Clear Sky Science · he
שיפור הערכת עומק בטווח ארוך באמצעות קידוד הטרוגני של CNN-טרנספורמר ומיזוג סמנטי חוצה-ממד
לראות עומק בעין יחידה
רובוטים מודרניים, כלי רכב אוטונומיים ומעופפים (drones) מסתמכים לעתים קרובות על חיישני 3D יקרים כדי להבין מרחקים. המחקר הזה מראה כיצד מצלמות צבע מקובלות, כמו אלה בטלפונים חכמים, יכולות להישלח הרבה יותר רחוק: המחברים מציעים דרך חדשה למחשב להסיק עומק מתוך תמונה אחת בלבד, וממוקדים בחלק הקשה ביותר של הסצנה—המרחק הרחוק, שבו המכשולים קטנים, מטושטשים וקלים לשגיאה.
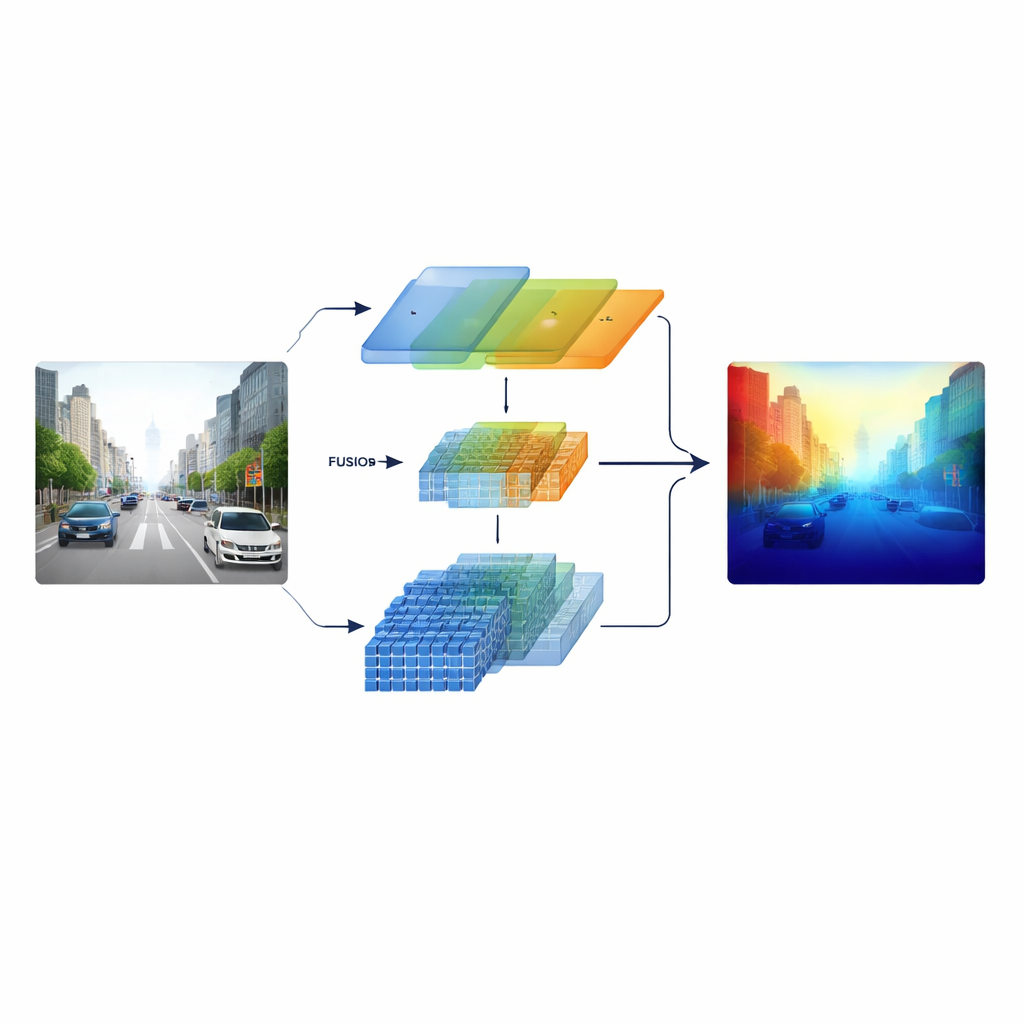
מדוע קשה לשפוט חפצים מרוחקים
הערכת עומק מתמונה יחידה, המכונה monocular depth estimation, היא סוג של פטנט חזותי. חפצים קרובים תופסים פיקסלים רבים ומציגים מרקמים חדים, ולכן הרשתות העצביות של היום כבר מצליחות בתחום הקצר והבינוני. עם זאת, במרחק רב יותר מכוניות מצטמצמות למספר פיקסלים ומרקמי הכביש מתעמעמים בערפל. רשתות קונבולוציה סטנדרטיות טובות בזיהוי פרטים מקומיים עדינים אך מתקשות לקלוט את התמונה הרחבה של כל הרחוב. מודלים מבוססי טרנספורמר רואים הקשר גלובלי היטב, אך הם פחות רגישים לקצוות ולמרקמים זעירים. כתוצאה מכך, שתי המשפחות של שיטות נוטות להחטיא בדיוק במקום שבו הנווט הבטוח זקוק לאומדנים מהימנים: במרחקים ארוכים.
