Clear Sky Science · he
MQADet: פרדיגמה "התקן-ושחק" לשיפור זיהוי עצמים בווקבי פתוח באמצעות מענה על שאלות מולטימודלי
מדוע חשוב שיהיו מזהים חכמים יותר של עצמים
טלפונים, רכבים, רובוטים לבית ומנועי חיפוש יותר ויותר מסתמכים על תוכנה שיכולה למצוא עצמים בתמונות: ילד שחוצה את הכביש, המפתחות שאבדו על השולחן, או מוצר מסוים על המדף. אבל רוב המערכות היום מבינות רק תוויות קצרות ופשוטות כמו "כלב" או "מכונית." כשמבקשים "הכלב הקטן עם הקולר האדום השוכב מאחורי כרית הספה," הן נוטות להתבלבל. המאמר הזה מציג את MQADet, דרך לשדרג מערכות מציאת עצמים קיימות כך שיוכלו להבין תיאורים עשירים ומפורטים כאלה מבלי לאמן מחדש את המודלים הבסיסיים.
מרשימות קבועות להבנה פתוחה ומהודקת
גלאי עצמים מסורתיים מאומנים על רשימות קטגוריות קבועות, כמו 80 הפריטים היומיומיים בערכת הנתונים הפופולרית COCO. הם עובדים היטב כל עוד העצם שייך לאחת הקטגוריות האלה והבקשה קצרה וברורה. עם זאת, העולם האמיתי מגושם: אנשים מתייחסים לדברים באמצעות ביטויים ארוכים, תכונות עדינות ויחסים כמו "האיש בווסט הצהוב העומד מאחורי המשאית." גלאים חדשים "בווקבי פתוח" מנסים להשתחרר מרשימות קבועות על ידי קישור בין תמונה לטקסט, אך הם עדיין מתקשים עם ניסוחים מורכבים ועם קטגוריות נדירות שנמצאות בזנב הארוך של הנתונים. הם גם דורשים הרבה חישוב ונתונים על מנת להשתפר.
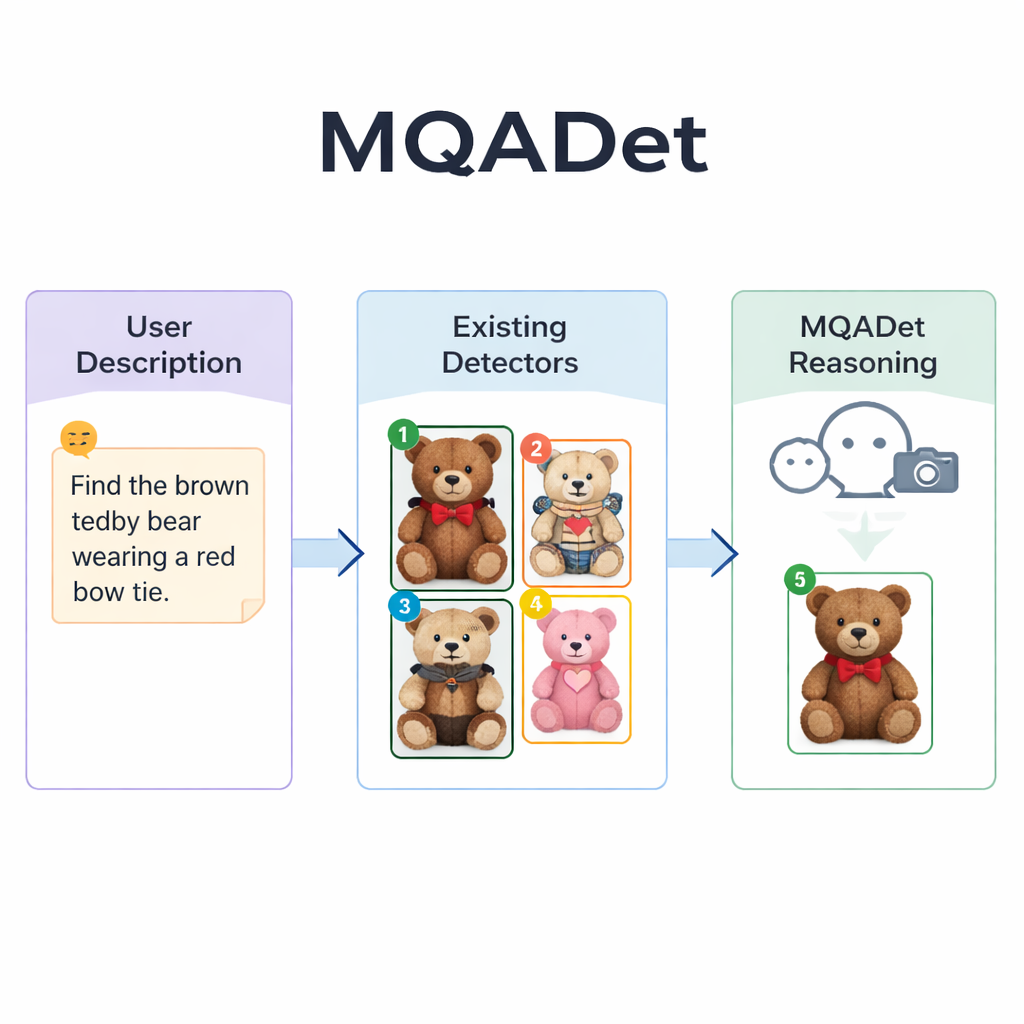
לאפשר למודלי שפה להנחות את החיפוש
MQADet מתמודד עם הבעיות האלה על ידי הצבת מודל שפה גדול מולטימודלי — מערכת שיכולה להסתכל על תמונות ולקרוא טקסט — מעל גלאים קיימים בתהליך תשובה על שאלות בשלוש שלבים. ראשית, שלב שנקרא חילוץ נושאים רגיש לטקסט (Text‑Aware Subject Extraction) קורא את המשפט המלא של המשתמש וחולץ את היעדים האמיתיים, כגון "מטריה" ו"הולך רגל" מתוך תיאור ארוך. זה משקף איך אדם עשוי לזהות במהירות את השמות המרכזיים במשפט לפני סריקת הסצנה. מהותי הוא שהשלב הזה מנצל את הבנת השפה הטבעית של המודל, ולכן הוא יכול להתמודד עם ביטויים ארוכים ותיאוריים במקום רק מילים בודדות.
סימון מועמדים בתמונה
