Clear Sky Science · he
התפתחות זיהוי האובייקטים מ-CNNים למטא-טרנספורמרים ולמיזוג מולטימודלי
להנגיש למחשבים ראיית חפצים יומיומיים
כל פעם שהטלפון שלכם מתייג חברים בתמונה, רכב מזהה הולך רגל, או כלי רפואי מסמן גוש חשוד בסריקה — טכנולוגיה עוצמתית ושקטה עובדת מאחורי הקלעים: זיהוי אובייקטים. מאמר הסקירה הזה מסביר כיצד זיהוי האובייקטים התפתח במהירות בעשור האחרון, מתעלולי עיבוד תמונה מוקדמים למערכות מבוססות טרנספורמרים וחיישנים מרובים כיום, ולמה ההתקדמות הזו חשובה לרחובות בטוחים יותר, רובוטים חכמים יותר, ואבחונים רפואיים מדויקים יותר.
מפיקסלים לדברים ברי־הכרה
זיהוי אובייקטים הוא המשימה של איתור ותיאור פריטים ספציפיים בתמונות או בוידאו — רכבים, רוכבים, חיות, מבנים רפואיים ועוד. המאמר מתחיל במיפוי השימושים הנרחבים של היכולת הזו: בנהיגה אוטונומית, במערכות מעקב, בהדמיה רפואית וברובוטיקה. מערכות מוקדמות הסתמכו על כללים מעשה-יד לבחירת צורות ומרקמים, אך הגישות המודרניות לומדות ישירות מהנתונים באמצעות למידה עמוקה. כיום שולטות שתי משפחות עיקריות: רשתות עצביות מבוססות קונבולוציה (CNN), שעושות עבודה מצוינת בזיהוי דפוסים מקומיים כמו קצוות ופינות; וטרנספורמרים, שמתמחים בהבנת הסצנה הרחבה וביחסים בין אובייקטים מרוחקים. יחד הן מגדירות כיצד המכונות "רואות" את העולם כיום.
איך מנועי הראייה הקלאסיים עובדים
שיטות מבוססות CNN עדיין מזינות רבות מהיישומים בזמן אמת. הן סורקות תמונות עם פילטרים קטנים כדי לבנות מפות תכונות עשירות יותר ויותר, ואז מעבירות אותן לראשים של זיהוי שמציירים תיבות מסובבות ומקצים תוויות. הסקירה מסבירה שתי אסטרטגיות עיקריות. מערכות דו-שלביות כמו Faster R-CNN מציעות קודם אזורים סבירים לאובייקטים, ואז משפרות אותם, לעתים בהשגת דיוק גבוה במחיר חישובי. מערכות חד-שלביות כמו משפחת YOLO מדלגות על