Clear Sky Science · he
בחירת תכונות פשוטה, מהירה ויעילה מונחית אשכול מטושטש אדפטיבי עבור נתוני מיקרואראיי ביואינפורמטיים בינאריים בעלי מימדים גבוהים ואי‑איזון קיצוני
מדוע זה חשוב למחקר גנים
מבחני ביטוי גנים מודרניים יכולים למדוד עשרות אלפי גנים בדגימה יחידה של מטופל. הצפה זו של נתונים מבטיחה אבחון מוקדם יותר של סרטן ובחירות טיפול טובות יותר, אך גם יוצרת בעיה: רוב הגנים רעשיים, עודפים או קשורים בעיקר למקרים השכיחים ולא לאלו הנדירים והמסוכנים. המאמר מציג שיטה חדשה לסינון מאגרי נתוני ביטוי‑גנים ענקיים, כך שמחשבים יוכלו לזהות באופן מהימן מטופלים בקבוצה קטנה וקשה‑לזיהוי באמצעות סט זעיר ונבחר בקפידה של גנים.
האתגר של יותר מדי גנים דומים
ניסויי מיקרואראיי מנטרים לעיתים אלפי רמות פעילות גנים עבור רק כמה מאות מטופלים. בדרך כלל, כיתה אחת (כמו תת‑סוג סרטן נפוץ) עולה בהרבה על השנייה, ויוצרת נתונים בעלי אי‑איזון חזק. במסגרת זו, רבים מהגנים מתנהגים באופן דומה מאוד, והתבניות של המטופלים ברוב ושל המיעוט יכולות לחפוף. שיטות למידה סטנדרטיות נוטות להיקשר לכיתה הרוב ולהיות מבלבלות מבחינת גנים מיותרים, מה שיוביל להטייה יתר ולזיהוי לקוי של תת‑סוגים נדירים. שיטות מסורתיות לצמצום מימדים או מייצרות תכונות מעורבבות שאיבדו את הפענוח הביולוגי, או בוחרות גנים מבלי לבדוק מקרוב עד כמה הם עוזרים למיין את מקרים המיעוט.
מפת דרכים חדשה לבחירת גנים חכמה יותר
המחברים מציגים AFCG‑SFE, מודל בחירת תכונות אדפטיבי שתוכנן במיוחד עבור נתוני ביטוי‑גנים בעלי מימדים גבוהים ואי‑איזון. השיטה מתחילה מחיפוש פשוט של "סוכן יחיד" שמדליק או מכבה גנים ובודק כמה הם תומכים במיון, אך מעשירה זאת בכמה שלבים מונחי‑נתונים. ראשית, היא