Clear Sky Science · he
אימות אמינות חדשות באורדו בעזרת למידה עמוקה עם הטמעת BERT ו-GloVe מרוכבות
למה זיהוי חדשות מזויפות באורדו חשוב
בפקיסטן ובכל העולם, יותר אנשים מקבלים כיום את חדשותיהם מאתרים ורשתות חברתיות מאשר מעיתונים או טלוויזיה. השינוי הזה הקל על הפצת סיפורים שקריים במהירות רבה, במיוחד בשפות לאומיות כמו אורדו שבהן הכלים הדיגיטליים מוגבלים. המחקר הזה מתמודד עם שאלה פשוטה אך דחופה: האם אינטיליגנציה מלאכותית מודרנית יכולה להבחין אוטומטית בין חדשות אמיתיות למזויפות באורדו, ולסייע לקוראים רגילים, עיתונאים ופלטפורמות להגן על עצמם מפני מידע מטעה?
האתגר הגובר של מידע מטעה מקוון
המחברים מתחילים בהצגת האופן שבו כותרות מומצאות וסיפורים מעוותים יכולים לעצב דעת קהל, להסעיר מתחים פוליטיים ואפילו לפגוע בבריאות ובמצב הכלכלי של אנשים. בעוד שאתרי בדיקת עובדות ומיזמי מחקר רבים מתמקדים באנגלית, שפות אזוריות כמו אורדו נשארות לעתים מאחור. המשאבים הקיימים לאורדו כוללים רק כמה אלפי פריטי חדשות, רבים מתורגמים מאנגלית ומתמקדים בנושאים צרים כמו פוליטיקה. זה מקשה על אימון מערכות ממוחשבות מהימנות לזיהוי תכנים חשודים בשפה שאותה רוב הפקיסטנים קוראים בפועל.
בניית מאגר חדשות גדול באורדו
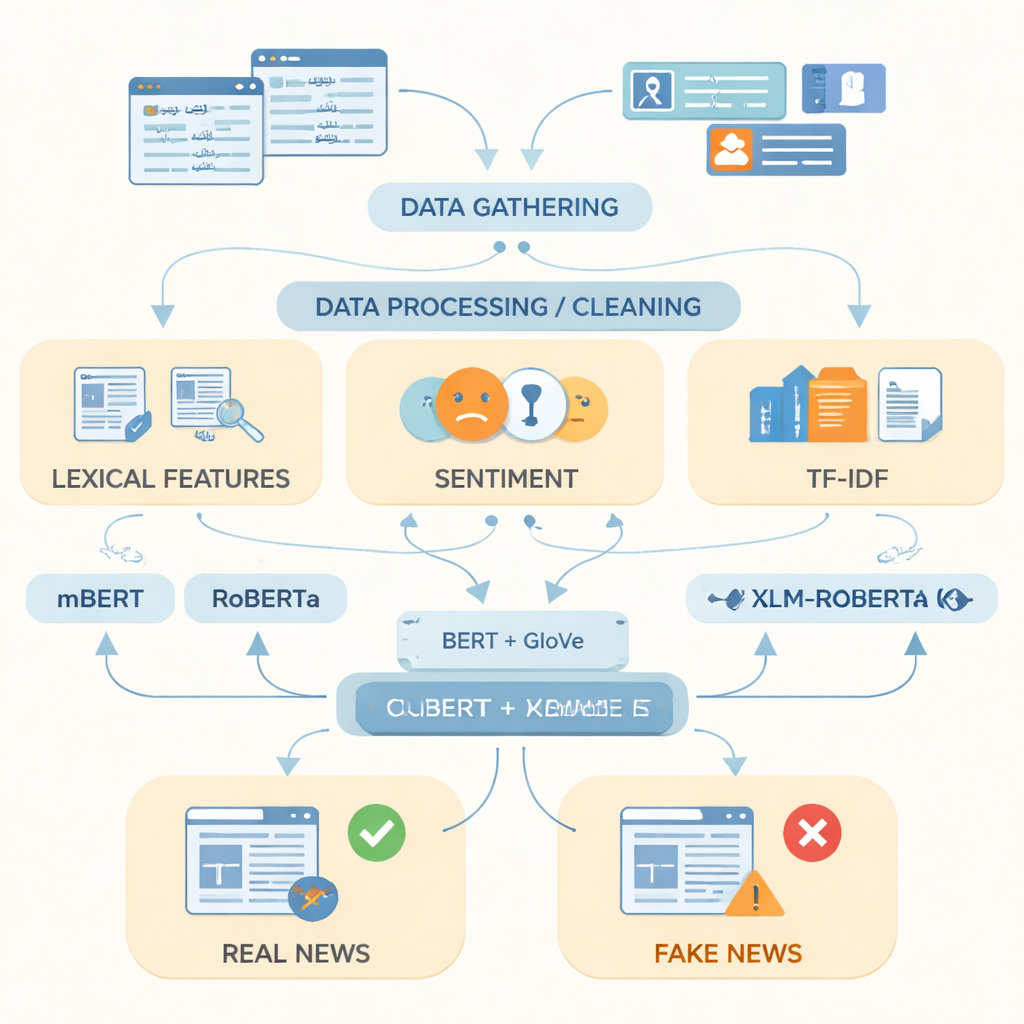
כדי לצמצם פער זה, החוקרים אספו מה שהם מתארים כמאגר החדשות המזויפות הנרחב ביותר באורדו עד היום, הכולל 14,178 מאמרי חדשות שנאספו בין 2017 ל-2023 מאתרי חדשות פקיסטניים מוערכים ופלטפורמות מקוונות. הסיפורים מכסים חמש עשרה תחומי חיי יומיום, כולל פוליטיקה, בריאות, חינוך, עסקים, פשיעה, ספורט והסביבה. באמצעות מקורות בדיקת עובדות כגון PolitiFact, FactCheck ו-APIs ייעודיים לחדשות, כל פריט סווג כאמיתי או מזויף; פריטים חלקית נכונים קובצו עם חדשות אמיתיות כדי לשקף דיווח יותר מעודן. הצוות לאחר מכן ניקה את הטקסט על ידי הסרת כפילויות, כתובות ווב ופיסוק מיותר, שבירת משפטים למילים והסרת מילים תפלות נפוצות מאוד.
