Clear Sky Science · he
שיטה לפירוק עמימות של ישויות בטקסטים קצרים המבוססת על מודל BERT ואלגוריתם המסלול הקצר ביותר
למה חשוב למיין שמות מבלבלים
כל יום אנו מחפשים, גוללים ומשוחחים באמצעות קטעי טקסט קצרים ולעתים מבולגנים—ציוצים, שאילתות חיפוש, הודעות צ'אט. הקטעים הללו מלאים בשמות של אנשים, מקומות, חברות ודברים שיכולים להתכוון ליותר ממשמעות אחת, כמו “Apple” הפרי או “Apple” החברה. מחשבים חייבים לנחש איזו משמעות התכווננו להעניק, וכאשר הניחוש שגוי תוצאות החיפוש, המלצות ושירותים מקוונים נעשים פחות שימושיים. מאמר זה מציג דרך חדשה לסייע למכונות לפרש נכון שמות כפולים בטקסטים קצרים, במיוחד במדיה חברתית וחיפוש בסינית, על ידי שילוב של מודלים לשוניים מודרניים עם אלגוריתם גרפי מחוכם.
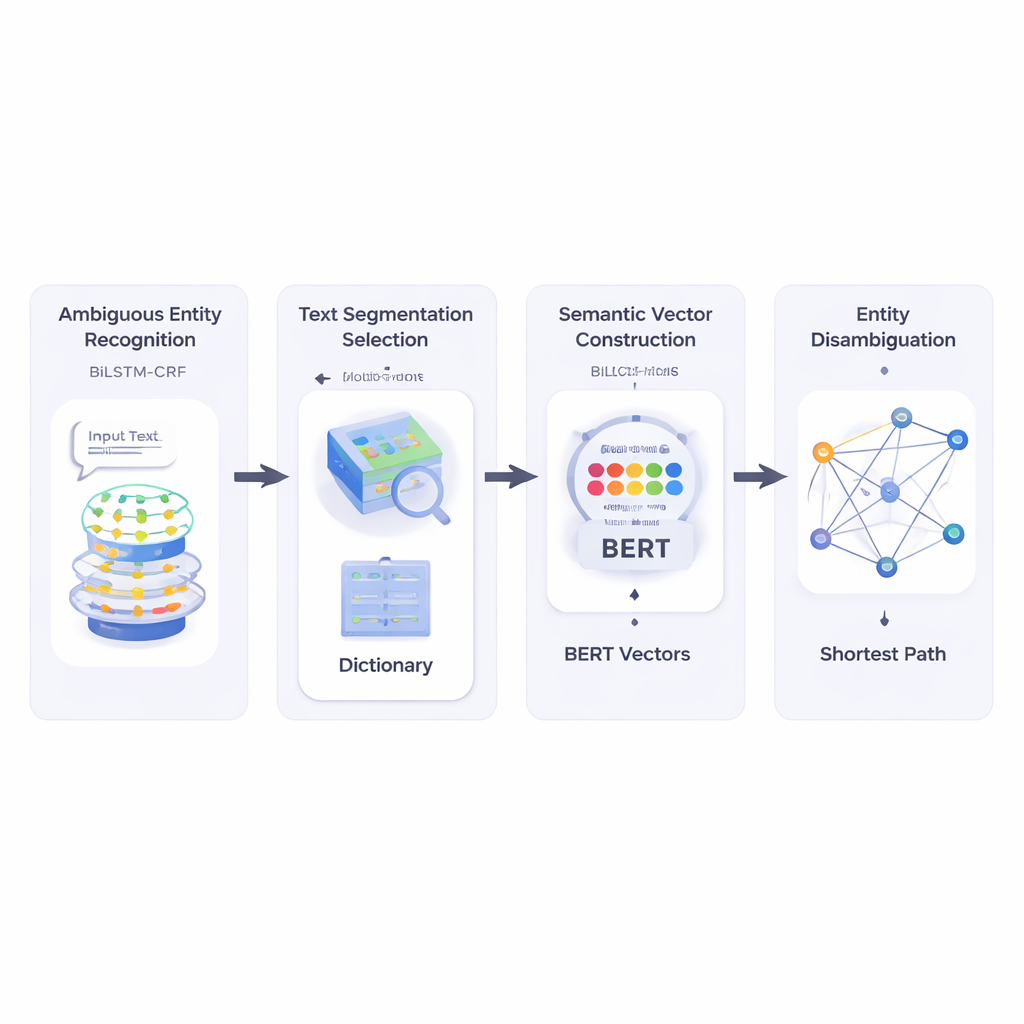
מטקסטים קצרים ומבולגנים ליעדים ברורים
טקסטים קצרים קשים באופן מפתיע להבנה על ידי מחשבים. בניגוד למאמרים ארוכים, הם מספקים מעט הקשר ולעתים עבים בסלנג, קיצורים ומשפטים לא שלמים. שיטות מסורתיות ניסו להתאים שם בטקסט לרשומות בבסיס ידע, או השתמשו בכלליים מעוצבים ובמודלים פשוטים יותר של למידת מכונה. גישות אלה לעתים מתייחסות לכל מילה כבעלת משמעות קבועה אחת, מה שמכשיל כאשר אותה מילה יכולה לייצג תואר עבודה, חברה או שיר, תלוי בהקשר. התוצאה היא בלבול תכוף לגבי איזו ישות בעולם האמיתי מתייחסת מילה בציוץ או בשאילתה.
