Clear Sky Science · he
זיהוי אינטליגנטי של התנהגות תלמידים עבור סביבות למידה חכמות
מדוע לכיתות חכמות צריך לראות מה התלמידים עושים
בהמון כיתות, המורים נאלצים לנחש מי עוקב אחרי ההסבר, מי אבוד ומי עסוק בדבר מה שאינו קשור בשקט. מאמר זה בוחן כיצד בינה מלאכותית יכולה לזהות באופן אוטומטי מה התלמידים עושים — כמו קריאה, כתיבה או הרמת יד — מתמונות כיתת לימוד שגרתיות. על ידי המרת תמונות גולמיות למדידות אמינות של פעילות בכיתה, המערכת שואפת לספק למורים משוב בזמן אמת על מעורבות תלמידים ללא הצורך בתצפית גוזלת זמן או במעקב חודרני.
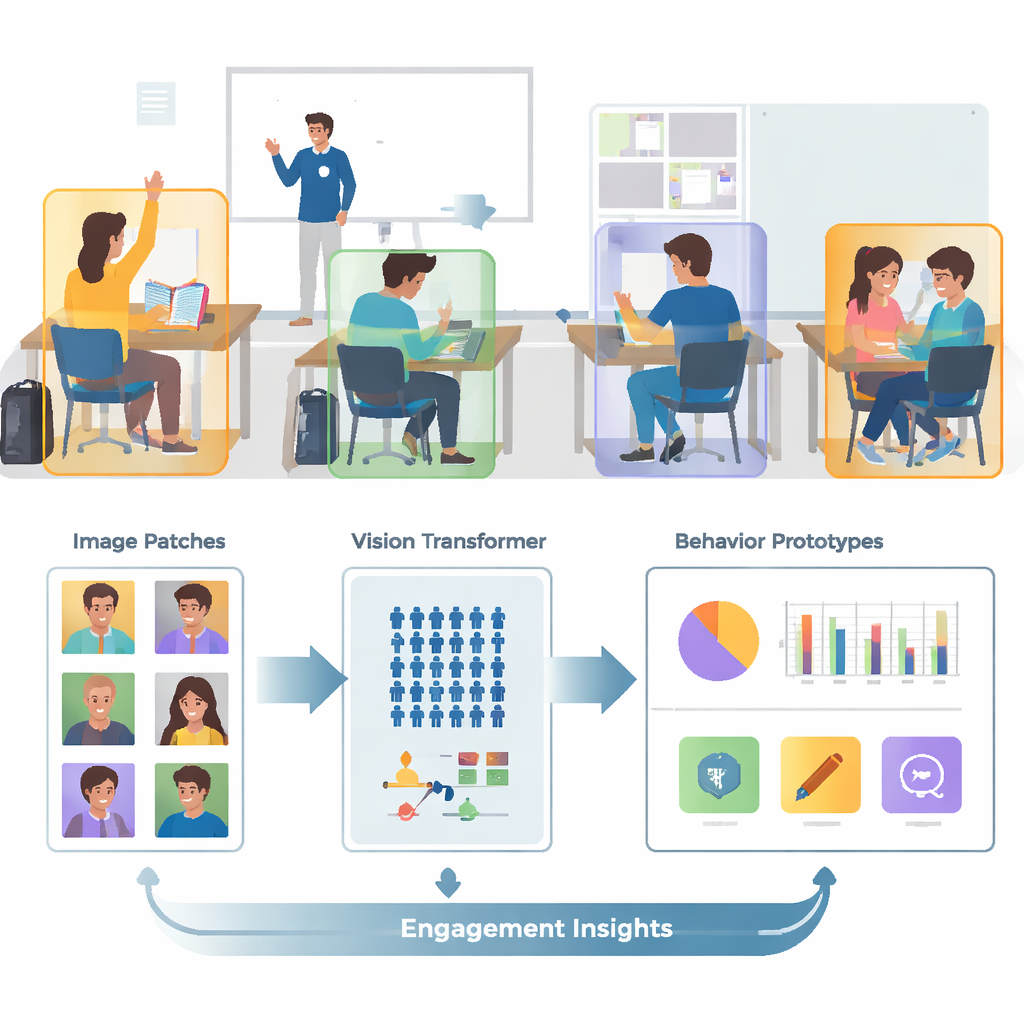
מתמונות מבולגנות ל'תמונות ממוקדות'
כיתות אמיתיות צפופות, מלאות פעילות ומבלבלות מבחינה ויזואלית. בתמונה אחת עשויים להופיע עשרות תלמידים, גופים חפופים ופרטים מסיחי דעת רקע כמו קירות, מסכים ופוסטרים. המחברים בונים על אוסף תמונות ציבורי בשם SCB‑05, המכיל אלפי תמונות כיתה מתוייגות עם התנהגויות ספציפיות — כמו הרמת יד, קריאה, כתיבה, עמידה, דיבור או אינטראקציה מול הלוח. במקום להזין סצנות שלמות למחשב, המערכת משתמשת בקבצי אנוטציה כדי לחתוך החוצה רק את האזורים סביב כל תלמיד או מורה. שלב עיבוד מקדים זה מסיר חלק גדול מהבלגן הוויזואלי, כך שהמודל יכול להתמקד בבעיטות גוף, במיקום היד וברמזים אחרים שמבדילים בין התנהגויות.