מקבצת גנים לפי דמיון בהתנהגות, ואז מאפשרת לגנים להשתייך ליותר מקבוצה אחת כדי לשקף את המצב הביולוגי שבו גן עשוי להיות מעורב במסלולים מרובים. בתוך כל קבוצה היא מדרגת את הגנים לפי מידת המידע שלהם לגבי תווית המחלה ושומרת רק נציגים מרכזיים מעטים, חותכת באופן דרסטי את העודף לפני שהחיפוש הראשי מתחיל. 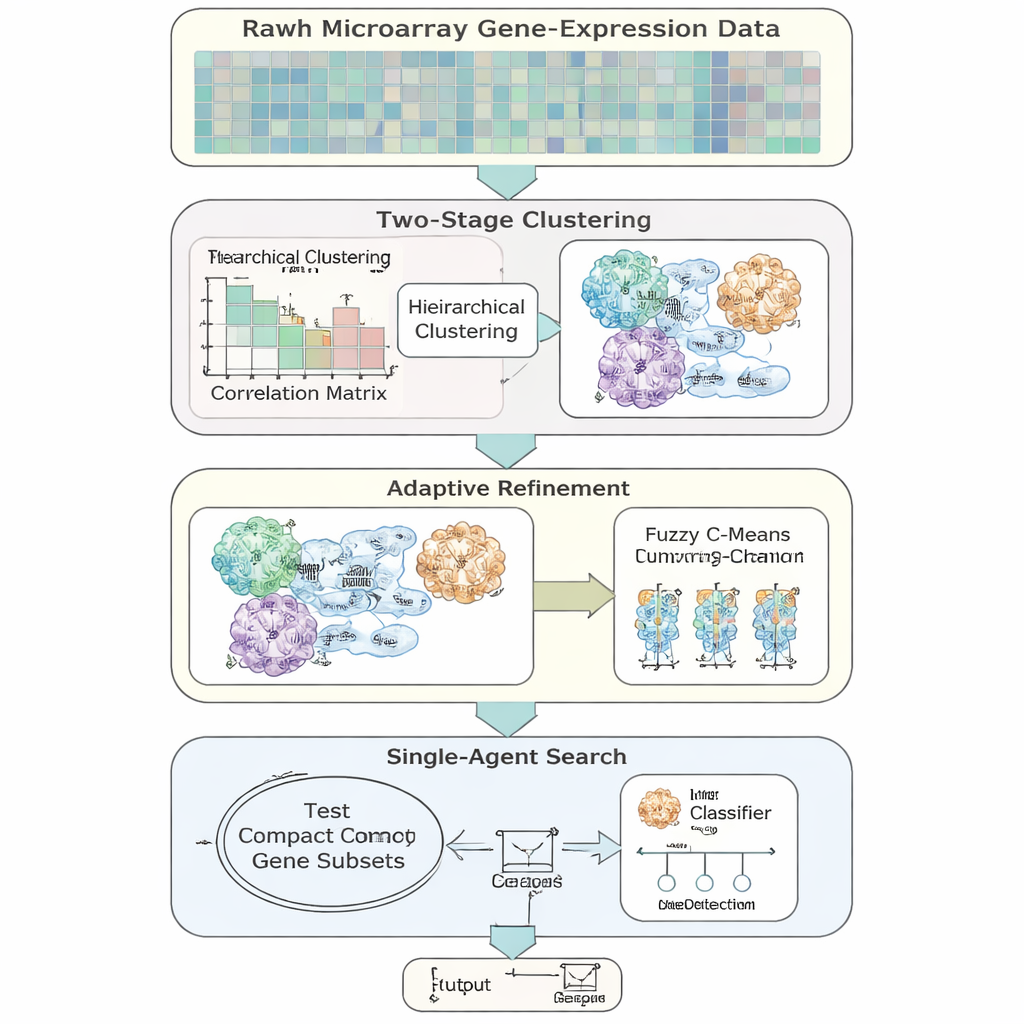
לעשות את המחשב אכפתי מהמקרים הנדירים
במקום להתמקד בדיוק הגולמי, AFCG‑SFE משתמשת בציון כושר שמדגיש מדדים מותאמים לנתונים מעוקלים, כולל איזון בין זיהוי נכון של מקרים מהמיעוט והרוב וביצועים על פני כל ספי ההחלטה. פונקציית הכושר כוללת גם עונשים על בחירת יותר מדי גנים או על בחירת הרבה גנים מאותו אשכול, וכן תגמול על גנים שנושאים תלות חזקה בתווית המחלה. חשוב שהעוצמה של עונשים ותגמולים אלה נקבעת אוטומטית על פי מאפייני מערך הנתונים — כמו כמה גנים יש לכל מטופל ועד כמה הכיתות חופפות — במקום כוונון ידני. זה הופך את השיטה ליציבה יותר וקלה להעברה בין מחקרים.
הסתגלות לקושי הבעיה
רעיון מרכזי הוא שהאלגוריתם לא תמיד צריך לשאוף לסט הגנים הקטן ביותר האפשרי. כאשר שתי הכיתות קשה מאוד להפריד או חופפות במידה רבה, השיטה מעלה באופן אוטומטי גבול תחתון על כמות הגנים שיש לשמור, כדי להבטיח שלא ייזרקו איתותים נדירים אך חשובים. ככל שהחיפוש מתקדם, AFCG‑SFE מהדק בהדרגה תקרת‑על לכל אשכול לגבי כמה גנים יכולים לשרוד מכל קבוצה, תוך שמירה על המינימום הזה. התוצאה היא פאנל גנים קומפקטי ומגוון שתופס את מבנה הנתונים בלי להישלט על‑ידי דפוס יחיד וחד‑ממדי. 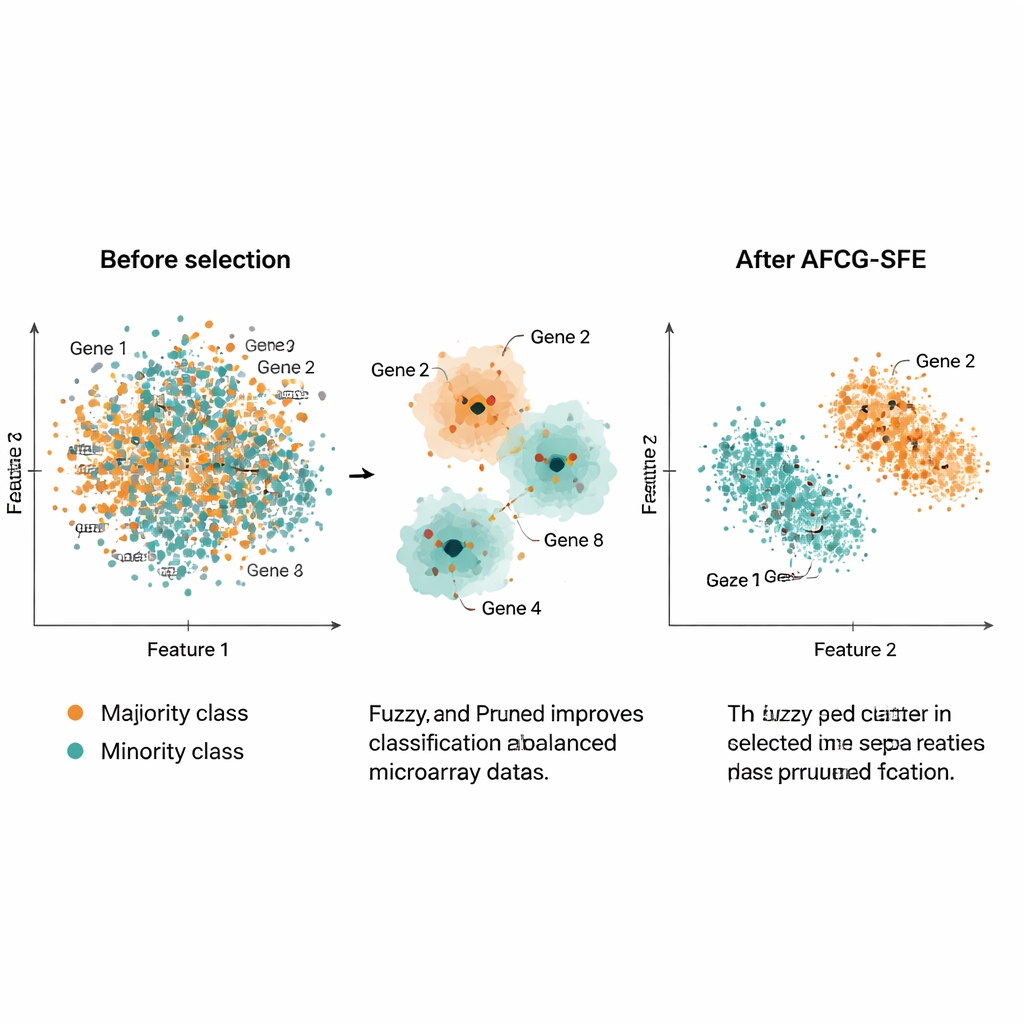
מה הניסויים מראים
