Clear Sky Science · he
הערכה עדינה של מודלים שפתיים גדולים ברפואה באמצעות מודל אבחוני קוגניטיבי לא-פרמטרי
מדוע זה חשוב לביקורים עתידיים אצל רופאים
מערכות בינה מלאכותית המדברות וכותבות, המכונות מודלים שפתיים גדולים, עוברות במהירות ממעבדות מחקר לבתי חולים. הן כבר יכולות לסייע לרופאים בקריאת תרשימים מורכבים, להציע טיפולים ולהשיב על שאלות רפואיות. אולם רוב הבדיקות של מערכות אלה מספקות רק ציון כולל אחד, בדומה לציון סופי במבחן, מה שעלול להסתיר נקודות עיוורון מסוכנות. המחקר הזה מציג שיטה חדשה המאפשרת להציץ בתוך אותם ציונים ולחשוף בדיוק באילו תחומי רפואה המודלים באמת מבינים – ובאילו תחומים הם עלולים לסכן מטופלים.
להסתכל מעבר לציון יחיד
כיום, רוב מערכות ה-AI הרפואיות מוערכות על פי כמה שאלות הן עונות נכון במבחנים המודליים על מבחני רישוי לרופאים. גישה זו פשוטה אך גסה. מודל עשוי לקבל ציון כולל גבוה ועדיין להיות חלש בתחום קריטי כגון ניתוח קצב הלב או מחלות כבד. במרפאות אמיתיות פערים כאלה עלולים להיות בעלי השלכות של חיים או מוות. המחברים טוענים ששימוש בטוח בבינה מלאכותית ברפואה דורש הערכה עמוקה ומפורטת יותר — כזו שמציגה פרופיל כישורים מפורט במקום להעניק ציון יחיד שעלול להטעות.

דרך חכמה יותר לבחון ידע רפואי
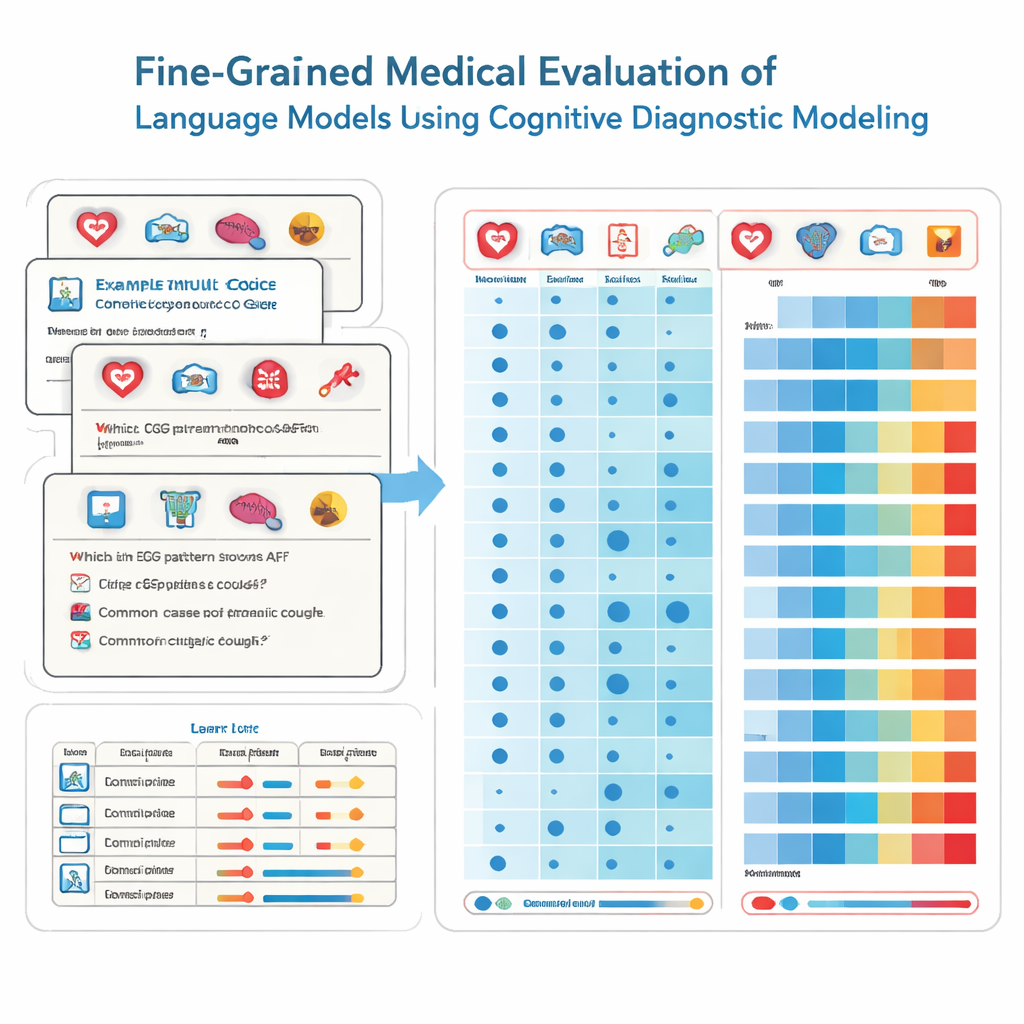
כדי להשיג זאת, החוקרים שואלים כלי עבודה מפסיכולוגיה חינוכית הנקראים הערכה אבחונית קוגניטיבית. במקום להתייחס לכל שאלה במבחן כאילו היא מודדת את אותה יכולת מעורפלת, שיטה זו מפרקת את הידע הרפואי לחסימות מיומנות ספציפיות, כמו קרדיולוגיה, רדיולוגיה או טיפול חירום. כל שאלה בסגנון רב-ברירה מתויגת עם תערובת המיומנויות המדויקת שהיא דורשת. באמצעות טכניקה סטטיסטית לא-פרמטרית, הצוות משווה כיצד מודל עונה לאלפי שאלות כאלה לדפוסי תגובה אידיאליים. מתוך זאת הם מסיקים האם המודל "שלט" בכל מיומנות בסיסית — בדומה לדו"ח מפורט המראה חוזקות וחולשות בין מקצועות בבית הספר.