כיצד ה-AI לומד התנהגויות חדשות ממעט מאוד דוגמאות
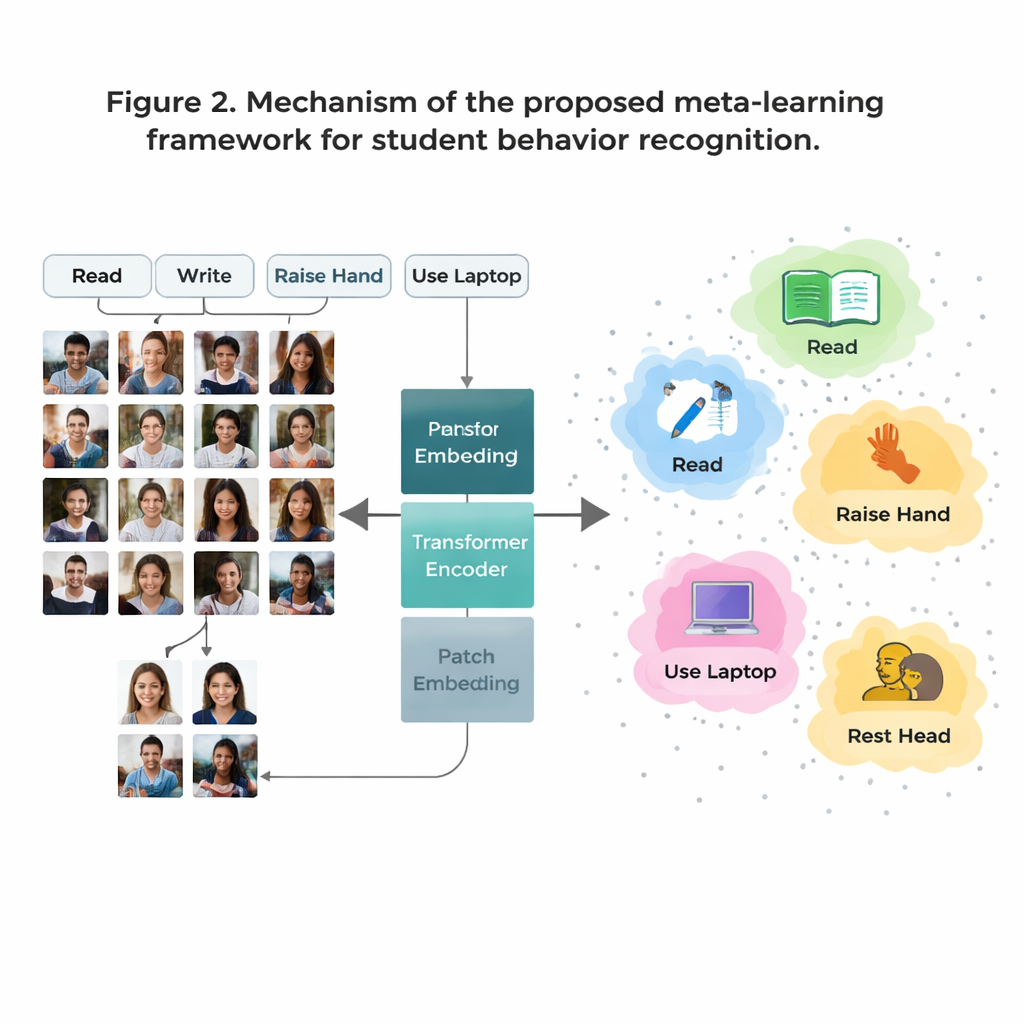
מכשול מרכזי הוא שחלק מהתנהגויות בכיתה נפוצות בנתונים (כמו קריאה) בעוד שאחרות נדירות (כמו אינטראקציות קצרות על הבמה). איסוף מספיק תמונות מתוייגות לכל התנהגות אפשרית הוא יקר ומעלה חששות פרטיות. כדי להתגבר על כך, המחברים משתמשים באסטרטגיה הנקראת "למידה ממעט דוגמאות" (few‑shot learning), שבה המודל מאומן לזהות קטגוריות חדשות מתוך גרעין קטן של דוגמאות. הם מארגנים את האימון כמספר רב של משימות קטנות, שכל אחת מהן כוללת רק כמה התנהגויות ומעט תמונות לדוגמה לכל התנהגות. עבור כל משימה המערכת יוצרת "פרוטוטיפ" פשוט לכל התנהגות על‑ידי ממוצע הייצוג הפנימי של אותן דוגמאות. לאחר מכן התמונות החדשות מסווגות לפי הפרוטוטיפ הקרוב אליהן, מה שמאפשר למודל להסתגל במהירות גם כאשר הנתונים דלים.
