Clear Sky Science · he
מסגרת למידה בחיזוק עבור בחינות אדפטיביות ממוחשבות בשיטת ה- multi-armed bandit
מבחנים חכמים יותר לכיתה הדיגיטלית
כל מי שישב במבחן ארוך ואחיד יודע כמה זה יכול להיות משעמם ובלתי הוגן. חלק מהשאלות קלות מדי, אחרות בלתי אפשריות, והציון הסופי עשוי שלא לשקף באמת את מה שאתה יודע. מאמר זה מציג דרך חדשה לבנות מבחנים ממוחשבים שמתאימים, בזמן אמת, לתשובות של כל אדם. בהשאלה מרעיונות מהבינה המלאכותית המודרנית, הכותבים שואפים לקצר את המבחנים, לשפר את הדיוק ולתאם טוב יותר את הבדיקה ליכולת האמיתית של כל נבחן.
מדוע מבחנים קבועים לא מספיקים
מבחנים מסורתיים נותנים לכל תלמיד את אותו אוסף שאלות. זה עושה את יצירת המבחן פשוטה, אך מבזבז מידע: תלמידים חזקים מתקשים לעבור דרך פריטים קלים רבים, בעוד תלמידים מתקשים מוצפים במהירות. מבחנים אדפטיביים ממוחשבים מנסים לתקן זאת על‑ידי בחירת השאלה הבאה בהתאם לתשובות הקודמות, אך רוב המערכות הנוכחיות עדיין מתבססות על מודלים סטטיסטיים ותפיסות שנבנו במשך עשרות שנים וחוקים ידניים. גישות ישנות אלה מתקשות לתפוס דפוסי תשובות מורכבים ולעיתים לא מסוגלות להתאים במלואן להבדלים הרחבים בין לומדים בהגדרות מקוונות מודרניות ובקנה מידה גדול.
להכניס בינה מודרנית למבחנים
הכותבים מציעים מסגרת חדשה שמשלבת למידה עמוקה ולמידה בחיזוק כדי להנחות מבחנים אדפטיביים מתחילתם ועד סופם. המערכת פועלת במחזורים חוזרים. ראשית, רשת עצבית קונבולוציונית חד‑ממדית (1D‑CNN) מנתחת את תשובותיו האחרונות של הנבחן, את קושי השאלות, וסטטיסטיקות