Clear Sky Science · he
מודל שפה גדול מונחה ידע ליצירת תכניות אימון ספורט מותאמות אישית
תכניות אימון חכמות יותר לאנשים רגילים
רוב אפליקציות הכושר מבטיחות התאמה אישית, אך רבות מהן עדיין מסתמכות על תבניות כלליות שמתעלמות מהמצב הגופני האמיתי שלך. מאמר זה מציג את LLM-SPTRec, מערכת חדשה שמשתמשת בסוג המודלים של שפה גדול שמאחורי צ׳אבטים מודרניים, בשילוב עם ידע מאומת במדעי הספורט ונתוני מכשירים לבישים, כדי לבנות תכניות אימון בטוחות ויעילות יותר. לכל מי שהתלבט מדוע האפליקציה מציעה תרגילים לא מתאימים — או דאג האם עצות בריאות שמיוצרות על ידי בינה מלאכותית באמת בטוחות — עבודה זו מראה כיצד להפוך אימון דיגיטלי ליותר אישי ומדעי.
מדוע אפליקציות כושר מסורתיות לא עונות על הצורך
מנועי המלצות מסורתיים, כמו אלה שמציעים סרטים או מוצרים, מתקשים כשהם מיושמים על פעילות גופנית. הם לעתים קרובות מעתיקים ומשתמשים שוב בתבניות סטנדרטיות, מתקשים לטפל בנתונים מוגבלים עבור משתמשים חדשים, ולעתים רחוקות בוחנים כיצד גופך משתנה מיום ליום. גרוע מזה — הם לא תוכננו לקבלת החלטות בעלות סיכון גבוה שבהן בטיחות חשובה. מודלים לשוניים כלליים טובים בדיבור על אימונים, אך מכיוון שאומנו על טקסט מקיף מהאינטרנט, הם עלולים "להזות" עצות מסוכנות או לדלג על ימי מנוחה חשובים. המחברים טוענים שעבור תכנון אימון — שבו הדרכה לקויה עלולה לגרום לפציעות או להעמסה יתר — יש להנחות את הבינה המלאכותית בידע מאומת במדעי הספורט ולעקוב אחרי מצב המשתמש בזמן.
בניית תמונה עשירה של הפרט
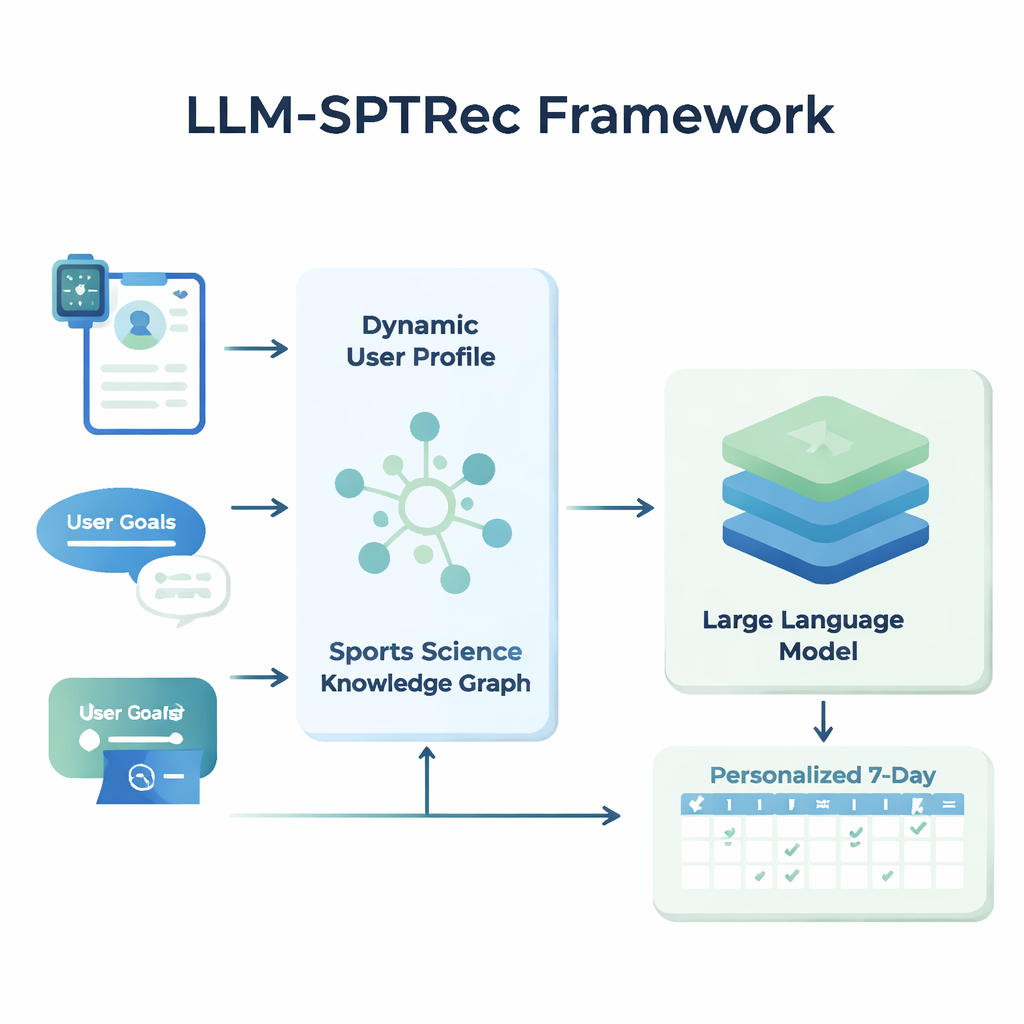
בלב LLM-SPTRec נמצא מודול שיוצר תמונת מצב מפורטת של כל משתמש. במקום לאחסן רק גיל, מין או רמת ניסיון, המערכת מאחדת שלושה סוגי מידע: תכונות סטטיות (כמו היסטוריית אימונים), אותות דינמיים (כדוגמת דופק, שונות דופקית, ציון שינה ואימונים קודמים ממכשירים לבישים