Clear Sky Science · he
אימון קונטרסטיבי שפה‑תמונה מונחה עצמים לזיהוי מטרות ללא־אימון מראש
עיניים חכמות יותר לשמיים וים עמוסים
מערכות מודרניות לאבטחה ולתגובה לאסונות מסתמכות על מצלמות בשמיים ובים כדי לזהות מטוסים, ספינות ועצמים קריטיים אחרים. אך ללמד מחשבים להבחין בין מטוס קרב למטוס נוסעים, או בין ספינת מלחמה לכלי משא, קשה מפתיע כאשר הסצנות עמוסות, הנתונים דלים ודגמים חדשים של ציוד ממשיכים להופיע. המאמר הזה מציג את OG‑CLIP, מערכת בינה מלאכותית חדשה שתוכננה לזהות מטרות צבאיות ואזרחיות עליהן לא היא לא אומנה במפורש, על ידי שילוב ידע נרחב מראש עם מיקוד חזותי חדה יותר על העצמים החשובים.
מדוע הבינה המסורתית לא פוגעת במטרה
מרבית מערכות זיהוי התמונה לומדות מתוך אוספים עצומים של תמונות מתויגות: כל תמונה מקושרת לרשימת קטגוריות קבועה, כמו "חתול" או "מכונית". גישה זו קורסת בתחומים מיוחדים כמו הגנה וחישה מרחוק, שבהם הנתונים רגישים, התיוג דורש מומחים והמגוון גדול מאוד. מודלי ראייה‑שפה חדשים כגון CLIP מצמדים תמונות לתיאורים קצרים מהאינטרנט, מה שמאפשר להם לזהות מושגים חדשים המתוארים במילים. ובכל זאת בתמונות צבאיות הם עדיין מתקשים: התיאורים לעתים עמומים, רקעים כמו עננים וגלים שולטים בפיקסלים, והתכונות הפנימיות שלהם לא גמישות מספיק על מנת לפעול ביעילות בכל דבר ממזל"טים קטנים ועד שרתים רבי‑עוצמה. OG‑CLIP מתמודד עם שלושת הבעיות האלה בצורה ישירה.
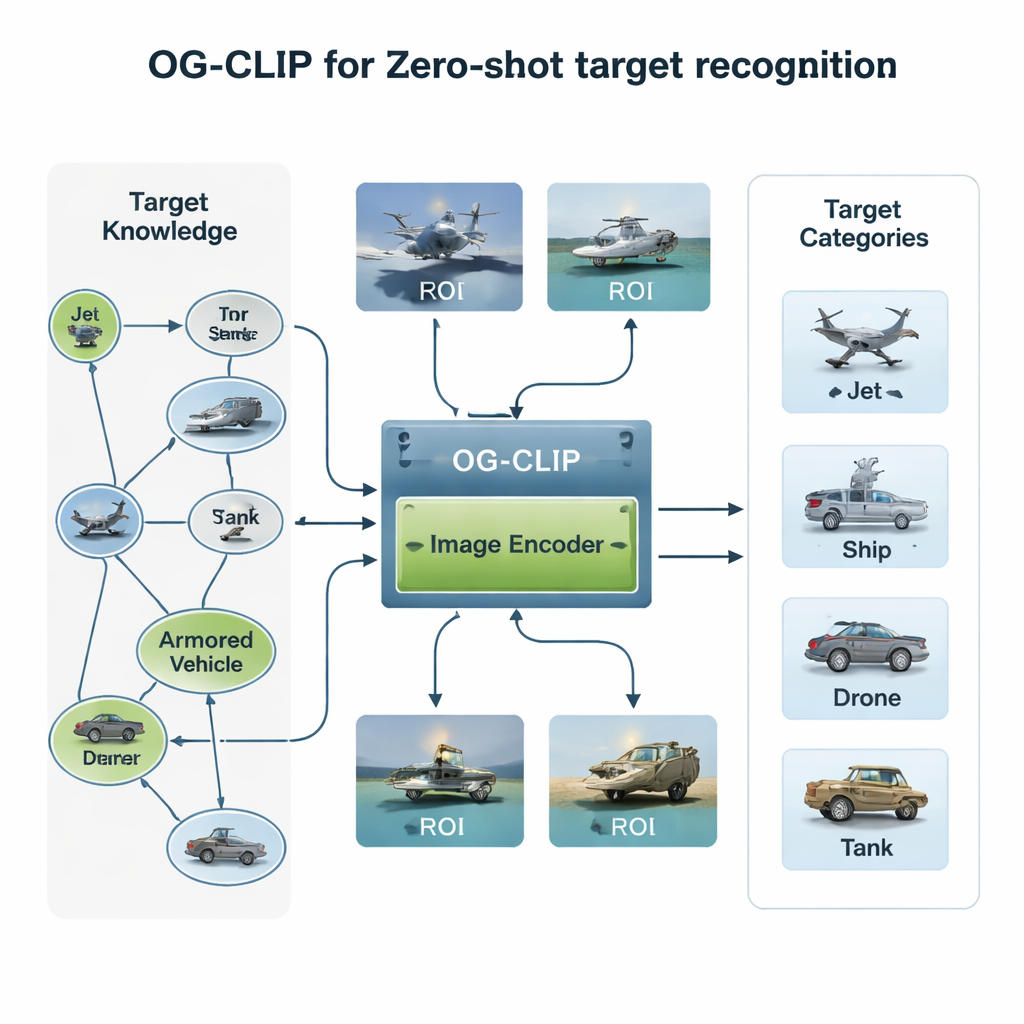
בניית עולTraining עשיר בידע
המרכיב הראשון של OG‑CLIP הוא יקום אימון מהונדס בקפידה. המחברים הרכיבו מאגר של 5,000 סוגי מטרות — החל ממטוסי קרב ובומבררים ועד ספינות מלחמה ומטוסים אזרחיים — וארגנו אותם לגרף ידע מפורט. כל רשומה כוללת עובדות מובנות כגון טווח, משקל ותצורת נשק, שנלקחו ממקורות ציבוריים של דוקטרינת הגנה, אנציקלופדיות ומסמכים טכניים. לאחר מכן אספו כ‑מיליון תמונות באמצעות מאגרי נתונים ציבוריים, חיפוש ברשת, ארכיונים פנימיים ישנים ואפילו סצנות מדומות ממנועי משחק. כדי לשמור על אמינות הנתונים הם ביצעו אשכולות של תמונות באמצעות מודל קיים כדי לזהות חריגים, ערכו סקירה מומחים וסיננו תוויות שגויות. לבסוף השתמשו בכלי שפה‑חזות מתקדמים כדי להמיר את גרף הידע לתיאורים עשירים בשפה טבעית של כל תמונה, כך שהמערכת לומדת לא רק "זה מטוס", אלא "מטוס רחב‑גוף עם כנפוני קצה עולה" או "בומבררת סטילת עם צורת כנף‑עפה".