סיכום נוספות. מתוך זרם נתונים זה היא מפיקה מספר יחיד המייצג את רמת המיומנות הנוכחית של האדם בסקאלה מנורמלת, בדומה לאופן שבו תיאוריות בדיקה מסורתיות מתארות יכולת אך נלמד ישירות מהנתונים. רשת זו מאומנת לזהות דפוסים עדינים כמו הצלחות עקביות על שאלות קשות או טעויות בלתי צפויות על שאלות קלות. 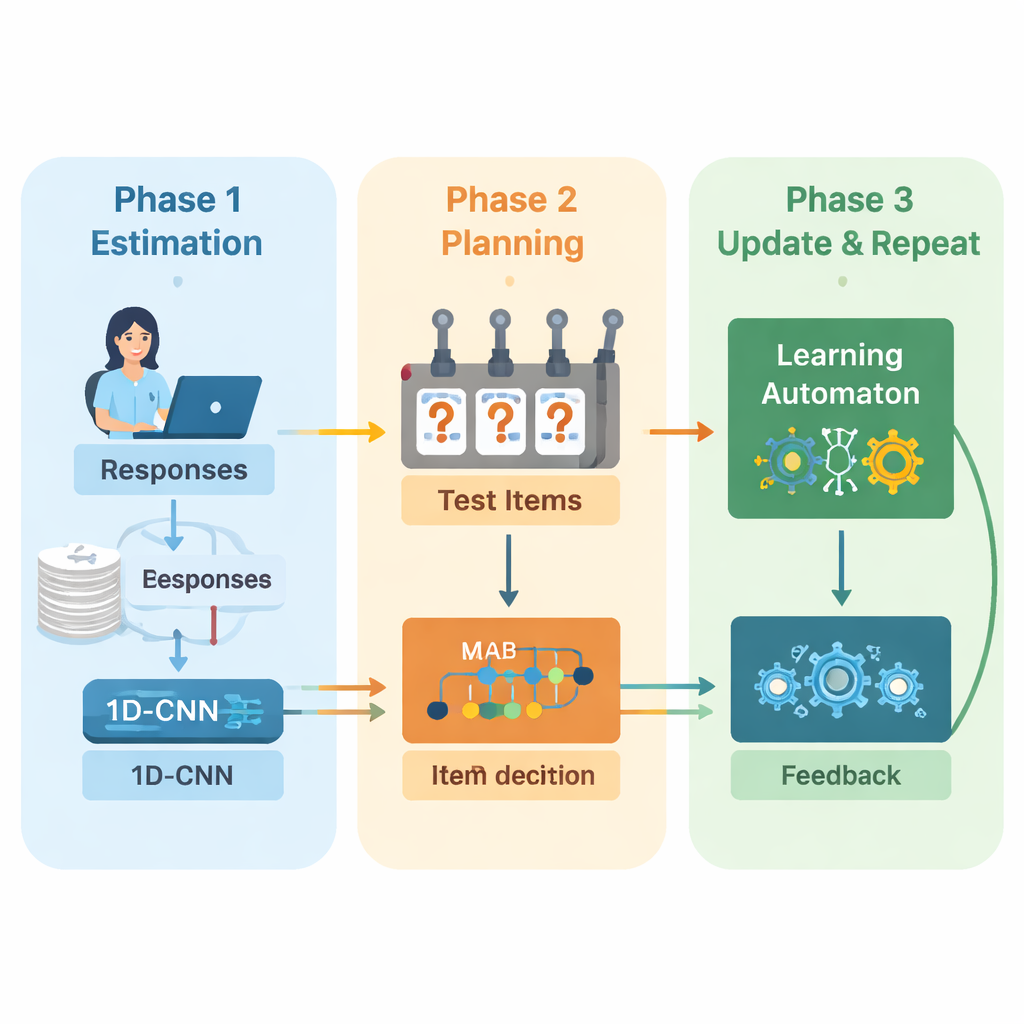
בחירת השאלה הבאה הנכונה
לאחר שלה למערכת יש הערכה מעודכנת של היכולת, עליה להחליט מה לשאול הלאה. כאן הכותבים משתמשים באסטרטגיית "multi‑armed bandit", כלי קלאסי מתורת ההחלטה שבו כל פעולה אפשרית מטופלת כמו משיכת ידית במכונת מזל. בהקשר זה, כל שאלה בבנק הפריטים היא מסרק (arm). האלגוריתם מתמקד בשאלות שקושין מתאים בקירוב לאומדן המיומנות הנוכחי ואז בוחר את אלו שנחשבות ליותר אינפורמטיביות. הוא מאזין בין שתי מטרות: השגת התאמת קושי טובה, כדי שהתשובות לא יהיו קלות מדי ולא קשות מדי, וכיסוי כמה שיותר תחומים תכניים, כדי שהמבחן לא יתעלם מנושאים חשובים. ציון תגמול שמשלב בין שתי המטרות הללו מנחה את תהליך הבחירה.
לומד מהחלטותיו שלו
כדי להשתפר ככל שהמבחן מתקדם, המערכת מוסיפה רכיב למידה נוסף הנקרא אוטומט למידה (learning automaton). מודול זה צופה כיצד אומדן היכולת משתנה בין סבבים והאם דיוקו של הנבחן משתפר או יורד. הוא מתאים קבוצה קטנה של הסתברויות המסכמות האם המודל צופה שהיכולת תעלה, תישאר קבועה או תרד. הסתברויות אלה מוזנות חזרה כקלט נוסף לרשת הנוירונים בסבב הבא. כך מנוע המבחן לא רק לומד על התלמיד, אלא גם על החלטותיו הקודמות—מעניק תגמול למגמות שהובילו לאומדנים מדויקים ועונש למגמות שלא הניבו תוצאות. 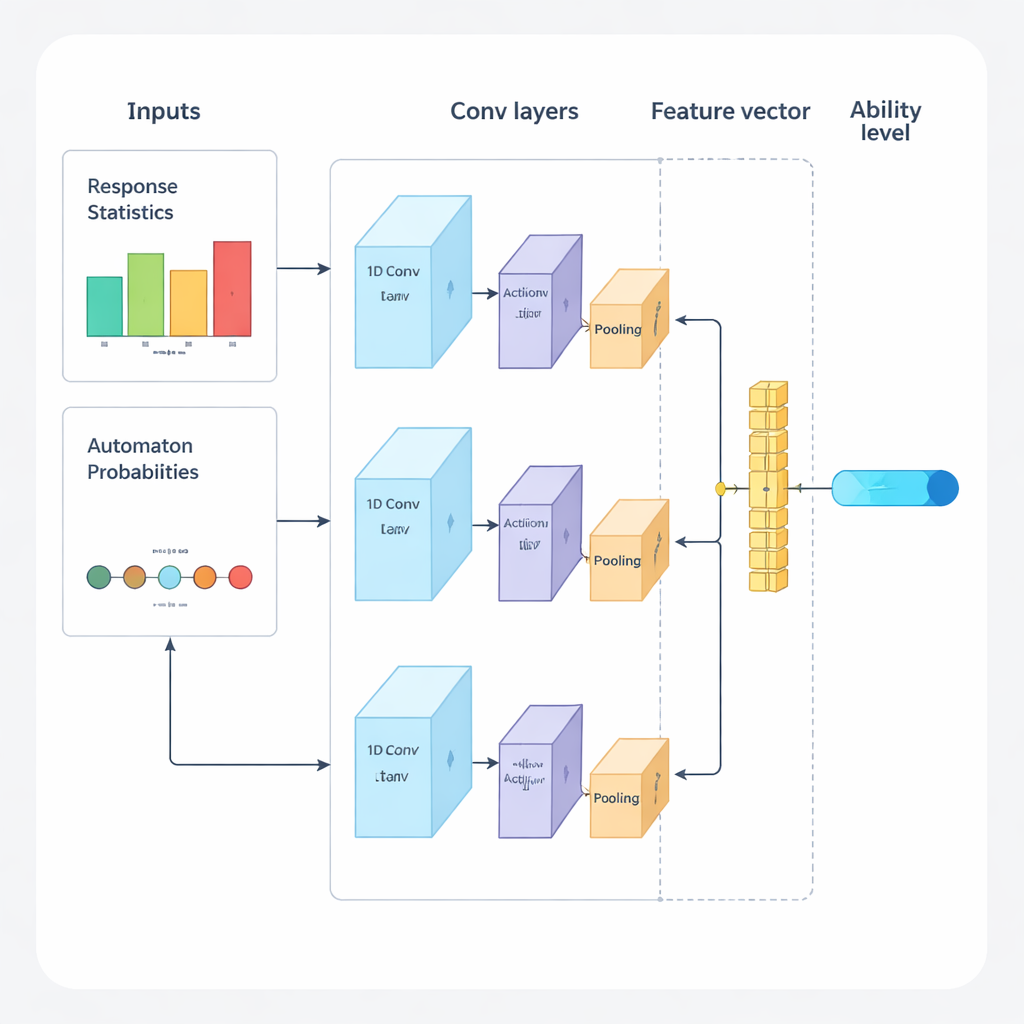