מיזוג שתי דרכי ראייה
החוקרים מטפלים בזה על ידי בניית מקודד "הטרוגני" שמפעיל שתי שיטות עיבוד חזותיות שונות במקביל. ענף אחד מבוסס על רשת קונבולוציה בסגנון ResNet הקלאסי המתמחה בדפוסים מקומיים חדים כגון סימוני נתיבים, עמודים וקצוות חפצים. הענף השני משתמש ב-Swin Transformer, שנועד ללכוד קישורים לטווח ארוך בתמונה, כמו פריסת מסדרון כביש או קו הרקיע של מבנים מרוחקים. במקום לשלב את שתי הפרספקטיבות רק בסוף, המערכת שומרת תכונות מרובות-סקייל משני הענפים ומזינה אותן לשלב מיזוג מעוצב בקפידה, כך שמבנה עדין והקשר רחב מיידעים זה את זה לאורך כל הדרך.
חציית ערוצים, מרחב ומדרג
בלב המודל נמצא מודול מיזוג סמנטי חוצה-ממד שפועל כחדר ישיבות אינטיליגנטי לשני זרמי המידע. ראשית, הוא מחליט אילו ערוצים—סוגים שונים של תבניות חזותיות נלמדות—ראויים ליותר תשומת לב, ומאזן את האותות ממרקמים מפורטים ומרמזי סצנה ברמה גבוהה. לאחר מכן הוא מביט בנפרד בכיוונים אופקיים ואנכיים, שהם בעלי משמעות מיוחדת בסצנות מלאות כבישים, מבנים ועצים, כדי להדגיש מבנים חשובים המשתרעים על פני התמונה. לבסוף, הוא מערבב תכונות שטחיות ועשירות בפרטים עם תכונות עמוקות ומופשטות יותר על פני כמה סקלות. שלב משקלול ניתן-ללימוד מאפשר לרשת להחליט כמה לסמוך על כל ענף בכל אזור, כך שחפצים קטנים ומרוחקים לא יטבעו בנוף הקרוב.
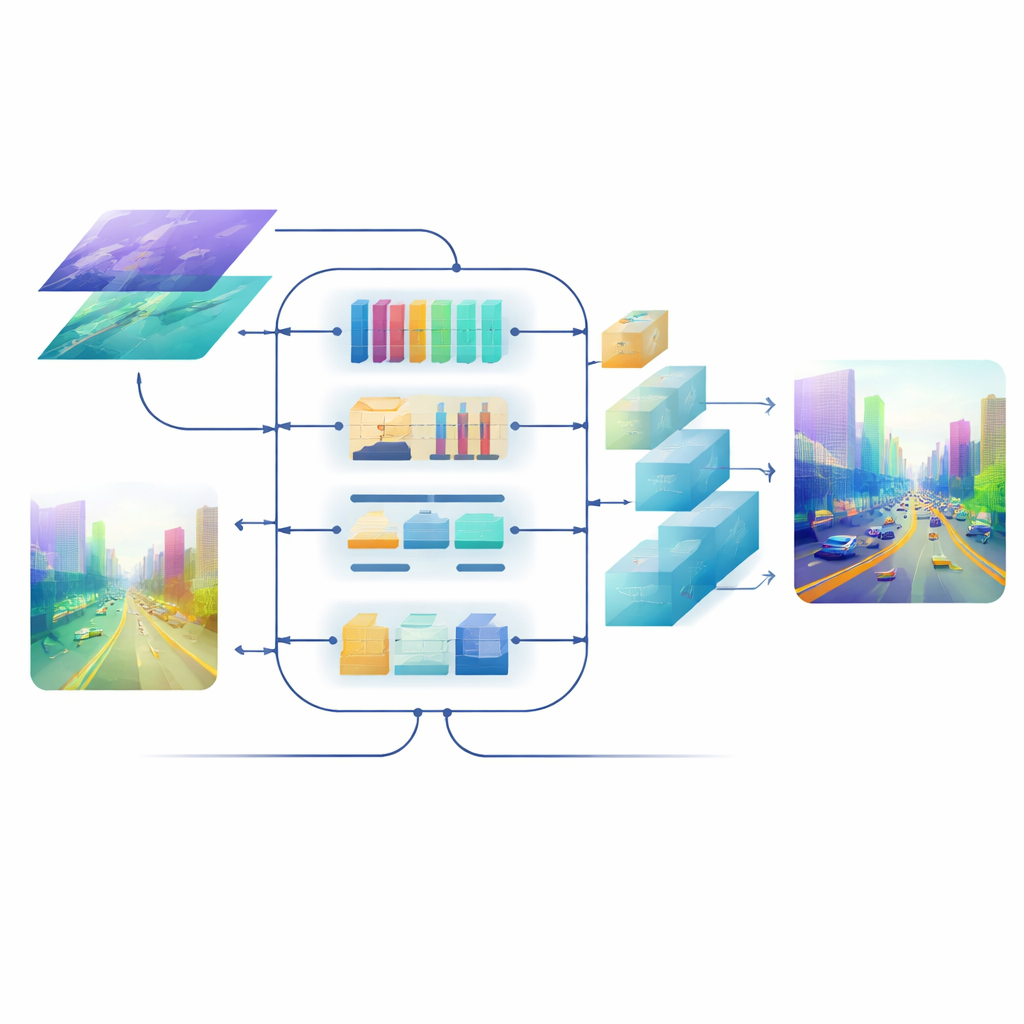
חדות התמונה הסופית
אפילו עם תכונות ממוזגות טובות, המרתן חזרה למפת עומק ברזולוציה מלאה עלולה לטשטש קצוות ולהעלים מבנים דקים. כדי להימנע מכך, הצוות מתכנן דקודר מונחה תשומת לב. בלוקי ההגדלה שלו משתמשים בקונבולוציות depth-wise קלות כדי להגדיל את המפה מבלי לאבד הקשר, ומנגנון תשומת לב עצמית רב-סקייל מקבץ ערוצי תכונה כך שהחישוב יהיה יעיל. שלב זה מלטש את תחזיות העומק בכל סקל תוך שמירה על עלות חישובית סבירה. התוצאה היא שדה עומק חלק וקוהרנטי שבו גבולות עצמים—כמו קווי המתאר של רוכב אופניים מרוחק או סריגי מיטת קומתיים—נשארים חדים.
