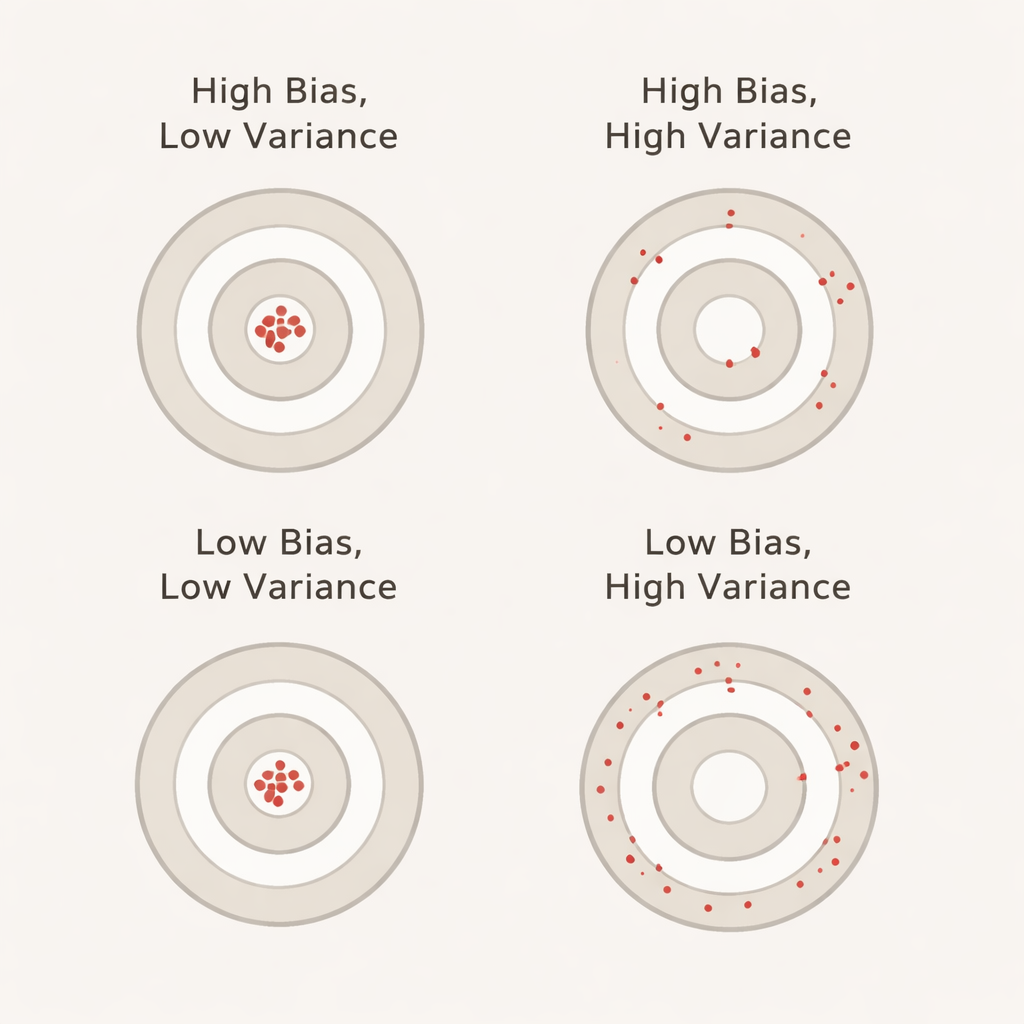
מה משמעות ההטיה והשונות במונחים יומיומיים
ההטיה, בהקשר זה, לוכדת עד כמה המודל נראה טוב יותר במהלך ה‑cross‑validation מאשר הוא באמת על מערכת בדיקה נפרדת שלא נגעה בה. הטיה חיובית גדולה משמעותה שהמודל נראה אופטימי מדי בזמן ולידציה — בדומה לתלמיד שמצטיין במבחני תרגול אך מתקשה במבחן האמיתי. השונות משקפת עד כמה ביצועי המודל קופצים מקפל לקפל: שונות נמוכה פירושה שהציונים יציבים בין פרוסות שונות של הנתונים, בעוד ששונות גבוהה פירושה שהם מתנודדים. באופן אידיאלי אנו רוצים גם הטיה נמוכה וגם שונות נמוכה כדי שהדיוק המדווח יהיה גם ריאלי וגם יציב.