מבחן ל-41 מודלי AI בבחינה רפואית
הצוות בחן 41 מודלים שפתיים נפוצים, כולל מערכות מסחריות ומודלים בקוד פתוח, על 2,809 שאלות שנבדקו בקפידה ונלקחו מבנק מבחנים רפואי לאומי בסין. שאלות אלה מכסות 22 תת-תחומים רפואיים ומיועדות לסטודנטים המתכוננים למבחן רישוי לרפואה. לכל שאלה יש תשובה נכונה אחת והיא מתוייגת על ידי מומחים כדי לציין אילו تخصصים היא נוגעת בהם. בעזרת שיטת האבחון שלהם, החוקרים העריכו, עבור כל מודל, כמה מתוך 22 התכונות הרפואיות הללו הוא למעשה שלט בהן, לא רק כמה שאלות ענה להן נכון במקרה.
ידע כללי חזק, אבל פערי תמונה חדים
התוצאות מרשימות ומדאיגות גם יחד. המודלים המצטיינים ביותר, כמו כמה מהמערכות המסחריות המובילות, ענו נכון על רוב השאלות והראו שליטה ב-20 מתוך 22 תחומי רפואה. בכל המודלים הממוצע היה מצוין במגוון תחומים שכיחים, עם שליטה מלאה ב-15 תחומים כולל קרדיולוגיה, דרמטולוגיה ואנדוקרינולוגיה. יחד עם זאת, הניתוח המפורט חשף פערים בולטים בתחומים אחרים. הרדיולוגיה נשארה מאחור עם שיעורי שליטה נמוכים משמעותית, ושני תת-תחומים — ECG & יתר לחץ דם & שומנים ומחלות כבד — לא נשלטו על ידי אף מודל. חשוב לציין שחלק מהמודלים הקטנים הפגינו את אותן מיומנויות נשלטות כמו מודלים גדולים בהרבה, מה שמראה שהגודל בפני עצמו איננו מבטיח ידע רפואי רחב ומהימן.
לבחור את הכלי הנכון למשימה הנכונה
פרופילים מפורטים אלה חשובים משום שמודלים עם ציונים כוללים דומים יכולים להציג דפוסים שונים מאוד של חוזקות וחולשות. מערכת אחת עשויה להיות חזקה בנוירולוגיה אך חלשה בפרמקולוגיה, בעוד שאחרת מציגה את הדפוס ההפוך. למנהלי בתי חולים משמעות הדבר היא שהם לא יכולים לבחור באופן בטוח עוזר AI רק על סמך ציון הכותרת או מספר הפרמטרים. במקום זאת הם זקוקים לתוצאות אבחוניות כמו אלה שבמחקר זה כדי להתאים כל מודל למשימות קליניות ספציפיות, ולעצב תהליכי עבודה שבהם מומחים אנושיים בודקים את פלט ה-AI באזורים עם סיכון גבוה שבהם המודל ידוע כחלש.
מה משמעות הדבר עבור מטופלים ורופאים
באופן פשוט, המחקר מסכם כי "ציון" גבוה במבחנים רפואיים אינו מבטיח שמערכת AI בטוחה לשימוש בכל חלקי הרפואה. הגישה החדשה פועלת יותר כמו בדיקת בריאות מעמיקה ל-AI עצמו, וחושפת אילו "איברים" — במקרה זה, תחומים רפואיים — בריאים ואילו צריכים תשומת לב. על ידי גילוי פערים נסתרים בתחומים קריטיים כמו פרשנות ECG ומחלות כבד, השיטה נותנת לבתי חולים, לרגולטורים ולמפתחים מפת דרך מעשית: להשתמש במודלים רק במקום שהוכחו כחזקים, לשמור על התערבות אנושית היכן שהחלשות נמשכות, ולהתמקד בהכשרה עתידית על נקודות העיוורון המסוכנות ביותר. המחברים טוענים שסוג זה של הערכה עדינה אינו רק מועיל — הוא חיוני לפני שמפקידים בינה מלאכותית בטיפול בחולים.
ציטוט: Zheng, T., Liu, J., Feng, S. et al. Fine-grained evaluation of large language models in medicine using non-parametric cognitive diagnostic modeling. Sci Rep 16, 6460 (2026). https://doi.org/10.1038/s41598-026-36627-7
מילות מפתח: בינה מלאכותית רפואית, מודלים שפתיים גדולים, בטיחות קלינית, הערכת מודלים, בדיקות אבחוניות