Clear Sky Science · he
הפרדת תוכן וסגנון לייצור תמונות מרובות סגנונות באמצעות ארכיטקטורת דיפוזיה לטנטית
למה סגנונות תמונה חכמים יותר חשובים
מפוסטרים של סרטים ואמנות משחקים ועד פילטרים ברשתות החברתיות — אנו מצפים שיותר ויותר שהתמונות יהיו הן מרשימות ויזואלית והן מותאמות אישית. אבל מאחורי הקלעים, מערכות רבות להעברת סגנון עדיין מתקשות: הן עלולות לעוות פנים של אנשים, לעקם מבנים או לדרוש חומרה כבדה. מאמר זה מציג מודל בינה מלאכותית חדש שמבטיח סגנונות אמנותיים עשירים יותר תוך שמירה על התמונה המקורית ופועלו ביעילות מספקת עבור מכשירים יומיומיים.
להפריד בין “מה זה” ל“איך זה נראה”
בלב העבודה הזו עומד מודל בשם Dual-Condition Lightweight Style Diffusion Model (DCLSDM). הרעיון המרכזי שלו הוא להתייחס לתוכן התמונה — האובייקטים, הסידור והסצנה — כ"ערוץ" אחד, והטיפול האמנותי — צבעים, מרקמים, מברשות — כ"ערוץ" אחר, ולשלוט בהם בנפרד. במקום לאפשר לרשת בודדת לערבב בין שני ההיבטים האלה, DCLSDM משתמש בשתי דרכים ייעודיות: אחת לתוכן ואחת לסגנון. נתיב התוכן מתמקד בהבנת צורות ומשמעויות בתמונה קלט או בתיאור טקסטואלי, בעוד נתיב הסגנון לומד את האופי הוויזואלי של יצירה נבחרת או של תיאור סגנוני.
איך המודל החדש בנוי
DCLSDM מבוסס על מודלים דיפוזיוניים, אותה משפחת טכניקות שמאחורי רבים מהמחוללי תמונות המודרניים. במקום לעבוד ישירות על תמונות ברזולוציה מלאה, המודל פועל במרחב "לטנטי" דחוס, שהוא יעיל הרבה יותר. מודול בשם Perceiver IO מפיק את התוכן: הוא מקבל תמונה או כתובית ומעבה את הגאומטריה והסמנטיקה של הסצנה לייצוג קומפקטי. מודול סגנון נפרד קורא תמונות סגנון או טקסטים מרובים וממיר אותם לווקטורי תכונות סגנוניים. תכונות סגנון אלה ניתנות לערבוב באמצעות סכמת אינטרפולציה מושקלת, המאפשרת מעבר חלק בין, למשל, מראה אימפרסיוניסטי לבין מינימליסטי בלי ה"ממוצע" העכור הרגיל.
שמירה על מבנה תוך שינוי סגנון
בתוך רשת הדיפוזיה שמייצרת בפועל את התמונה, שני סוגי המידע מוזרקים דרך מסלולים עצמאיים. אותות התוכן מדריכים את שכבות הרשת שמתחשבות במבנה — היכן תקננה להיות קצוות, אובייקטים ופריסות. אותות הסגנון מוזרקים דרך שכבות תשומת לב ייעודיות שעיקר משימתן לעצב מרקמים, צבעים ועבודת מברשת. בנוסף לכך, רכיב בשם ControlNet מוסיף הדרכה מבנית נוספת באמצעות מפות קצה או עומק המופקות מהתוכן המקורי. השילוב הזה מאפשר למערכת לצבוע מחדש נוף קייצי בפלטת חורף, או להציג צילום כציור בסגנון ואן גוך, תוך שמירה על ההרמוניה של הרים, עצים ובניינים במקום הנכון וללא עיוות.
