Clear Sky Science · he
התאמת ממוצע גרעיני משפרת הערכת סיכון תחת הזזות התפלגות מרחביות
מדוע חשוב למידוד סיכון במפות שמשתנות
מודלים של למידת מכונה משמשים יותר ויותר כדי לחזות היכן יימצאו מינים, איך גידולים מסודרים ברקמה או כיצד מזהמים מתפשטים. עם זאת, הנתונים שמשמשים לאימון מודלים אלה נאספים לעתים קרובות במקומות מאוד ספציפיים—דגימה מרוכזת ליד ערים, בתי חולים או אתרי שטח נגישים—בעוד שהמודלים מיושמים על אזורים רחבים ושונים. חוסר התאמה זה בין מקומות איסוף הנתונים לבין מקומות החיזוי יכול להעניק תחושה שגויה שהמודלים בטוחים ומדויקים יותר ממה שהם באמת. המאמר "Kernel mean matching enhances risk estimation under spatial distribution shifts" שואל שאלה פשוטה לכאורה: כשהעולם נראה שונה מהנתונים שבהם אומנת, עד כמה המודל עשוי לטעות וכיצד ניתן לגלות זאת?
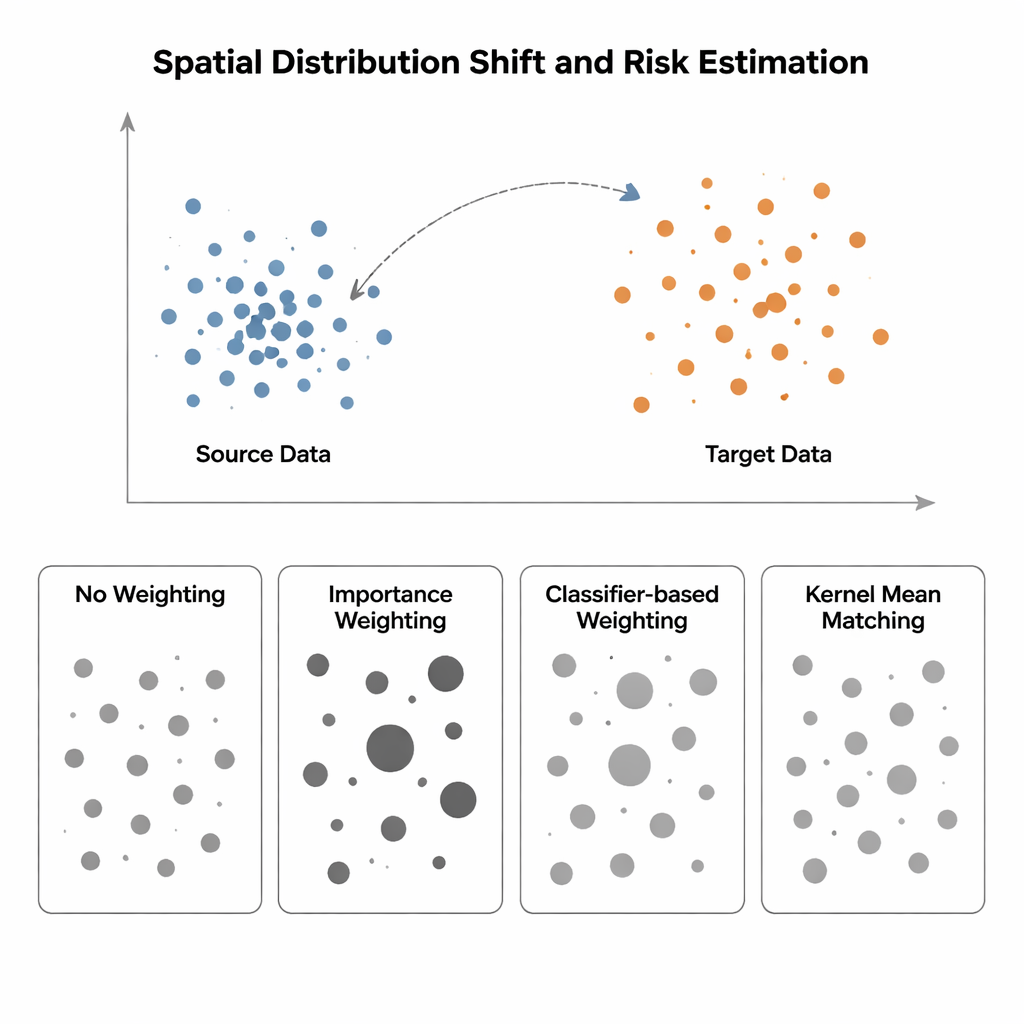
כשאימון ומבחן חיים בעולמות שונים
בסטטיסטיקה, "סיכון" של מודל הוא הטעות הצפויה שלו על נתונים חדשים שלא נראו קודם. טריקים סטנדרטיים להערכה—כמו חצאי-צולב או החזקת קבוצת מבחן אקראית—מניחים בעדינות שהנתונים לאימון ולמבחן נמשכים מאותה התפלגות. נתונים מרחביים שוברים הנחה זו. גרדיאנטים סביבתיים, דגימה מקובצת ושינויים באקלים משמעותם שהתנאים שבהם מאמנים מודל עשויים להיות שונים במהותם מאלו שבהם מיישמים אותו. לדוגמה, תצפיות על מינים לעתים