שלב ההצעה וצופות תיבות ותוויות במעבר אחד, מה שמקריב מעט מהדיוק כדי לרוץ מהר יותר. גרסאות עדכניות של YOLOv5 ו-YOLOv8 עברו כוונון נרחב — הוספת פירמידות תכונות חכמות לאובייקטים קטנים, יחידות בנייה קלות למכשירי קצה, ופונקציות אובדן משופרות — כדי להגיע למאות פריימים לשנייה תוך שמירה על תחרותיות במבחנים קשים.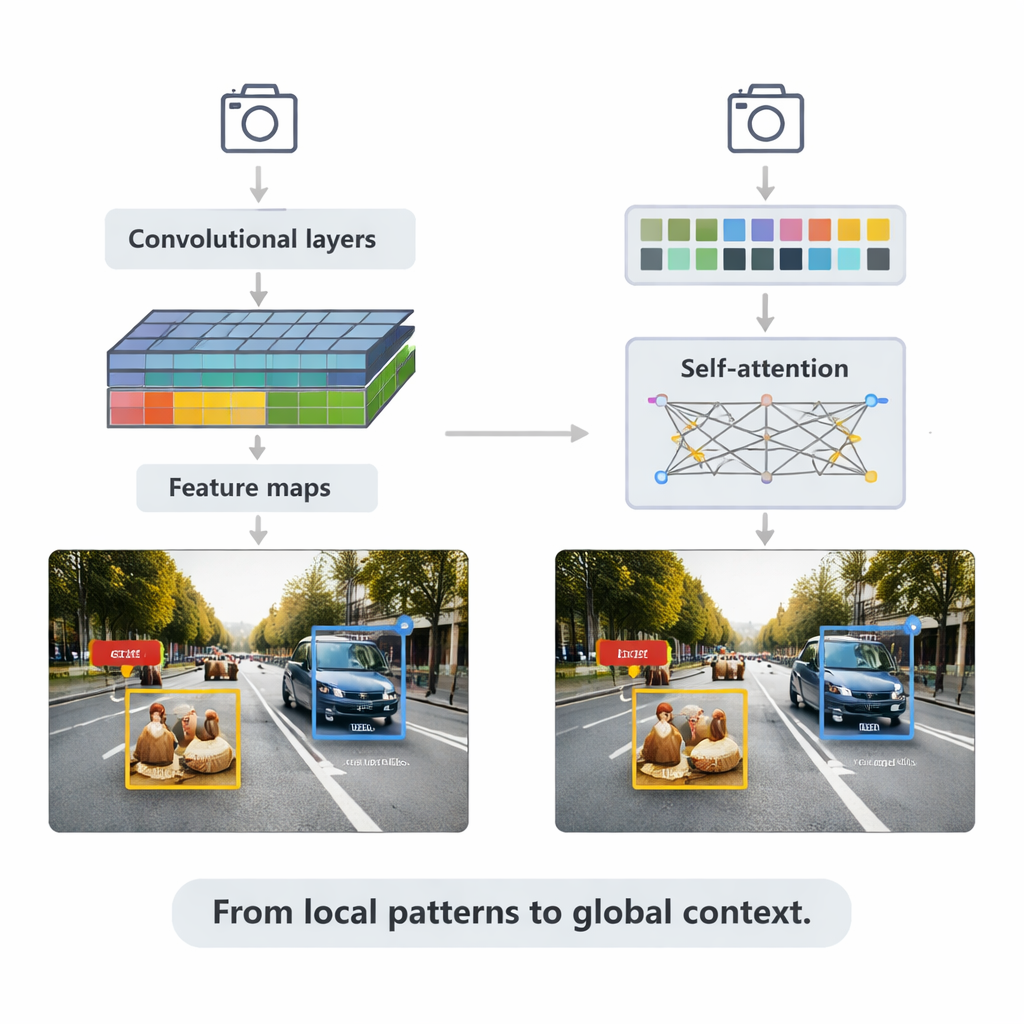
טרנספורמרים וכוח ההקשר
המאמר פונה לאחר מכן לטרנספורמרים, ארכיטקטורה חדשה יותר שאומצה ממודלים לשפה. במקום להתמקד רק בשכנות מקומיות, טרנספורמרים משתמשים ב"שימת לב עצמית" כדי להשוות כל חתיכת תמונה לכל חתיכה אחרת, וללמוד אילו אזורים רלוונטיים לכל החלטה. Detection Transformer (DETR) והיורשים שלו מסירים רבים מהטריקים המעוצבים ידנית, במטרה לקבל צינורות נקיים מקצה לקצה. וריאנטים כמו Deformable DETR ו-RT-DETR מקטינים את ההוצאה החישובית ומשפרים את מהירות האימון, מה שמאפשר לטרנספורמרים לפעול בזמן אמת ולהשיג חלק מהציון הדיוק הגבוה ביותר בבנצ׳מרק הנפוץ COCO. מודלים אלה מצטיינים במיוחד בסצנות מורכבות עם אובייקטים חופפים ורקעים מבלבלים, שבהן ההקשר הגלובלי עוזר להבחין, למשל, בהולך רגל החלקית מוסתר מאחורי רכב.
לשלב מצלמות, לייזרים ושפה
תנאי העולם האמיתי — ערפל, חושך, השתקפויות, עומס חזותי — לעיתים קרובות מנצחים מערכות חיישן יחיד. מוקד מרכזי בסקירה הוא מיזוג מולטימודלי: שילוב נתונים מצלמות רגילות (RGB), חיישני עומק כמו LiDAR, מצלמות תרמיות ואפילו תיאורים טקסטואליים. המחברים מציגים טקסונומיה ברורה לאופן שבו המיזוג הזה יכול להתרחש: מיזוג מוקדם מערבב נתונים גולמיים מראש, מיזוג אמצעי מאחד תכונות שלמדו בתוך הרשת, ומיזוג מאוחר משלב את תוצרי הגלאים הנפרדים בסוף. "טרנספורמרי מיזוג" מודרניים משתמשים במנגנוני תשומת לב כדי ליישר את הזרמים הללו, כך שמדידות מרחק חדות מליידר, הופעה עשירה מתמונות RGB ורמיזות סמנטיות משפה יחזקו זו את זו. גישה זו משפרת זיהוי בנהיגה אוטונומית, בהדמיה רפואית, בהבנת וידאו ובסצנות עשירות בטקסט.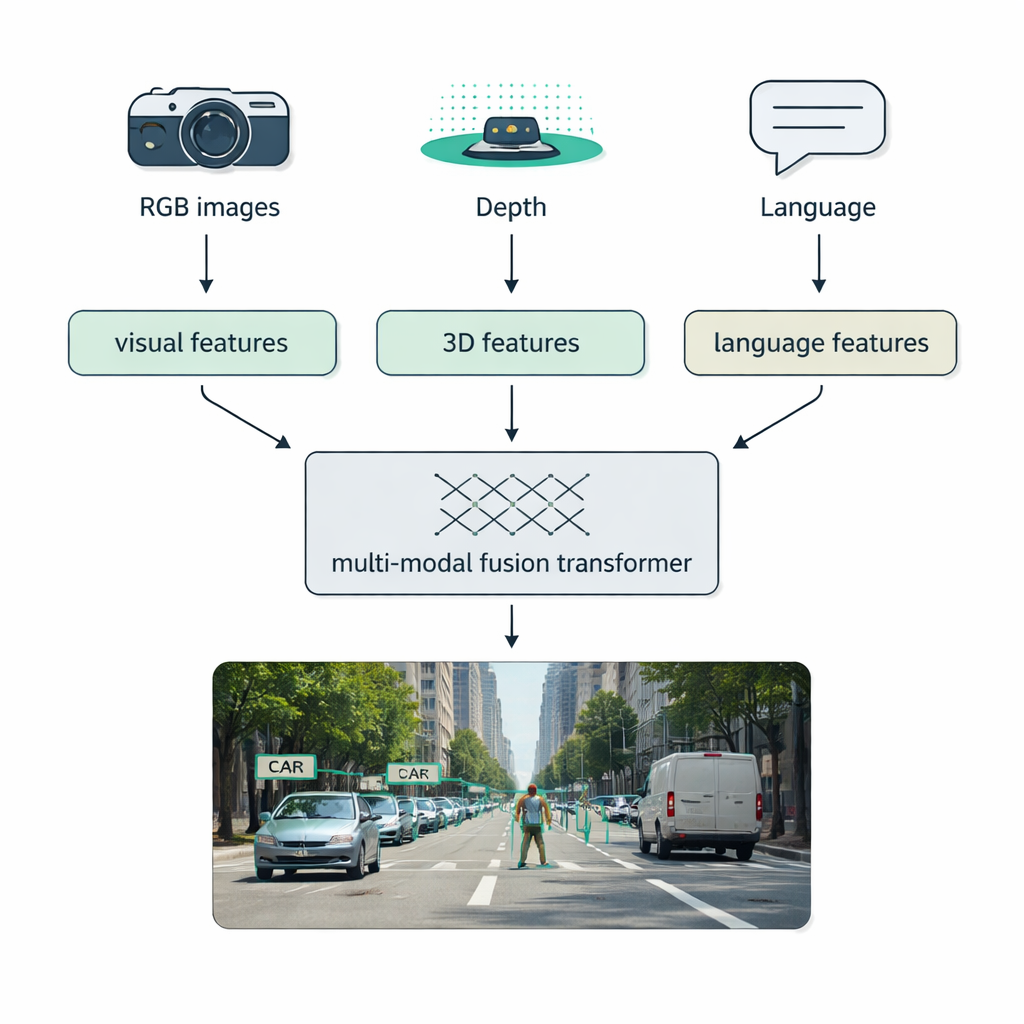
