Clear Sky Science · he
אומדן שונות מבוסס למידת מכונה תחת דגימה בשתי שלבים באמצעות נתוני בריאות וחינוך
למה ממוצעים חכמים חשובים להחלטות בעולם האמיתי
בכל פעם שרופאים בוחנים לחץ דם או מורים עוקבים אחרי ציוני תלמידים, הם לא מתעניינים רק בממוצע; הם צריכים לדעת עד כמה האנשים שונים סביב אותו ממוצע. הפיזור הזה, הנקרא שונות, מכתיב כמה משתתפים דרושים לניסוי, כמה גדול צריך להיות תוכנית התגבור, או כמה ביטחון ניתן לשים בהחלטת מדיניות. המאמר שמאחורי הסיכום הזה מציג שיטה חדשה, מבוססת סטטיסטיקה, למדידה מדויקת יותר של שונות על ידי שילוב רעיונות דגימה קלאסיים עם למידת מכונה מודרנית, ונבדק על נתוני בריאות וחינוך.
מדידת פיזור כאשר המידע לא שלם
בעולם אידיאלי החוקרים יידעו פרטים נוספים על כל אדם באוכלוסייה לפני ביצוע הסקר: גיל, הרגלי לימוד, היסטוריה רפואית ועוד. במציאות המידע הזה לעיתים חלקי או יקר לאיסוף. המחברים פועלים בתוך עיצוב שנקרא דגימה בשתי שלבים כדי להתמודד עם הבעיה. בשלב הראשון נלקחת דגימה גדולה וזולה יחסית ונרשמים נתונים רקע פשוטים, כמו גיל או האם יש גישה לאינטרנט. בשלב השני נבחרת תת־דגימה קטנה יותר ונמדד מדד יקר או זמן־צר, כמו לחץ דם סיסטולי או ציוני מבחן סופי. האתגר הוא להשתמש בשכבות המידע הללו כדי לאמוד עד כמה התוצאה משתנה באוכלוסייה כולה.
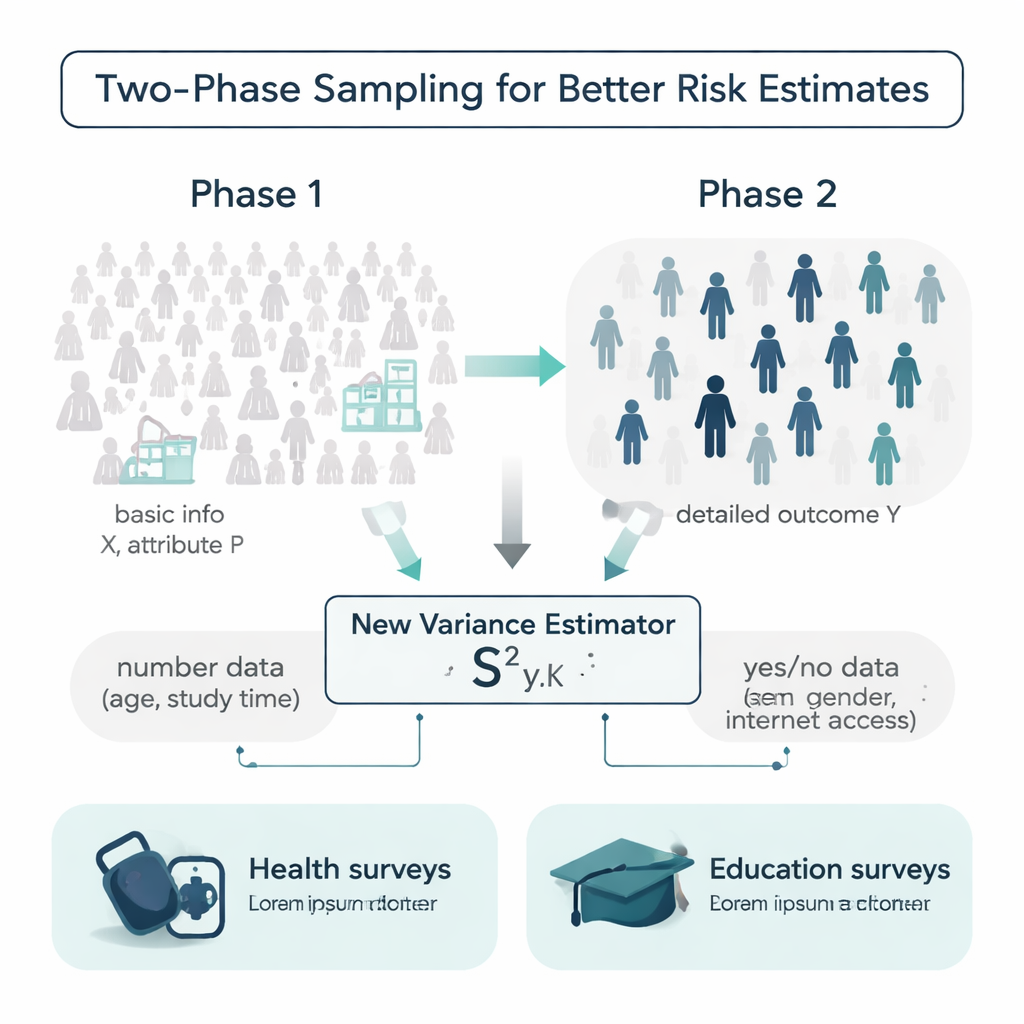
מאמד חדש שמשלב מספרים ותכונות כן/לא
רוב הכלים המסורתיים למדידת שונות מסתמכים רק על התוצאה עצמה או על משתנה עזר בודד, ולעתים מניחים שהנתונים עוקבים אחרי התפלגויות נוחות בצורת פעמון. המחברים מציעים אמדן חדש של השונות שמשתמש בשני סוגי מידע עזר בו־זמנית: משתנה מספרי (למשל גיל או זמן לימוד שבועי) ותכונה בינארית כן/לא (כמו מין או גישה לאינטרנט). הם מראים מבחינה מתמטית איך האמדן המשולב הזה מתנהג, ומפיקים נוסחאות להטיה ולממוצע ריבועי של השגיאה — שני מדדים מרכזיים לדיוק. בתנאים סבירים האמדן חסר־הטיה למעשה ושגיאת הציפייה שלו קטנה יותר מאשר של נוסחאות מקובלות רבות, כלומר הוא אמור לספק הערכות אי־ודאות חדות יותר מאותו כמות נתונים.
מבחן ביצועים על מגוון עולמות נתונים
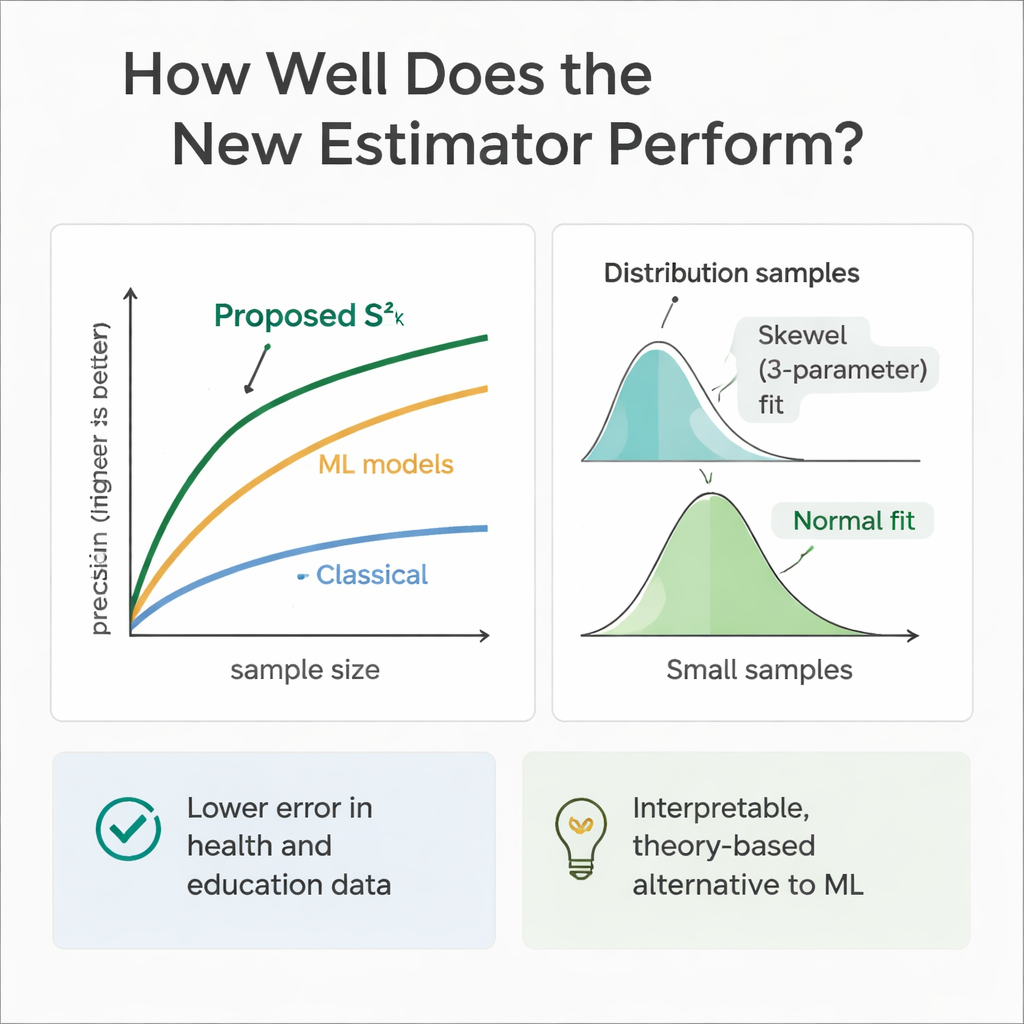
כדי לבדוק האם התיאוריה מתקיימת בפועל, הצוות הריץ ניסויים ממוחשבים נרחבים. הם חסו אוכלוסיות שבהן משתני העזר והתוצאה עקבו אחר מגוון התפלגויות, מסימטריות (נורמלית ואחידה) ועד מוטות (גאמא ווייבול). באמצעות דגימה חוזרת הם השוו את שגיאת האמדן החדש לזו של מספר שיטות מבוססות על פני גדלי דגימה שונים. ברוב המקרים, ובמיוחד ככל שגדלי הדגימה גדלו, הגישה החדשה הראתה יעילות יחסית גבוהה יותר — לעתים קיצצה את השגיאה ב־30 עד 70 אחוז בהשוואה לאמדן השונות הקלאסי. המחברים גם בחנו איך התפלגות הדגימה של האמדן עצמו מתנהגת, ומצאו שעקומת וייבול גמישה בת שלושה פרמטרים מתארת אותה היטב לדגימות בינוניות, ואילו כשהדגימות גדלות היא נוטה למבנה נורמלי.
נתונים אמתיים ממרפאות וכיתות
השיטה הוחלה לאחר מכן על שני מקרים אמיתיים. בסט נתוני בריאות, המדד היה לחץ דם סיסטולי, עם גיל כמשתנה מספרי ומין כתכונה בינארית. בסט נתוני חינוך, המדד היה ציון קורס סופי, המשתנה העזר היה זמן לימוד שבועי, והתכונה הייתה האם לתלמיד הייתה גישה לאינטרנט. בשני המקרים האמדן המוצע הניב את השגיאה הממוצעת הריבועית הקטנה ביותר מבין כל המתחרים הסטטיסטיים שנבדקו, והצמצם בצורה ניכרת את אי־ודאות השונות סביב ממוצע לחץ הדם וממוצע ביצועי התלמידים. שיפור זה מתורגם לרווח במרווחי ביטחון מדויקים יותר ולהשוואות אמינות יותר בין קבוצות או התערבויות.