קרובות מרוכזות בסביבת דרכים, בעוד החלטות שימור עוסקות באזורים מרוחקים; דגימות גידול עשויות להילקח מחלק אחד של רקמה, אך החיזויים נדרשים בחלקים אחרים. במקרים כאלה, הערכות סיכון קונבנציונליות נוטות להיות אופטימיות מדי, ומסתירות עד כמה המודל עלול להיכשל במיקומים חדשים.
כלים ישנים מתקשים מול הטיה מרחבית
המחקר משווה ארבע שיטות להערכת סיכון מודל כאשר התפלגות הקלט משתנה מאזור "מקור" (שבו התוויות ידועות) לאזור "יעד" (שבו התוויות נדירות או חסרות). השיטה הפשוטה ביותר, שנקראת ללא משקלות, מודדת פשוט את הטעות הממוצעת על הנתונים הזמינים ומניחה שמקור ויעד דומים—הנחה שמתפרקת תחת הטיה מרחבית. Importance Weighting מנסה לתקן זאת על ידי קנה-תור לכל דוגמת מקור בהתאם לשכיחות סוג הנקודה ביעד יחסית למקור. בתיאוריה זה משחזר את הסיכון הנכון, אבל בפועל זה דורש הערכת צפיפויות הסתברות במרחבים גבוהי-ממד. כאשר נתוני המקור דחוסים מאוד בעוד שנתוני היעד מפוזרים יותר—מצב טיפוסי באקולוגיה מרחבית או בהדמיה רפואית—הערכות הצפיפות הללו הופכות לבלתי מהימנות וכל כמה דגימות מקבלות משקלים עצומים, מה שהופך את הערכת הסיכון לבלתי יציבה. גישות מבוססות-ממיין (classifier) שמתאמנות להבחין בין נקודות מקור ויעד וממירות את ההסתברויות למשקלים, נמנעות מהערכת צפיפות מפורשת אך לעתים מייצרות סיכונים לא מכוילים כי הן ממקסמות דיוק סיווג, לא התאמת התפלגויות.