כמה זה עובד בפועל?
החוקרים העריכו את המסגרת שלהם באמצעות מאגר נתונים גדול רב‑לשוני של מבחנים ואלפי נבחנים מדומים שהרמות האמיתיות שלהם היו ידועות. הם השוו את הגישה שלהם עם מספר שיטות אדפטיביות מובילות. לאורך טווח של מדדי שגיאה וקורלציה, המערכת החדשה הפיקה אומדנים מדויקים יותר של היכולת תוך שימוש בפחות שאלות. השגיאות שלה—נמדדות באמצעות סטטיסטיקות מקובלות כגון שורש ממוצע ריבועי של השגיאה (RMSE) ושגיאה מוחלטת ממוצעת (MAE)—היו נמוכות באופן מובהק ביחס לשיטות מתחרות. במקביל, היא פיזרה את השימוש בשאלות בצורה שוויונית יותר בבנק הפריטים, והקטינה את הסיכון ששאלות מסוימות ייחשפו באופן יתר ודולפו.
מה משמעות הדבר למבחנים בעתיד
במונחים יומיומיים, עבודה זו מרמזת שמבחנים ממוחשבים עתידיים יכולים להרגיש יותר כמו מפגש חונכות מותאם מאשר מבחן קשיח. השאלות יתמקמו במהירות ברמת הקושי הנכונה לכל אדם, יבחנו את טווח הנושאים המלא שחשוב, ויסתיימו כאשר המערכת תהיה בטוחה ברמתך—לעיתים בפחות פריטים מאשר במבחנים של היום. אף שהשיטה עדיין תלויה בנתוני אימון איכותיים ובכוח חישוב, ועד כה נבדקה על מאגר נתונים יחיד, היא מצביעה על דור חדש של הערכות חכמות, הוגנות ויעילות יותר שמסתגלות באופן טבעי ללומדים בודדים.
ציטוט: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
מילות מפתח: בחינה אדפטיבית ממוחשבת, הערכה חינוכית, למידה עמוקה, למידה בחיזוק, multi-armed bandit