איך זה עומד מול למידת מכונה
מכיוון שמודלים של למידת מכונה מצטיינים בחיזוי, המחברים גם אילפו עצי רגרסיה, יערות אקראיים ותמיכה וקטורית רגרסיבית על אותם תרחישי בריאות וחינוך מדומים. המודלים הללו, שהוזנו באותם משתני עזר, לעיתים השיגו דיוק חיזוי שקול או מעט טוב יותר מהאמדן החדש. עם זאת, הם פועלים כקופסאות שחורות: קשה לעקוב בדיוק איך הם משלבים את המידע, והם חסרים את הנוסחאות הברורות הדרושות להסקות סקר מסורתיות. האמדן המוצע, לעומת זאת, שקוף ושורשי בתורת הדגימה, מה שמקל על הצדקה בהקשרים רגולטוריים, קליניים או מדיניות שבהם ההסבר חשוב לא פחות מביצועים טהורים.
מה משמעות הדבר לסקרים בשטח
במונחים פשוטים, עבודה זו מראה שחוקרים יכולים לקבל מדידות פיזור אמינות יותר בלי להגדיל משמעותית את גדלי הדגימה, פשוט על ידי שימוש מבוקר גם במידע נוסף מינימלי שהם כבר אוספים. על ידי שילוב גורם מספרי (כמו גיל או זמן לימוד) עם תכונת כן/לא פשוטה (כמו מין או גישה לאינטרנט) בתוכנית דגימה בשני שלבים, האמדן החדש נותן הערכות שונות חדה ויציבה יותר מאשר שיטות ותיקות. בעוד שבמקרים רבים כלי למידת מכונה מתקדמים נשארים נקודת ייחוס שימושית, הגישה המוצעת מציעה פתרון מעשי וניתן לפרשנות בין השניים, שעוזר לאנליסטים בתחום הבריאות והחינוך להסיק מסקנות חזקות יותר מתוך נתונים מוגבלים.
ציטוט: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
מילות מפתח: דגימת סקרים, אומדן שונות, למידת מכונה, נתוני בריאות, מחקר חינוך