מה קורה כשמגבירים את מספר הקפלים
בכל 12 מערכי הנתונים ובכל ארבעת האלגוריתמים דפוס אחד בלט בחוזקה: ככל ש‑k גדל, השונות כמעט תמיד עלתה. במילים אחרות, שימוש ביותר קפלים גרם לכך שהדיוק המדווח הפך לפחות יציב מקפל לקפל. זה סותר אמונה נפוצה שהגברה במספר הקפלים בהכרח תיתן אומדנים טובים ומהימנים יותר. הסיבה היא שכאשר k גדול, כל קטע ולידציה נהיה קטן מאוד ופחות מייצג, ולכן התוצאות רגישות יותר לאקצנטריות בנתונים. בו‑זמנית, ההטיה התנהגה פחות אחיד. עבור k‑Nearest Neighbours ו‑Support Vector Machines, ההטיה נטתה לעלות עם גדילת k, כלומר מודלים אלו לעתים נראו מדויקים יותר ב‑cross‑validation משהיו על קבוצת המבחן המוחזקת. Decision Trees הראו דפוסים מאוזנים באופן גס, ו‑Logistic Regression נמצאה באמצע, עם שינויים מעורבים אך מתונים יותר בהטיה.
מדוע "ההגדרות הסטנדרטיות" עלולות להטעות
מרבית המדריכים הפרקטיים ממליצים פשוט להשתמש בחמישה או עשרה קפלים, ללא קשר למערכת הנתונים או לאלגוריתם הלמידה. הניתוח של המחברים מראה שעצה מסוג "מידה אחת מתאימה לכולם" יכולה להטעות. במערכי נתונים מסוימים ועבור מודלים מסוימים, ערכי k גבוהים הגבירו רושם יתר אופטימי של הביצועים; בכל המקרים, יותר קפלים הביאו לעלייה בתנודתיות באמדנים. זו בעיה במיוחד בתחומים בעלי סיכון גבוה כגון בריאות, פיננסים או תשתיות, שבהם ביטחון שווא בדיוקו של מודל עלול לגרום לתוצאות בעולם האמיתי. המחקר טוען שההשפעות של k תלויות גם באופי הנתונים (קטנים מול גדולים, רועשים מול נקיים יותר) וגם באופן שבו האלגוריתם הספציפי לומד מערכות אימון חזרניות, כמעט זהות.
קצר ולעניין למי שמשתמש בלמידת מכונה
הלקח המרכזי הוא שמספר הקפלים ב‑cross‑validation אינו פרט טכני חסר חשיבות — הוא מעצב ישירות עד כמה ניתן לסמוך על מספרי הדיוק שדוחפים. בניסויים אלו, יותר קפלים באופן עקבי הפכו את התוצאות לפחות יציבות ולעתים גרמו לכך שחלק מהמודלים נראו טובים יותר ממה שהם באמת. במקום לבחור בעיוורון k=5 או k=10, המחברים ממליצים להתייחס ל‑k ככפתור כיוונון: לבדוק כיצד התוצאות משתנות בין טווח קטן של ערכי k ולבחון, כאשר אפשרי, יותר ממדד ביצוע אחד. עבור פרקטיקאים וקוראים סקרנים כאחד, המסר ברור: כשמבחנים מודלי למידת מכונה — הדרך שבה אתם חותכים את הנתונים יכולה להיות חשובה כמעט כמו המודל עצמו.
ציטוט: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
מילות מפתח: k-fold cross-validation, bias-variance trade-off, model evaluation, machine learning validation, supervised classification