Clear Sky Science · he
אופטימיזציה רב‑משימתית ויציבות התכנסות עם למידת תכונות היררכית לאופטימיזציה מונחית‑עצמית
בינה חכמה שיודעת לנהל כמה משימות במקביל
יישומים מודרניים מסתמכים יותר ויותר על בינה מלאכותית שצריכה לבצע כמה דברים בו‑זמנית — למשל להבין תמונות וטקסט יחד, לתמוך בהחלטות רפואיות או לסייע לרכבים לתפוס את הדרך. אבל כאשר מודל אחד לומד יותר מידי מיומנויות בבת אחת, האימון עלול להפוך לבלתי יציב והמיומנויות עלולות להפריע זו לזו. מאמר זה מציג מסגרת למידה עמוקה חדשה, שנקראת Unified Multitask and Multiview Deep Architecture (UMDA), שנועדה לאפשר למודל יחיד ללמוד מסוגי נתונים רבים ולפתור משימות רבות מבלי להתבלבל או להפוך לבלתי יציב.
מדוע בינה רב‑מיומנותית מתקשה כיום
מרבית המערכות הקיימות שמלמדות כמה משימות (למידת רב‑משימות) או משלבות כמה מקורות נתונים, כגון תמונות וטקסט (למידת רב‑מבט), סובלות משלוש בעיות מרכזיות. ראשית, משימות שונות יכולות להתנגש במהלך האימון: שיפור בביצוע של משימה אחת עלול להרע בשקט לאחרת — בעיה הידועה כהעברה שלילית. שנית, ערימה פשוטה או ממוצע של מידע ממקורות שונים מאבדת לעיתים קשרים עדינים אך חשובים ביניהם. שלישית, תהליך האימון עצמו עלול להפוך רעוע, עם תנודות גדולות בכיוון העדכונים של פרמטרי המודל. בעיות אלה חמורות במיוחד בהקשרים אמיתיים כמו אבחון רפואי או בדיקות תעשייתיות, שבהם הנתונים מורכבים וההחלטות צריכות להיות אמינות.
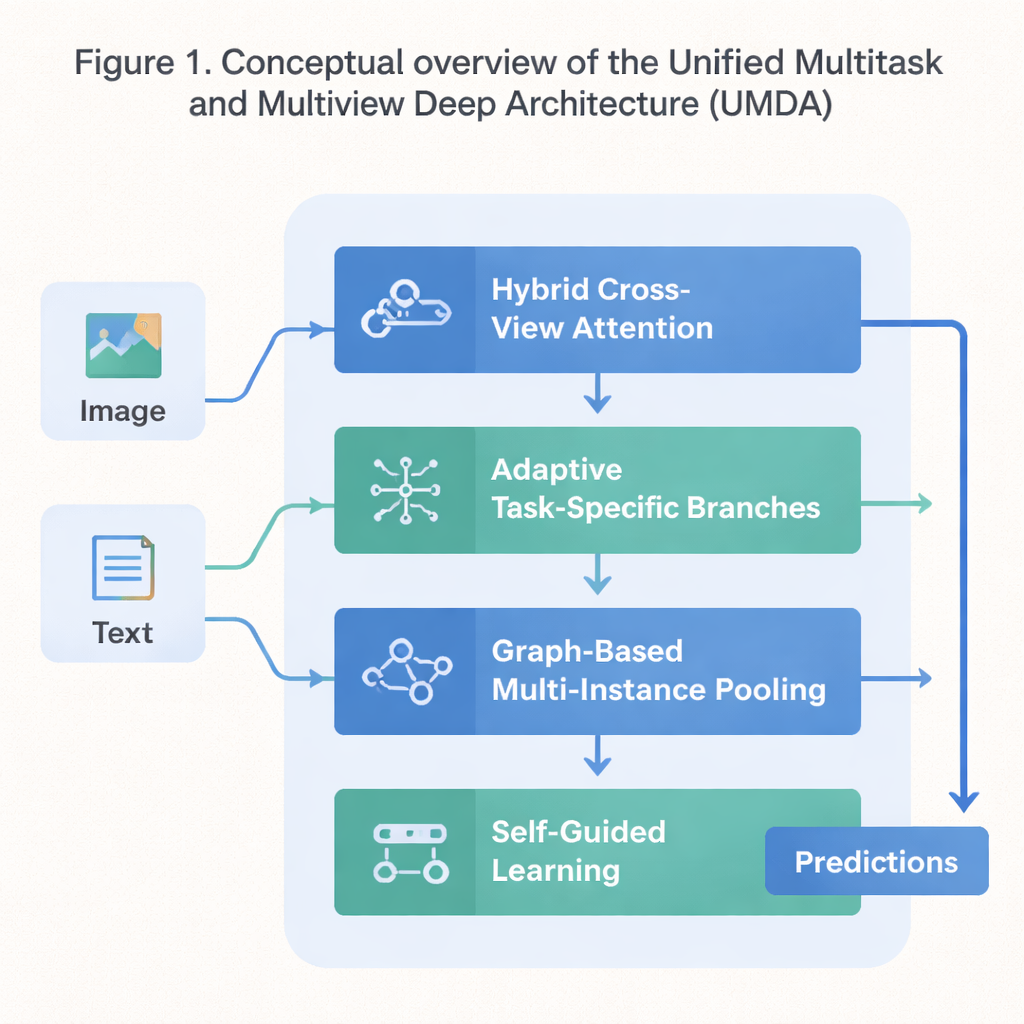
מתווה בעל ארבעה חלקים ללמידה שיתופית
UMDA מתמודד עם חולשות אלה על‑ידי פירוק תהליך הלמידה לארבעה חלקים צמודים שמשתפים מידע באופן מבוקר. החלק הראשון, שנקרא Hybrid Cross‑View Attention, בוחן מבטים שונים של אותו נתון — כגון טקסט ותמונות שמתארים סרט — ולומד איזה מבט צריך להשפיע על האחר בכל שלב. הוא משתמש בכלים מתמטיים שמעודדים את המודל להימנע מהסתמכות יתר על מבט יחיד, לשמור על ייחודיות כל מבט, ובאותו זמן לשמור על התאמה כללית ביניהם. במילים פשוטות, זה מלמד את המודל להאזין לכל ה"חושים" שלו מבלי לאפשר לאחד מהם להשתלט על האחרים.