ללמד את המודל להתעלם מהרעש
חידוש שני טמון במקום בו המודל בוחן. בתמונות לוויין או אוויריות רבות, הספינה או המטוס תופסים רק טלאי קטן, מוקפים שמיים, ים או שטח מסיחי דעת. OG‑CLIP מוסיף מודול אזור־עניין (ROI) שמחקה כיצד אדם מצביע על העצם המרכזי במקום על כל המסגרת. כלי חיתוך מתקדמים סורק באופן אוטומטי את קווי המתאר של עצמים סבירים בתמונה, ויוצר מסכות רכות המדגישות את המטרה ומטשטשות את הרקע. מסכות אלה מוזנות, לצד התמונה המקורית, לגוף הוויזואלי של המודל, כך שתשומת הלב שלו מרוכזת באופן טבעי בתכונות מבחינות כגון צורת כנף, פריסת דק או סילואטית גוף. עיצוב פלאג‑אין זה ניתן להוספה למערכות קיימות ללא כתיבה מחדש של הארכיטקטורה הבסיסית, ומעניק להן מבט יותר "מונחה עצם".

התאמת פירוט לחומרה
החלק השלישי עוסק בדאגה מעשית אך קריטית: לא כל המכשירים יכולים להרשות לעצמם את אותו רמת פירוט. תחנת קרקע לוויינית עשויה לעבד תכונות עשירות וממדיות גבוהות, בעוד מזל"ט קטן זקוק לחישובים מהירים וקלילים יותר. שיטות מסורתיות מקבעות גודל תכונה יחיד או מאמנות כמה מודלים נפרדים לבגדלים שונים. OG‑CLIP במקום זאת משתמש בייצוג בסגנון "Matryoshka", האבקת מידע ברמות פירוט מרובות לתוך וקטור אחד, כמו בובות קונכייה מקוננות. המערכת יכולה לחתוך חלקים קצרים או ארוכים יותר מהוקטור הזה — תיאורים גסים או עדינים יותר של מה שבתמונה — ללא אימון חוזר. מנגנון המשקלות מעודד כל רמה לשמור את המידע השימושי ביותר לסיווג, ותוספת מונח הפסד דוחפת את הרמות להישאר עקביות סמנטית זו עם זו.
כמה טוב זה עובד בפועל?
כדי לבחון את OG‑CLIP, החוקרים בנו סט הערכה מאתגר של 99 קטגוריות מטרה, הכולל 51 סוגי מטוסי קרב, 29 סוגי ספינות מלחמה ו‑19 מטרות אזרחיות או מעורבות. חשוב: אף אחת מהקטגוריות האלה אינה מופיעה בנתוני האימון, כך שהמערכת חייבת להסתמך על ההבנה שנרכשה של שפה ודפוסי חזות — מבחן "ללא‑אימון". בהשוואה למספר בסיסים חזקים מבוססי CLIP, OG‑CLIP שיפר את הדיוק הממוצע ביותר מ‑11 נקודות אחוז, והגיע ל‑84.28 אחוז בסך הכל. הוא הצטיין במיוחד בסצנות צפופות ומורכבות ובבדיקות דקויות בין דגמים דומים, כגון מטוסי קרב שונים, שם מודול ה‑ROI והתיאורים העשירים בידע העניקו לו יתרון ברור. מחקרי אבולוציה הראו שכל רכיב — נתוני גרף הידע, המיקוד ב‑ROI והייצוגים האדפטיביים — תרם שיפורים מדידים.
מה המשמעות של זה למעקב בעולם האמיתי
לא‑מומחים, המסקנה העיקרית היא ש‑OG‑CLIP מהווה צעד לקראת מערכות אבטחה ומעקב שיכולות לזהות באופן אמין יותר מטוסים וספינות לא מוכרים מתמונות מהעולם האמיתי, גם כשדוגמאות מתויגות נדירות. על‑ידי שילוב ידע מומחה מובנה, מיקוד אוטומטי על העצם הרלוונטי ורמות פירוט מתכווננות, הגישה עושה את הבינה הראייתית‑שפתית גם חכמה יותר וגם פרקטית יותר. מעבר להגנה, רעיונות דומים עשויים לסייע לניטור סביבתי, תגובה לאסונות ומערכות בדיקה תעשייתיות להבין סצנות מורכבות בזמן ריצה על מגוון רחב של חומרה.
ציטוט: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
מילות מפתח: זיהוי ללא‑אימון מראש, מודלי ראייה‑שפה, גילוי עצמים, חישה מרחוק, גרפי ידע