להכשיר את המערכת לזהות שמות מעורפלים
המחברים בונים תחילה מערכת שקוראת טקסט קצר ומזהה אילו חלקים הם שמות ישויות ואילו מהם עשויים להיות מעורפלים. הם משתמשים בשילוב רשת עצבית שנקרא BiLSTM‑CRF, המתמחה בתיוג רצפי מילים על ידי בחינת ההקשר משני הצדדים. לאחר שסומנו ישויות פוטנציאליות, המערכת מתייעצת במשאב אוצר מילים גדול בשם HowNet. אם HowNet מפרט מספר משמעויות למילה, היא מסומנת כמעורפלת; אם קיימת רק משמעות אחת, המילה נחשבת ברורה. שלב זה מספק למערכת רשימה ממוקדת של שמות שצריך באמת לפשר.
להפוך משמעויות לנקודות במרחב
בהמשך, השיטה מפרקת את הטקסט הקצר למקטעי מילים מועמדים ובוחרת את ההפרדה הטובה ביותר על ידי בדיקה עד כמה כל חיתוך אפשרי מתיישב במשמעותו עם מילות ייחוס ברורות באותו משפט. למדידה זו המחברים מסתמכים על BERT, מודל שפה מאומן מראש שמייצר "וקטור סמנטי" מספרי לכל שימוש במילה, תוך לכידת משמעותה התלויה בהקשר. על ידי חישוב דמיון קוסינוס בין הווקטורים הללו, המערכת מוצאת את ההפרדה שהחלקים שלה הכי תואמים סמנטית עם מונחי הייחוס הלא‑מעורפלים. זה מאפשר למודל לייצג כל משמעות אפשרית של כל מילה כנקודה במרחב רב‑ממדי.
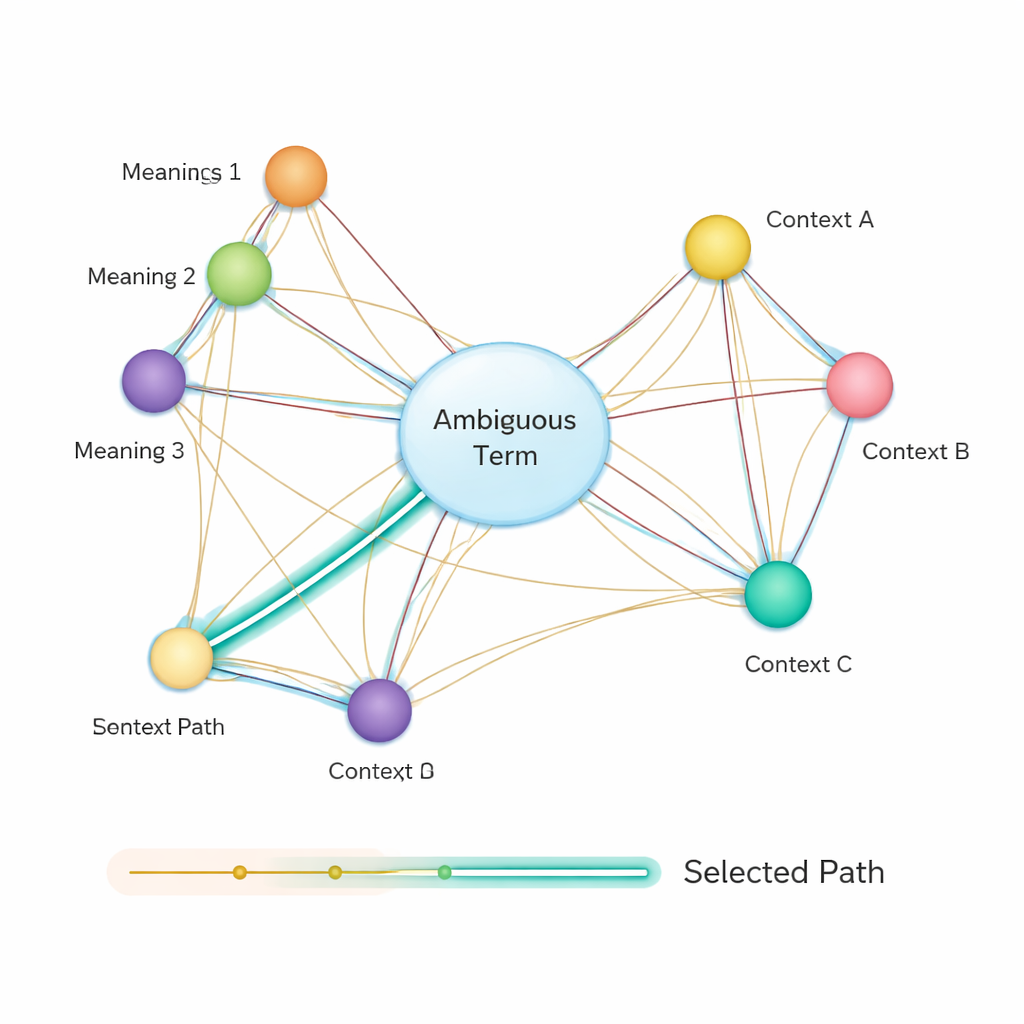
למצוא את המסלול הקצר ביותר למשמעות הנכונה
לאחר מכן, השיטה בונה רשת סמנטית: גרף שבו כל משמעות אפשרית של כל מונח היא Node, וקשתות מחברות משמעויות שייתכן שיופיעו יחד באותו משפט. חוזק כל קשת מבוסס על מידת הדמיון בין המשמעויות, שוב באמצעות וקטורים מבוססי BERT. כדי להכריע איזו משמעות של מילה מעורפלת מתאימה ביותר למשפט, המחברים מיישמים אלגוריתם קלאסי הידוע כאלגוריתם המסלול הקצר ביותר