כמה זה עובד במציאות
השיטה נבחנת על מספר מערכי נתונים סטנדרטיים. ב-KITTI, אוסף גדול של סצנות נהיגה, המודל משיג דיוק ברמת ה-state-of-the-art ברוב המדדים הנפוצים ו,חשוב מהכול, מפיק את השגיאה הנמוכה ביותר באזורים שמיועדים לטווח ארוך. הוא גם מניב גבולות עומק נקיים יותר סביב עצמים מאשר מערכות מתחרות. ב-NYU Depth V2, הכולל סצנות פנים, ועל מאגר SUN RGB-D, אותו מודל מתכלל היטב ומשחזר רהיטים ופריסות חדר בתמונת נקודות תלת־ממדית משכנעת. מחקרים אבולאציה—בדיקות שיטתיות שמסירות או מחליפות רכיבים—מראים שכל חלק מוצע, מהמקודד ההיברידי ועד מודול המיזוג ובלוק התשומת לב של הדקודר, משפר באופן מדיד את הביצועים, במיוחד באזורים מרוחקים ודלי־מרקם.
מה זה אומר לטכנולוגיה היומיומית
במילים פשוטות, העבודה הזו מלמדת רשת עצבית להשתמש גם בזכוכית מגדלת וגם בעדשת רחבת־זווית בו־זמנית, ולשלב ביניהם בחוכמה. באמצעות איזון טוב יותר בין פרטים מקומיים לבין הבנת הסצנה הכוללת, המסגרת המוצעת משפרת במידה ניכרת את יכולת מצלמה יחידה לשפוט עומק רחוק ברחוב או בחדר. זה הופך אותו לפרקטי יותר לצייד רובוטים, כלי רכב ומעופפים בחיישנים זולים יותר ועדיין לספק להם תחושת 3D עשירה של העולם—צעד חשוב לקראת מערכות אוטונומיות בטוחות, בעלות־תועלת ויעילות יותר.
ציטוט: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
מילות מפתח: הערכת עומק מזוית אחת, ראייה ממוחשבת, מיזוג טרנספורמר ו-CNN, נהיגה אוטונומית, שחזור סצנה תלת־ממדי