בנצ׳מרקים, מגבלות ומה הלאה
במבחנים סטנדרטיים כמו MS COCO, הסקירה משווה בין גלאי CNN וטרנספורמר גם לפי דיוק וגם לפי מהירות. CNNים דו-שלביים קלאסיים נשארים חזקים אך איטיים יותר, מודלים בסגנון YOLO שומעים על חומרה קלה, ומערכות מבוססות טרנספורמר מובילות כיום בדיוק תוך צמצום פער המהירות. שיטות אינפרא‑אדום מיוחדות משיגות ציונים גבוהים בתנאי ראות נמוכה. עם זאת, בעיות קשות נשארות: אובייקטים זעירים או עצומים במיוחד, חסימות כבדות, שינויי מזג אוויר ותאורה, והצורך לרוץ באופן אמין על מכשירים זעירים. הביט קדימה, המחברים מדגישים מגמות לכיוון מודלים מאוחדים לתפיסה המטפלים בזיהוי, סגמנטציה ותיאוריות יחד, ו"מודלי יסוד" שממזגים ראייה ושפה כדי לזהות אובייקטים המתוארים בטקסט פשוט, גם אם הם לא תוייגו בנתוני האימון.
למה זה חשוב בחיי היומיום
עבור קהל שאינו מומחה, המסר המרכזי הוא כי זיהוי האובייקטים עובר ממערכות צרות ומכוונות ידנית למנועי ראייה גמישים ורב-תכליתיים שיכולים להסתגל למשימות חדשות, לסביבות חדשות ולחיישנים חדשים. CNNים מספקים זיהוי דפוסים מהיר ויעיל; טרנספורמרים מוסיפים הבנה גלובלית ומודעת להקשר; ומיזוג מולטימודלי מקשר רמזים נוספים מעומק, טמפרטורה ושפה. יחד, ההתקדמויות האלה מבטיחות רכבים שמצפים טוב יותר לסכנות, כלים המסייעים לרופאים בביטחון גדול יותר, ומכשירי בית המגיבים בצורה בטוחה וחכמה יותר לסביבתם — מקרבים את תפיסת המכונה לעושר הראייה האנושית.
ציטוט: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
מילות מפתח: זיהוי אובייקטים, מחשוב חזותי, למידה עמוקה, מודלים מבוססי טרנספורמר, מיזוג מולטימודלי