ורישומים), ויעדים בטקסט חופשי שכתב המשתמש. מודל מבוסס טרנספורמר — קרוב לטכנולוגיה שמאחורי מודלי השפה המודרניים — לומד דפוסים בנתוני סדרות זמנים אלה, כגון כיצד אימון קשה אתמול עשוי להשפיע על מוכנות היום. מנגנון תשומת לב (attention) שוקל אז אילו אותות חשובים ברגע נתון, ומשלב אותם לייצוג מספרי יחיד של מצבו הנוכחי של המשתמש.
הוראת הבינה המדע הספורטיבי האמיתי
כדי למנוע המלצות לא בטוחות או לא מדעיות, החוקרים בנו גרף ידע במדעי הספורט — במלים אחרות מפה מובנית של עובדות שאושרו על ידי מומחים. הוא כולל אלפי רשומות שמקשרות בין תרגילים לשרירים, סוגי תנועה, ציוד, פציעות נפוצות ועקרונות אימון כמו עומס מתגבר וספציפיות. עבור כל משתמש, המערכת מחלצת את החלקים הרלוונטיים ביותר מהגרף — כגון אילו שרירים מיועדים לבןץ' פרס ואילו תנועות מסוכנות לבעיות בכתף — והופכת אותם לטקסט קריא שנכנס למודל השפה לצד פרופיל המשתמש. לאחר מכן המודל נתבקש, דרך פרומפט מעוצב בקפידה, ליצור תכנית אימון מרובת ימים בפורמט מובנה, תוך ציות לכללים כמו סירוג קבוצות שרירים בין הימים והימנעות מניגודים ידועים.
שמירה על מבנה, בטיחות ושיפור לאורך זמן
LLM-SPTRec עושה יותר מיצירת טקסט בלבד. מודול אימות בודק כל תכנית מול כללים נוקשים, כמו אי-עומס על אותם קבוצות שרירים ראשיות ברצף ימים, ומסמן סתירות עם סיכוני פציעה השמורים בגרף הידע. אם תכנית נכשלה בבדיקות אלה, המערכת מציגה את ההנחיות למודל שוב, מציינת במפורש מה השתבש, עד שמופקת תכנית בטוחה. אימון המערכת מתבצע גם הוא בשני שלבים. תחילה היא לומדת מאוסף גדול של תכניות שנוצרו על ידי מומחים. לאחר מכן היא מעודנת further באמצעות משוב, שבו דירוגים מדומים או אמיתיים של משתמשים מדרבנים תכניות קוהרנטיות, מותאמות למטרות ומהנות לעקיבה, בעוד שהצעות לא בטוחות מקבלות עונש כבד. לולאת המשוב הזו דוחפת את המודל להמלצות שעובדות טוב יותר בפועל.