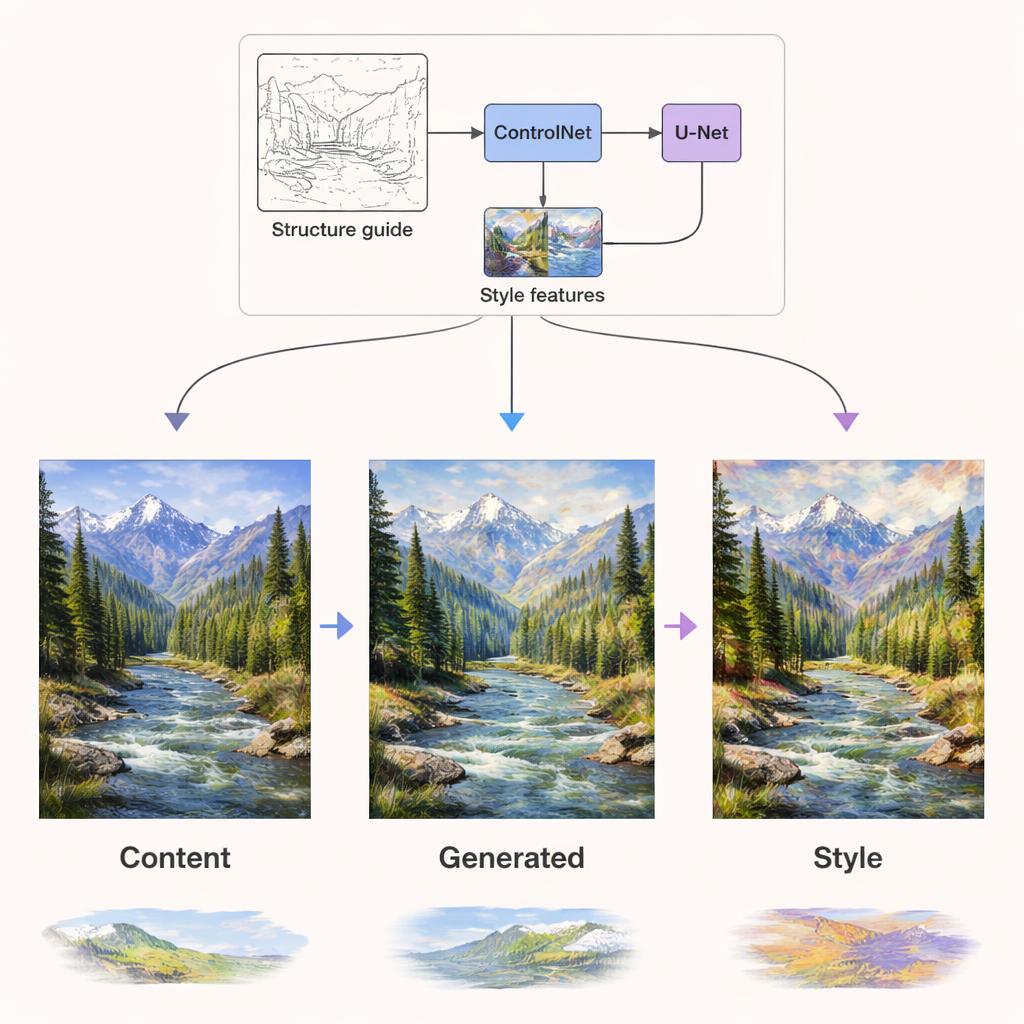
איכות טובה יותר, יותר סגנונות, פחות חישוב
המחברים בדקו בקפדנות את DCLSDM על שני מאגרים ציבוריים: WikiArt, המכסה עשורים של תנועות אמנות, ו-Summer2Winter Yosemite, שמתמקד בשינויי עונות בנוף. הם השוו את המודל שלהם לטווח של מערכות מתקדמות המשמשות במחקר ובתעשייה. במדדי דמיון מבני, איכות ויזואלית נתפסת ובמידת הקרבה של התמונות המיוצרות ליצירות אמנות אמיתיות, DCLSDM הגיע בעקביות לציונים הגבוהים ביותר. הוא גם פועל מהר יותר, צורך פחות זיכרון ויש לו פחות פרמטרים מאשר מתחרים רבים, ועדיין מציע מיקס גמיש של סגנונות מרובים ותומך בקלט סגנוני מבוסס תמונה וגם טקסט.
מה זה אומר ליצירתיות היומיומית
במונחים מעשיים, עבודה זו מראה שניתן להעניק למשתמשים שליטה מדויקת על איך תמונה נראית בלי להתפשר על מה שהתמונה מציגה — ובכדי לעשות זאת על חומרה צנועה יותר. מעצבים יוכלו לבחון במהירות טיפולים אמנותיים רבים של אותה פריסה, אפליקציות מובייל יוכלו להציע פילטרים עשירים יותר שאינם מעקמים פנימיות או סצנות, ופרויקטים לשימור מורשת תרבותית יוכלו לשנות את סגנון תמונות ישנות תוך שמירה על פרטים מבניים חיוניים. באמצעות הפרדה ברורה בין תוכן לסגנון במסגרת דיפוזיה מודרנית, DCLSDM מצביע על עתיד שבו כלי יצירה לתמונות יהיו גם חזקים יותר וגם מהימנים יותר לשימוש יומיומי.
ציטוט: Chu, K., Shang, Y., Zhang, L. et al. Content style decoupling for multi style image generation using latent diffusion architecture. Sci Rep 16, 6642 (2026). https://doi.org/10.1038/s41598-026-36407-3
מילות מפתח: העברה של סגנון תמונה, מודלים דיפוזיוניים, הפרדה בין תוכן לסגנון, יצירת אמנות דיגיטלית, ייצור תמונות יעיל