בשלב השני, מיקום עצמים מולטימודלי מונחה טקסט (Text‑Guided Multimodal Object Positioning), MQADet מעביר את הנושאים שחולצו יחד עם התמונה לגלאי בווקבי פתוח קיים — כגון Grounding DINO, YOLO‑World או OmDet‑Turbo. הגלאי מציע מספר מיקומים אפשריים בתמונה שבהם כל נושא עשוי להימצא, מצייר מסגרת סביב כל מועמד וממקם מספר פשוט בתוך המסגרת. התוצאה היא "תמונה מסומנת" שמציגה את כל האפשרויות הסבירות. חשוב לציין ש‑MQADet אינו מאמן מחדש את הגלאים הללו; הוא פשוט משתמש בהם כמות שהם. זה הופך את הגישה ל"התקן‑ושחק": כשגלאי טוב יותר מופיע, ניתן להחליפו בצינור ללא נתונים נוספים או כוונון.

סיבה עדין לבחירה הטובה ביותר
השלב השלישי, שנקרא בחירת העצם האופטימלית מונעת על ידי MLLMs, הופך את הבחירה הסופית לשאלה בסגנון רב־ברירי עבור מודל השפה: בהתבסס על התיאור המקורי והתמונה המסומנת עם הקופסאות הממוספרות, איזה מספר מתאים ביותר לטקסט? מאחר שהמודל רואה הן את הניסוח המפורט והן את הפריסה הויזואלית, הוא יכול לשקול רמזים עדינים — דפוסים, צבעים, יחסים מרחביים כמו "משמאל", ואינטראקציות בין אובייקטים. המחברים מראים שהסרת שלב ההיסקלות הזה מורידה באופן חזק את הדיוק, מה שמדגיש את חשיבותו. באמצעות העיצוב התלת־שלבי הזה, MQADet שיפר את הדיוק בארבעה מבחנים תובעניים עם משפטים טבעיים וארוכים, לעתים משפר את הביצועים של גלאים קיימים ב‑10–40 נקודות אחוז מבלי לשנות את משקליהם הפנימיים.
מה משמעות הדבר לטכנולוגיה יומיומית
לא-מומחה, המסר המרכזי הוא שאיננו צריכים יותר לבנות גלאי עצמים מאפס כדי להפוך אותם לחכמים יותר. MQADet פועל כמו עוזר אינטליגנטי שיושב מעל המערכות הקיימות, ועוזר להן לפרש תיאורים אנושיים עשירים ולזהות את העצם הנכון בסצנות מורכבות. זה יכול להפוך חיפוש חזותי, כלי סיוע ומכונות אוטונומיות לאמינות יותר בהתמודדות עם האופן שבו אנשים מדברים באופן טבעי — מלא פרטים, דקויות והקשר — ולסלול את הדרך לאינטראקציה אינטואיטיבית יותר מונחית שפה עם העולם החזותי.
ציטוט: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
מילות מפתח: זיהוי עצמים בווקבי פתוח, מודלים שפה רב־ממדיים גדולים, מענה חזותי על שאלות, ראייה ממוחשבת, הבנת תמונה