להראות למחשבים איך נראות חדשות מזויפות
לאחר הכנת הנתונים, המחברים התמקדו בדרך הטובה ביותר לייצג טקסט באורדו עבור מחשב. הם שילבו אינדיקטורים פשוטים כמו מילים בשימוש תדיר, הטון הרגשי של השפה ונקודות תדירות מונחים עם שתי טכניקות חזקות לייצוג מילים. אחת, הנקראת GloVe, מטפלת בכל מילה כווקטור מספרי קבוע המבוסס על תדירות הופעתה לצד מילים אחרות ברחבי האוסף. השנייה, המבוססת על מודלים בסגנון BERT, בוחנת כל מילה בהקשרה במשפט ומקצה לה משמעות המותאמת להקשר. על ידי חיבור שתי נקודות המבט הללו לשפה לייצוג מעושיר אחד, המערכת יכולה לתפוס גם דפוסים כוללים וגם שינויים עדינים בניסוח שמבדילים לעתים קרובות בין סיפורים מזויפים לאמיתיים.
מבחן למודלים מתקדמים של שפה
החוקרים הזינו לאחר מכן את הייצוגים האלה לתוך שלושה מודלים מודרניים של למידה עמוקה שאומנו על טקסט במגוון שפות: mBERT, RoBERTa ו-XLM-RoBERTa. שלושתם כוונו מחדש על מאגר הנתונים באורדו כדי לחזות האם כל מאמר אמיתי או מזויף. הביצועים נמדדו בעזרת מדדים סטנדרטיים: דיוק (כמה פעמים הם צדקו), דיוק חיובי (כמה מהפריטים שהוגדרו כמזויפים אכן היו מזויפים), זיהוי (כמה מסך כל הסיפורים המזויפים הם תפסו) ו-F1-score שמאזן בין דיוק לזיהוי. בעוד שכל מודל הציג ביצועים חזקים, XLM-RoBERTa בשילוב הייצוג המאוחד של BERT ו-GloVe התברר כמוביל, וסווג נכון כ־96 אחוזים מהמאמרים במבחן והשיג F1-score של 0.956 — טוב יותר ממערכות זיהוי חדשות מזויפות באורדו קודמות שהשתמשו במאגרי נתונים קטנים יותר או בשיטות פשוטות יותר.
מה משמעות הדבר לקוראים היומיומיים
עבור הקהל הרחב, המסר ברור: עם מאגרי נתונים איכותיים מספיק של חדשות באורדו והטכנולוגיה המתאימה של בינה מלאכותית, כיום ניתן לבנות כלים שמסמנים באופן אוטומטי סיפורים שעלולים להיות מזויפים ברמת מהימנות גבוהה. המחקר מראה שייצוגים לשוניים עשירים ומודלים רב-לשוניים מעניקים למחשבים הבנה טובה יותר של האופן שבו אורדו נכתבת בפועל באזורים ונושאים שונים. למרות שהעבודה הנוכחית מתמקדת בטקסט בלבד ולא מנתחת עדיין תמונות או התנהגות ברשתות החברתיות, היא מניחה יסוד חזק למערכות עתידיות שיכולות לפעול על פני שפות וסוגי מדיה. במונחים מעשיים, המחקר מקרב את פקיסטן צעד לעבר תוספי דפדפן, לוחות בקרה לעיתונות או מסנני רשתות חברתיות שעוזרים לאנשים להפריד בין עובדה לבין בדיה בשפה שבה הם משתמשים מדי יום.
ציטוט: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
מילות מפתח: זיהוי חדשות מזויפות, שפת אורדו, למידה עמוקה, BERT ו-GloVe, מידע מוטעה מקוון