של דייקסטרה. באופן אינטואיטיבי, המערכת מחפשת את המסלול בגרף המשמעויות ששומר על "מרחק" סמנטי מצטבר מינימלי. המסלול הנבחר תואם לפרשנות עקבית של כל המונחים, והתחום של הישות המעורפלת שנמצא על מסלול זה נבחר כתשובה הסופית.
כמה זה משתפר בפועל?
החוקרים בדקו את שיטתם על מאגר נתונים סיני ציבורי מתוך הבנצ'מרק CLUE, המדמה תרחישים אמיתיים של טקסטים קצרים כמו פוסטים ברשתות חברתיות ושאילתות. הם השוו ארבע גישות: גרסאות המשתמשות באמבדיִניגס מסורתיים מסוג Word2Vec, במודל השפה ELMo, במערכת מבוססת BERT ללא שלב המסלול‑הקצר, ובצינור המלא שלהם BiLSTM‑CRF‑BERT‑SPA. לאורך אלפי טקסטים השיטה המלאה שלהם שיפרה דיוק, זיכרון וניקוד F1 בכ־25% בממוצע בהשוואה לאחרות. במונחים פרקטיים, המערכת היתה גם טובה יותר בזיהוי הישויות הנכונות וגם בעקביות על פני גדלים שונים של נתונים.
מה זה אומר לטכנולוגיה היומיומית
עבור קורא שאינו מומחה, המסקנה ברורה: על ידי שילוב מודל הבנת שפה חזק (BERT) עם חיפוש מבוסס גרף של המסלול הקצר ביותר, המחברים נותנים למחשבים דרך אמינה יותר להכריע למה מתייחס שם מעורפל בטקסטים קצרים ורועשים. זה יכול להפוך מנועי חיפוש לחכמים יותר, לסייע לפלטפורמות חברתיות להבין פוסטים טוב יותר, ולשפר כלים משניים כמו מערכות המלצה וגרפי ידע. בעוד שהשיטה מותאמת כיום לסינית ועדיין יש מקום לשיפורים ביעילות, היא ממחישה כיצד שילוב בין AI מודרני לאלגוריתמים קלאסיים יכול לצמצם באופן משמעותי בלבול בפירוש השפה היומיומית שלנו.
ציטוט: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
מילות מפתח: פירוק עמימות ישויות, טקסט קצר, BERT, גרף ידע, עיבוד שפה טבעית