המחברים בדקו את AFCG‑SFE על 20 מערכי מיקרואראיי ציבוריים של סרטן, כל אחד עם אלפי גנים אך רק כ‑100–200 מדגמים וחוסר איזון כיתתי חזק. הם השוו את השיטה שלהם למספר בסיסים של חיפוש אבולוציוני, מסננים פשוטים ושיטות משובצות שבונות בחירת תכונות לתוך המיון עצמו. במגוון מדדים — כולל F‑measure, דיוק מאוזן, שטח מתחת לעקומת ROC ומדד להטיית יתר — AFCG‑SFE הייתה הטובה ביותר או התאמה לטובה ביותר בכל מערכי הנתונים. בדרך כלל היא בחרה פחות מ‑25 גנים (לעיתים רק 6–8), והסירה יותר מ‑99% מהתכונות המקוריות תוך שיפור או שמירה על ביצועי המיון. כמו כן היא הקטינה מדד מורכבות שמייצג עד כמה הכיתות חופפות במרחב התכונות, מה שמעיד על הפרדה ברורה יותר לאחר הבחירה.
המסקנה לקוראים לא‑מומחים
במונחים מעשיים, עבודה זו מציעה דרך לכווץ פרופילי ביטוי‑גנים ענקיים ורועשים לסטים קטנים מאוד של גנים אינפורמטיביים שמאפשרים עדיין למחשבים לזהות בקביעות תת‑קבוצות מטופלים נדירות. על‑ידי קיבוץ חכם של גנים דומים, תגמול של אלה שעוקבים באמת אחרי המחלה והגנה מפני הטייה לטובת כיתת הרוב, AFCG‑SFE מספקת גם חיזוי טוב יותר וגם לוחות גנים הרבה יותר פשוטים. שילוב זה יכול לעזור לחוקרים לזהות סמני ביולוגיים פוטנציאליים, לעצב בדיקות אבחון ברורות יותר ובסופו של דבר לשפר את אופן הפעולה של כלי הרפואה המדויקת עם נתונים ביולוגיים אמיתיים וחסרי‑שלמות.
ציטוט: Tye, Y.W., Chew, X., Yusof, U.K. et al. Adaptive fuzzy cluster-guided simple, fast, and efficient feature selection for high-dimensional and highly imbalanced binary-class bioinformatics microarray data. Sci Rep 16, 6650 (2026). https://doi.org/10.1038/s41598-026-37086-w
מילות מפתח: ביטוי גנים, בחירת תכונות, נתונים בלתי מאוזנים, מיקרואראיי, תתי‑סוגי סרטן