דרך אחרת: להתאים התפלגויות ישירות
המחברים מציעים Kernel Mean Matching (KMM), גישה שמדלגת על הערכת צפיפות לחלוטין. במקום לנסות לחשב כמה סביר כל נקודה תחת התפלגויות מקור ויעד, KMM מחפשת משקלים לדגימות המקור שעושים כך שממוצע ה"חותם" שלהן במרחב תכונות גמיש המוגדר על ידי גרעין יתאים לזה של דגימות היעד. באינטואיציה, היא ממתחתת או מקטינה את השפעת כל נקודת מקור כך שהענן המשוקלל של המקור ייראה כמו ענן היעד. לאחר שמוצאים משקלים אלה, הסיכון מוערך כממוצע משוקלל של שגיאות המקור. כלי משלים, פונקציית המתאם המקומית, כמותית עד כמה הנתונים מקובצים במרחב; היא משמשת כאבחון כדי לזהות מתי הזזות התפלגות חזקות מספיק כך ששינוי המשקלות צפוי לסייע.
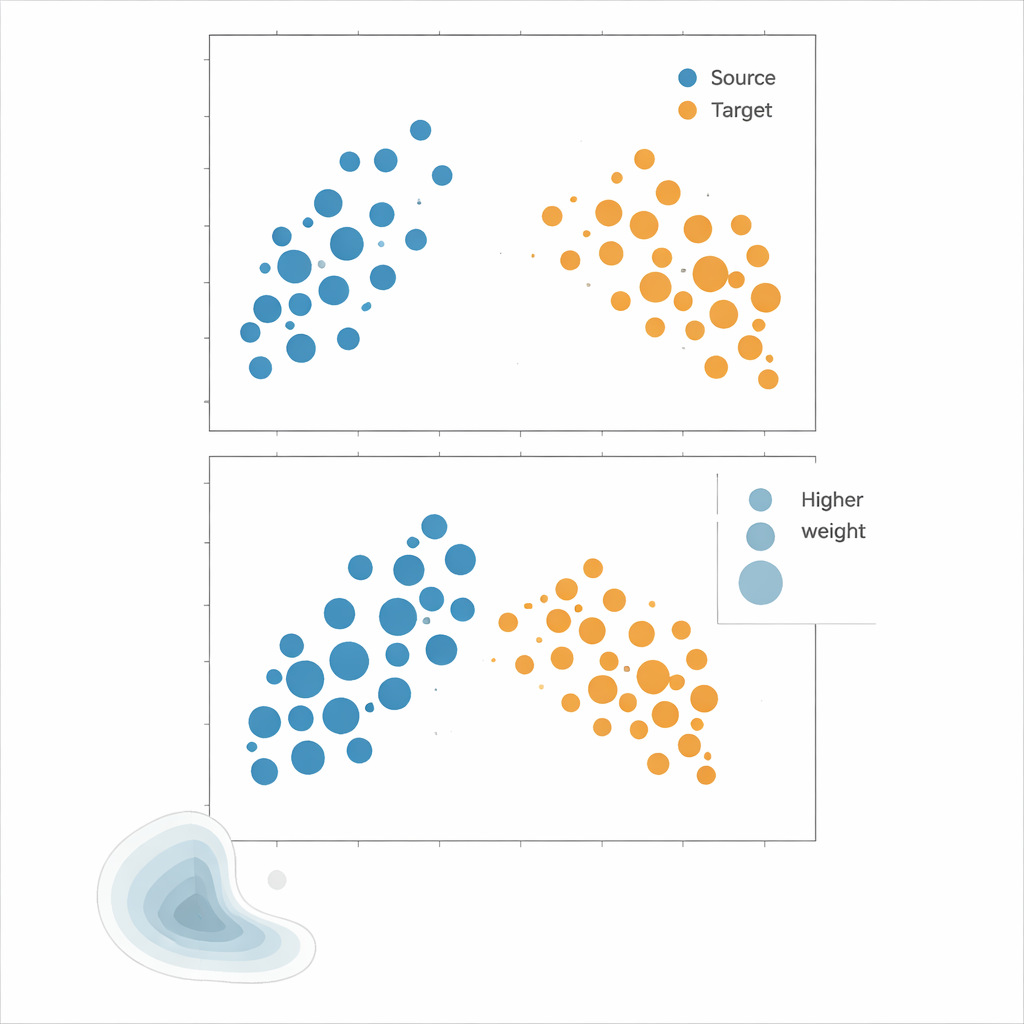
מבחן השיטות
כדי לראות איזו אסטרטגיה עובדת הכי טוב, החוקרים הריצו ניסויים נרחבים על נתונים סינתטיים ומציאותיים. "נופים" סינתטיים נבנו מתערובות של אשכולות גאוסיאניים שניתן לשלוט בדיוק על הפריסה, הצורה וכיסוי התחום שלהם, מה שמאפשר בדיקות מבניות כמו חיתוך חלק מהתחום, שינוי דפוסי תלות בין תכונות, או מעבר בין דפוסי נקודות מקובצים לצפיפות כמעט אחידה. מערכי נתונים אמיתיים כוללים תצפיות על מיני צמחים בנורדיקה, המתוארים לפי אקלים ומיקום, ותצורות מרחביות של תאי חיסון בתוך גידולים. בתרחישים אלה, מאמנים מודלים על נתוני מקור מקובצים ומעריכים אותם על נתוני יעד פחות מקובצים, המדמים הטיות דגימה שכיחות. הביצועים נבחנים באמצעות כמה מדדי שגיאה, עם דגש על עד כמה הערכת הסיכון של כל שיטה ממשיכה אחר השגיאה האמיתית על היעד.
הערכת סיכון אמינה יותר במרחבים מבולגנים ובעלי מימד גבוה