לראות את כל הכיתה, לא רק פרטים קטנים
מערכות תמונה מסורתיות הנקראות רשתות עצביות קונבולוציוניות נוטות להתמקד בדפוסים מקומיים קטנים, כמו קצוות או מרקמים. זה עלול להגביל כאשר שתי התנהגויות, לדוגמה קריאה וכתיבה, נראות דומות מקרוב. עבודה זו מחליפה את הרשתות הישנות הללו ב-Vision Transformer, מודל שמחלק כל תמונה לפאצ'ים ולומד כיצד כל הפאצ'ים מתקשרים זה עם זה. מבט גלובלי זה עוזר למערכת להבין הבדלים עדינים בתנוחת הגוף ורמזים לטווח ארוך — כמו הקשר בין יד מורמת למורה שמול הכיתה. הצוות מחדד עוד יותר את המודל על‑ידי אימון שאוסף יחד תמונות של אותה התנהגות ודוחק החוצה התנהגויות דומות אך שונות, עם דגש נוסף על מקרים "קשים" מבלבלים. זה יוצר מפה פנימית של ההתנהגויות שהיא נקייה וקלה יותר להפרדה.
כמה טוב זה עובד ולמה זה חשוב
במבחן SCB‑05 השיטה המוצעת מגיעה לכ‑91% דיוק כולל ונקודות חזקות במטריקות דרישות יותר שמתחשבות בנתונים לא מאוזנים. התנהגויות נפוצות כמו קריאה והנפת יד מזוהות במיוחד היטב, בעוד שפעולות נדירות יותר כמו כתיבה על הלוח עדיין מאתגרות יותר אך משתפרות לעומת מערכות קודמות. בדיקות ויזואליות של הצבירות הפנימיות של המודל מראות שהתנהגויות שונות יוצרות קבוצות הדוקות ומופרדות היטב, מה שמעיד שה-AI רכש "חתימות" מובחנות של פעולות בכיתה. כאשר נבחן על מאגר כיתתי שונה עם זוויות מצלמה ועיצובים אחרים, הביצועים ירדו רק מעט, מה שמרמז שהייצוג הנלמד אינו קשור לחדר או בית ספר יחיד.
מה זה אומר עבור הוראה ולמידה
במונחים יומיומיים, המחקר מראה שמחשבים יכולים לזהות באופן אמין רבות מהתנהגויות המפתח של תלמידים מתוך תמונות סטילס, גם כאשר נראו להם רק מעט דוגמאות מכל סוג. במקום להחליף מורים, מערכות כאלה יכולות לסכם בשקט מי מעורב, מי לבקשת עזרה תכופה, או אילו פעילויות מאבדות תשומת לב — וכל זאת מבלי לעקוב אחרי זהות התלמידים. בעבודה נוספת על פרטיות, הוגנות וצילום וידאו לאורך זמן, סוג זה של AI שמודע להתנהגות יכול להפוך לבעל ברית רב‑כוח למורים המעוניינים בעיצוב סביבות למידה תגובתיות ומכלילות יותר.
ציטוט: Abozeid, A., Alrashdi, I. & Al-Makhlasawy, R.M. Intelligent recognition of students’ behavior for smart learning environments. Sci Rep 16, 5674 (2026). https://doi.org/10.1038/s41598-026-36633-9
מילות מפתח: כיתה חכמה, התנהגות תלמיד, ראייה ממוחשבת, למידה ממעט דוגמאות, וויז'ן טרנספורמר