שמירה על משימות מובחנות אך שיתופיות
החלק השני, Adaptive Task‑Specific Branching, מעריך ידע כללי שמשותף לרבות מהמשימות מול ידע ייחודי שכל משימה צריכה. במקום לכפות על כל המשימות להשתמש באותם תכונות בדיוק, UMDA בונה "ענפים" נפרדים לכל משימה שעדיין יכולים לתקשר ביניהם דרך חיבורים משוקללים בקפידה. תנאי עונש נוספים באובייקט האימון דוחפים ענפים אלה להיות שונים מספיק כדי להתמחות, אך לא כה שונים עד שיפרידו וישתחררו משיתוף פעולה. האיזון הזה מסייע להפחית הפרעות מזיקות בין משימות ועדיין לאפשר להן להרוויח ממה שאחרות לומדות.
לראות מבנה באוספי דוגמאות
במקרים רבים מערכי נתונים מגיעים כאוספים של פריטים קשורים — למשל חתיכות תמונה מרובות משקף פתולוגי אחד או מסגרות רבות מתוך וידאו. החלק השלישי של UMDA, Graph‑Based Multi‑Instance Pooling, ממודל במפורש את הקשרים בין פריטים אלה על‑ידי התייחסות אליהם כצמתים ברשת. הוא מחבר פריטים דומים, מאפשר זרימת מידע לאורך הקישורים האלה, ואז מסכם את כל האוסף לייצוג קומפקטי יחיד. רגולריזציה נוספת דוחפת פריטים קרובים להסכים זה עם זה תוך שמירה על מספיק גיוון, מה שמאפשר למודל ללכוד תבניות מבניות שממוצע פשוט היה מפספס.
אימון מכוון‑עצמי להתקדמות יציבה
החלק האחרון, Self‑Guided Learning, מתמקד באופן שבו המודל מאומן יותר מאשר במבנה הפנימי שלו. הוא מודד ברציפות עד כמה חזקים ומהם הדמיון של אותות האימון של כל משימה ואז מתאים אוטומטית את קצב הלמידה לכל משימה. הוא גם מיישן ומשקלל מחדש את הגרדיאנטים — האותות שאומרים למודל כיצד לשנות את עצמו — כך שמשימות עם מטרות דומות יחזקו זו את זו ומשימות הפועלות בכיוונים שונים לא יזיזו את האימון לכיוון בלתי יציב. בבדיקות על מערך נתונים סטנדרטי המשלב עלילות סרטים ופוסטרים, UMDA השיג דיוק ממוצע גבוה יותר מאשר תריסר מתחרים מתקדמים, שמר על עקביות גבוהה יותר בין המבטות והפחית מדד מרכזי של אי‑יציבות האימון ביותר מחצי.
מה המשמעות של זה למערכות בינה אמיתיות
ללא‑מומחים, המסר המרכזי הוא ש‑UMDA מציעה דרך לבנות מודלים יחידים שיכולים להתמודד עם סוגי נתונים ומטרות רבות באופן אמין יותר. על‑ידי לימוד המודל מתי לשתף מידע ומתי לשמור אותו נפרד, ועל‑ידי אפשרות כוונון אוטומטי של אופן הלמידה, המסגרת מספקת תחזיות טובות יותר, ייצוגים פנימיים קוהרנטיים יותר ואימון חלק יותר. זה הופך אותה לגוש בניין מבטיח למערכות עתידיות ברפואה, בנהיגה אוטונומית וביישומים מורכבים אחרים שבהם הבינה צריכה לפרש אותות רבים בו‑זמנית מבלי לאבד איזון.
ציטוט: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
מילות מפתח: למידת רב‑משימות, בינה רב‑ממדית, יציבות בלמידה עמוקה, רשתות תשומת לב, רשתות נוירוניות גרפיות