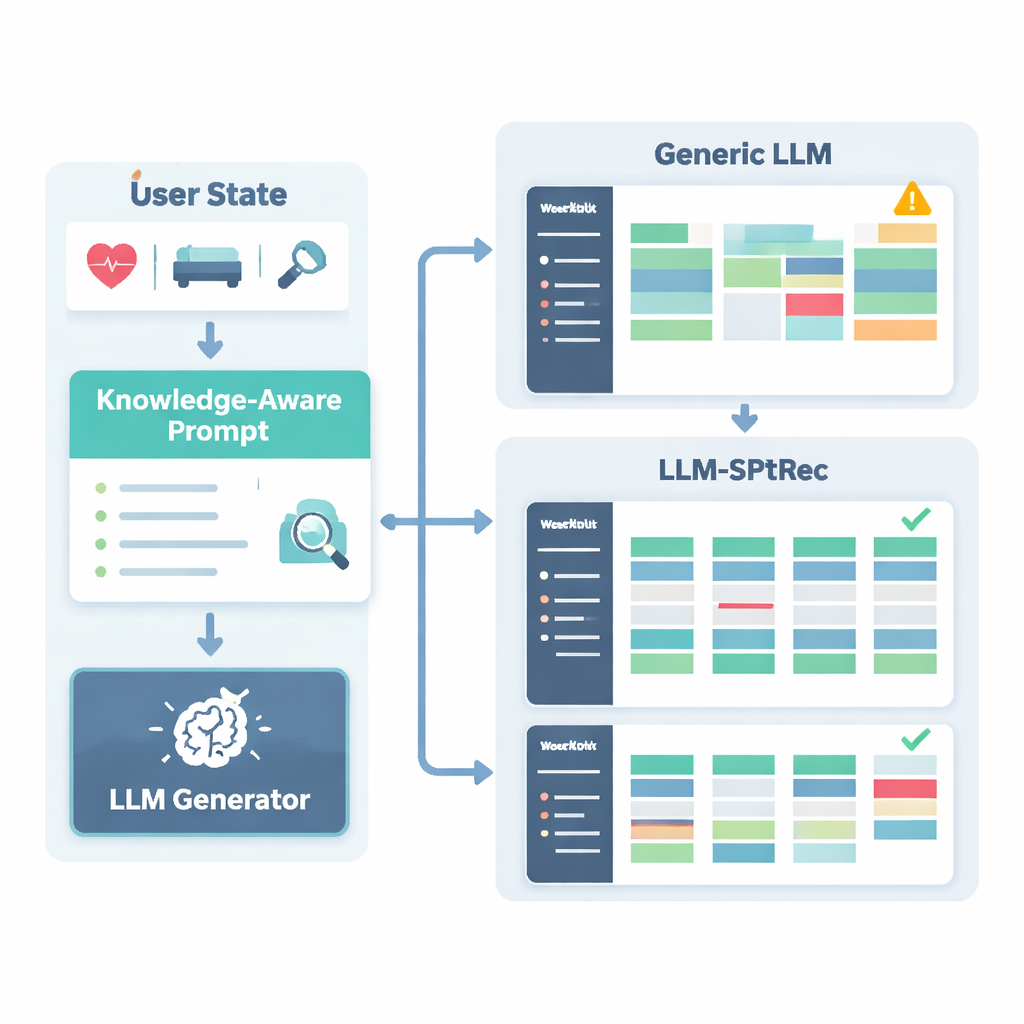
כמה יעילה המערכת בפועל
המחברים בחנו את LLM-SPTRec על מאגר נתונים גדול מהעולם האמיתי בשם SportFit-1M, שמשלב נתונים אנונימיים מאפליקציות כושר וממכשירים לבישים, כולל עשרות אלפי משתמשים ומיליוני רישומי אימון ומדדים פיזיולוגיים. הם השוו את המערכת שלהם עם בסיסים חזקים: פילטרציה שיתופית קלאסית, מודל רצף שבודק רק בחירות קודמות, ממליץ מתקדם מבוסס גרף ידע, ומסגרת מבוססת מודל שפה כללי. LLM-SPTRec ניצח את כולם לא רק בבחירת התרגילים המתאימים, אלא — ומה שחשוב יותר — ביצירת תכניות מלאות שמומחים העריכו כיותר קוהרנטיות ובהתאמה טובה יותר למטרות המשתמש. נקודות שביעות רצון משתמשים צפויות היו גבוהות יותר גם כן, ולמחקר אנושי קטן עם מאמנים מוסמכים דירג את הבטיחות שלו כטובה בהרבה מזו של מודל שפה כללי ללא עיגון ספורט-ספציפי.
מה משמעות הדבר לאימוני דיגיטל בעתיד
עבור הקורא הפשוט, המסקנה היא שאימון בינה מלאכותית חכם ובטוח יותר אפשרי כאשר שלושה מרכיבים נפגשים: נתונים עשירים מהמכשירים שלך, מדעי ספורט מומחים המקודדים כידע מובנה, ומודלי שפה רבי עוצמה שיצירתיותם מנותבת ונבדקת בקפידה. LLM-SPTRec מראה ששילוב כזה יכול לייצר תכניות אימון אדפטיביות יום-יום שמכבדות את מצבו המשתנה של גופך ואת יעדיך האישיים, תוך הקטנת הסיכון לעצות מזיקות או לא הגיוניות. בהסתכלות קדימה, אותה מתכונת יכולה להרחיב מעבר לאימונים גם לתזונה, שיקום מפציעות, ואפילו בריאות נפשית, ומצביעה על עתיד שבו העוזרים הדיגיטליים פועלים פחות כאילו הם צ׳אבטים כלליים ויותר כמאמנים דיגיטליים ממוקדי ידע וזהירים מבחינת בטיחות.
ציטוט: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
מילות מפתח: אימון מותאם אישית, בינה מלאכותית למדעי הספורט, המלצות כושר, נתוני מכשירים לבישים, גרף ידע