Clear Sky Science · he
קריטריון להערכת יעילות שאילת שאלות דיאגנוסטיות של מודלים גדולים בשיחות עם מטופלים
מדוע שאלות רפואיות חכמות חשובות
כשאתה מבקר אצל רופא, האבחנה הראשונה שאתה שומע נדירה תהיה מבוססת על תסמין יחיד שציינת. במקום זאת, רופאים שואלים סדרת שאלות המשך — על תזמון, עוצמה, בעיות נלוות — כדי לצמצם בהדרגה מה עלול להיות לא בסדר. על אף העוצמה של מערכות ה-AI של היום, מרביתן עדיין נבחנות כאילו הן עונות לבחינות רב־ברירתיות, ולא כמנהלות שיחה עם בני אדם אמיתיים. מאמר זה מציג את Q4Dx, שיטה חדשה לשפוט עד כמה מודלים לשוניים גדולים (LLMs) יכולים לשחק את "הרופא הסקרן": לבחור את השאלות הנכונות, בסדר הנכון, כדי להגיע לאבחנה נכונה בצורה יעילה.
משאלות בחינה לשיחות אמיתיות
מרבית מבחני ה-AI הרפואיים הקיימים מציגים למודלים מקרים מסודרים ומפורטים — כמו בעיה מתוך ספר לימוד — ומבקשים לבחור אבחנה. זה מראה מה המערכת "יודעת", אבל לא איך היא תתנהג בשיחה חסרת סדר עם מטופל ששוכח פרטים או מתאר תסמינים בשפה יומיומית. המחברים טוענים שזו נקודת עיוורון משמעותית. במרפאות המידע עולה לאט ולעתים באופן לא מדויק; מיומנות קלינית טובה תלויה לא פחות במה ששואלים כמו במה שידוע מראש. Q4Dx תוכנן לסגור פער זה על ידי העברת המוקד מתשובות סטטיות לשאלת אסטרטגיית השאלות לאורך זמן.
בניית סיפורי מטופלים מציאותיים
כדי ליצור את סביבת הבדיקה החדשה, החוקרים מתחילים ממקור רפואי מתוקנן שמקשר מחלות מסוימות עם מערכי תסמינים אופייניים. הם בוחרים באקראי 100 זוגות מחלה–תסמין ואז משתמשים במודל AI כדי להפוך רשימות תסמינים יבשושות לתיאורי מטופל טבעיים — סיפורים שאדם באמת עשוי לספר במרפאה. מכל מקרה מלא הם מייצרים גרסאות מקוצרות שבהן מוזכרות רק כ־80 אחוז או 50 אחוז מהתסמינים המרכזיים. ה"הסתרה" המבוקרת הזו של מידע מאפשרת להם לחקור עד כמה מודלים שונים מסתגלים כאשר רמזים חשובים חסרים או רק מרומזים. בדיקות על חפיפה בין תסמינים מאשרות שהגרסאות הקצרות באמת מכילות פחות מידע שימושי, לא רק מילים פחותות.
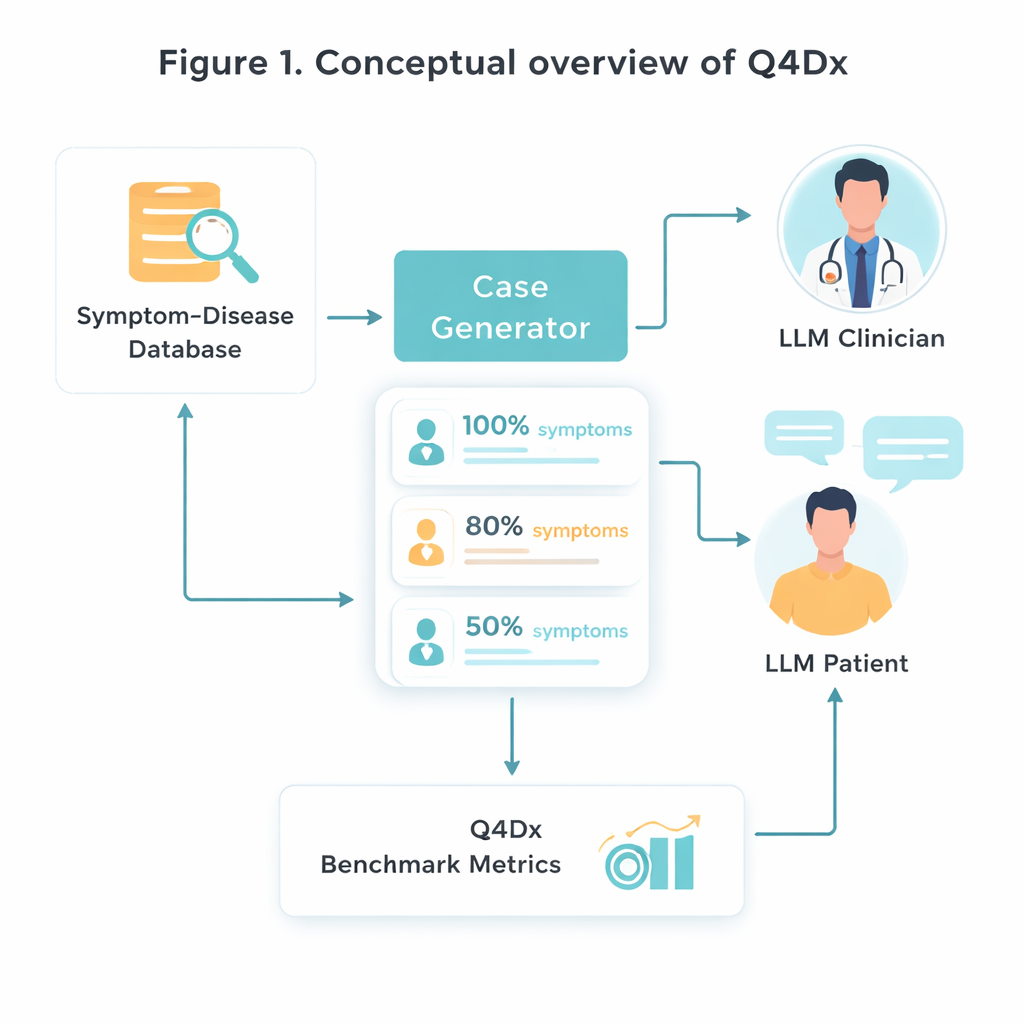
דיאלוגים מדומים בין רופא למטופל