בכמעט כל הגדרות הסינתטיות והנתונים הממשיים, KMM מספקת את הערכות הסיכון המדויקות והיציבות ביותר. היא מפחיתה את שגיאת האחוז המוחלט הממוצעת בכ-12 עד 87 אחוז בהשוואה לחלופות, ובחשוב מכך מונעת את "התפרצות המשקלים" שמעציבה את Importance Weighting במימדים גבוהים. בדוגמות קשות של פריסות תאים בגידול, למשל, Importance Weighting עלולה להניב שגיאות העולות על אלפי אחוזים, בעוד KMM נשארת בטווחים ניהוליים. שינוי משקלות מבוסס-ממיין בדרך כלל משפר את השיטות הבסיסיות אך עדיין מפגרת אחרי KMM, שמשקפת את הדגש שלו על בידול ולא על התאמת התפלגויות נאמנה. תוצאות אלה מצביעות על כך שביישומים מרחביים—שבו נתונים מקובצים, מוטים ובעלי מימד גבוה—KMM מציעה דרך עקרונית להעריך עד כמה ניתן לבטוח בחיזוייו של מודל.
מה משמעות הדבר עבור החלטות בעולם האמיתי
לבעלי מקצוע שאינם מומחים המשתמשים בלמידת מכונה באקולוגיה, מדעי הסביבה או ביו-רפואה, המסר ברור: ציוני מבחן סטנדרטיים יכולים להיות מטעה מבחינה מסוכנת כאשר אזור הפריסה שונה ממקום איסוף הנתונים. Kernel Mean Matching מספקת דרך לתקן זאת על ידי איזון מחדש של השפעת דגימות האימון כך שיתאימו סטטיסטית למקומות או לרקמות שמעניינות אתכם. המחקר מראה שגישה זו מספקת באופן עקבי הערכות כנות יותר של שגיאת המודל, אפילו תחת הטיה מרחבית חמורה וריבוי משתנים. במעשה, זה אומר הנחיה אמינה יותר בבחירת מודלים ותמונה ברורה יותר היכן החיזויים מהימנים—ואיפה יש לנקוט זהירות.
ציטוט: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
מילות מפתח: הזזת התפלגות, מודלינג מרחבי, התאמת ממוצע גרעיני, הערכת סיכון מודל, נתונים אקולוגיים וביו-רפואיים