ליבה של Q4Dx הוא מאגר גדול של שיחות מדומות בין שתי סוכנויות AI. אחת משחקת את תפקיד המטופל, עם גישה מלאה למחלה הבסיסית ולקבוצת התסמינים המלאה שלה. השנייה פועלת כרופא: היא רואה רק תיאור מקרה חלקי, שעשוי להיות מעורפל, בתחילה וחייבת להחליט מה לשאול בהמשך. אחרי כל תשובת מטופל, סוכן הרופא נותן אבחנה זמנית, ויוצר מסלול שלב־אחר־שלב של איך החשיבה שלו מתפתחת. על ידי תיעוד כל השאלות, התשובות והניחושים הביניים, הקריטריון לוכד לא רק האם המודל צודק, אלא איך הוא מגיע לשם. רצפי השאלות שנוצרו על ידי ה-AI משמשים כאסטרטגיות ייחוס — לא כאמת רפואית מושלמת, אלא כמדד עקבי שבאמצעותו ניתן להשוות מודלים עתידיים ואפילו סטודנטים אנושיים.
מדידת שאלות טובות, לא רק תשובות נכונות
כדי לשפוט ביצועים, המחברים מעצבים שלושה מדדים פשוטים אך משלימים. דיוק אבחנתי ללא הכנה (Zero‑Shot Diagnostic Accuracy, ZDA) שואל: אם תיתן למודל את המקרה השלם מראש, האם הוא יכול לזהות מיד את המחלה הנכונה? ממוצע השאלות עד אבחנה נכונה (Mean Questions to Correct Diagnosis, MQD) משקף יעילות: בממוצע, כמה שאלות למטופל צריך המודל עד שהוא בפעם הראשונה מגיע לאבחנה הנכונה, במגבלת חמש שאלות? ולבסוף, יעילות רצף החקירה (Interrogation Sequence Efficiency, ISE) בוחנת את איכות מסלול השאלות עצמו — עד כמה השאלות שבחר המודל דומות במשמעותן לרצף הייחוס. באמצעות מדדים אלו, הצוות מראה שמודל חזק כללי (GPT‑4.1) מאבחן נכון בערך בחצי מהמקרים כאשר המידע שלם, אך דיוקו יורד ככל שהתסמינים מוסתרים. במקביל, המפגשים האינטראקטיביים שלו בדרך כלל מצליחים אחרי כמה שאלות נבחרות היטב, והשאלות שלו מתיישרות יותר עם אסטרטגיות דמויות־מומחה על פני חליפות פניות.

מה המשמעות העתידית ל-AI רפואי
בעבור הלא־מומחים, המסר של עבודה זו ברור: ברפואה, לשאול שאלות חכמות חשוב לא פחות מלתת תשובות נכונות, ויש להעריך את ה‑AI בשניהם. Q4Dx מציע מסגרת חוזרת וניצלה לציבור שמטרתה בדיוק זאת. על ידי מתן סיפורי מטופל מציאותיים עם כמויות משתנות של מידע חסר, עקבות שיחה מפורטות ומדדים ברורים של דיוק ויעילות, הקריטריון מאפשר לחוקרים להשוות מערכות AI שונות ואפילו להעמידן מול רופאים אנושיים בתנאים מבוקרים. עם הזמן, כלים כמו Q4Dx יכולים לסייע לאמן עוזרים קליניים בטוחים ואמינים יותר ולשפר את הדרך שבה רופאים וסטודנטים לומדים ראיון דיאגנוסטי — ובסופו של דבר לתמוך בטיפול טוב יותר למטופלים אמיתיים.
ציטוט: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
מילות מפתח: בינה מלאכותית רפואית, הסקת אבחנה, דיאלוג קליני, מודלים לשוניים גדולים, אסטרטגיית שאילת שאלות