Clear Sky Science · he
טרנספורמרים בלמידה עמוקה המבוססת על תפיסה חזותית למיון ציורים ותמונות דרך извיקת תכונות
מדוע זה חשוב לתמונות יומיומיות
בעידן שבו כל אחד יכול ליצור תמונה מציאותית בכמה לחיצות, נהיה קשה יותר להבחין אם תמונה היא צילום אמיתי, ציור מסורתי או משהו שנוצר כולו באמצעות אלגוריתמים. במחקר זה נבדק כיצד בינה מלאכותית מודרנית יכולה בהיבט אוטומטי להבחין בין ציורים בעבודת יד לבין צילומים שנלקחו במצלמה, ואף לתמונות שנוצרו על ידי AI, ובכך לסייע בהגנה על שווקי אמנות, ארכיונים ומשתמשים מקוונים מפני בלבול וזיוף.
אמנות, צילומים ועליית התמונות שנוצרו על ידי מכונות
ציורים וצילומים עשויים להיראות דומים במבט ראשון על מסך, אך הם נושאים טביעות אצבע חזותיות שונות מאוד. ציורים נוטים להציג מכחולים גלויים, צבעים מעוצבים והרכבים יותר מופשטים, בעוד שצילומים בדרך כלל מכילים פרטים חדים יותר ותאורה טבעית. באותו זמן, גנרטורים חדשים מייצרים יצירות שמחקות את שני המדיה עם מיומנות גוברת. מוזיאונים, גלריות, אספנים ופלטפורמות דיגיטליות זקוקים יותר ויותר לכלים שיכולים במהירות ובמהימנות לזהות עם איזו סוג תמונה הם מתמודדים — הן לאימות יצירות והן לניהול הצפה של תוכן סינתטי.
צנרת חדשה ללימוד מכונות לראות
החוקרים בנו צנרת ניתוח תמונה מלאה המבוססת על Vision Transformer, מודל למידה עמוקה עדכני שפותח במקור לעיבוד שפה וכעת הותאם לתמונות. הם אימנו את המערכת על מאגר ציבורי של Kaggle המכיל 1,361 ציורים ו-3,747 צילומים, המייצגים מגוון רחב של סצנות וסגנונות. כל תמונה עוברת ראשית סטנדרטיזציה: שינוי גודל, קיצוץ קל, ולאחר מכן העשרה באמצעות החלפות, סיבובים קטנים, שינויים בהירות והסרת רעשים כדי שהמודל יחווה וריאציות ריאליסטיות רבות. לאחר הכנה זו, ה-Vision Transformer מחלק כל תמונה לפאצ'ים קטנים ולומד כיצד חלקים שונים בתמונה מתקשרים זה עם זה על פני כל המסגרת. 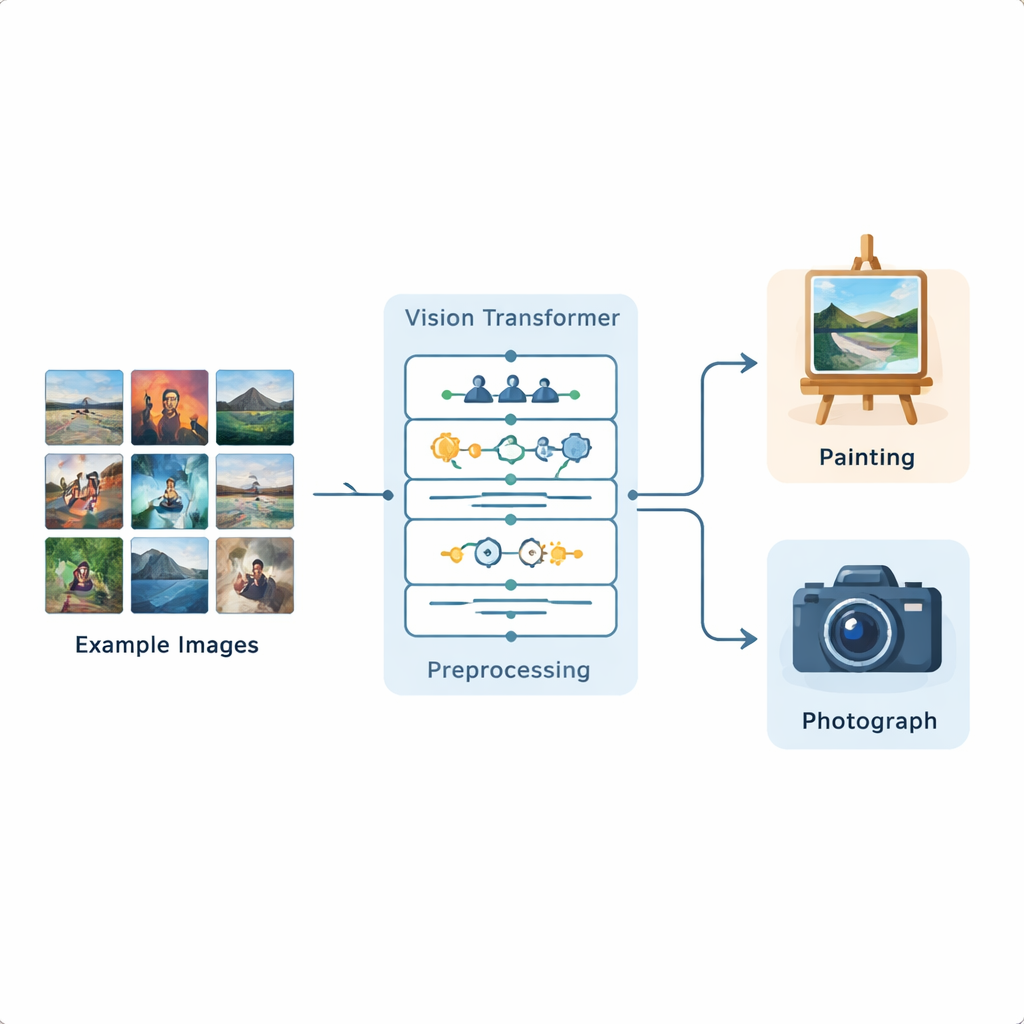
איך המודל מתמקד בפרטים הנכונים
שלא כמו רשתות עצביות מוקדמות שהתמקדו בעיקר בתבניות מקומיות, ה-Vision Transformer משתמש במנגנון "תשומת לב" כדי להחליט אילו חלקים בתמונה חשובים ביותר למשימה הנתונה. המנגנון שואל בפועל, עבור כל פאצ' עד כמה יש לשים לב לכל פאצ' אחר. זה מאפשר לו להבחין במבנה גלובלי טוב יותר: הדרך שבה צבעים זורמים על הקנבס, כיצד האור נופל על סצנה, או כיצד טקסטורות חוזרות על עצמן. כדי לוודא שהמודל לא מהמר באופן אקראי, המחברים גם מיישמים שיטת ויזואליזציה בשם Grad-CAM, שמחדדת את האזורים הספציפיים שהשפיעו על כל החלטה. עבור ציורים, ההדגשות הללו נוטות להופיע על מרקמי מכחול ואזורים מעוצבים; עבור צילומים, הן מצטברות סביב קצוות דקים, משטחים ריאליסטיים ומעברי תאורה. 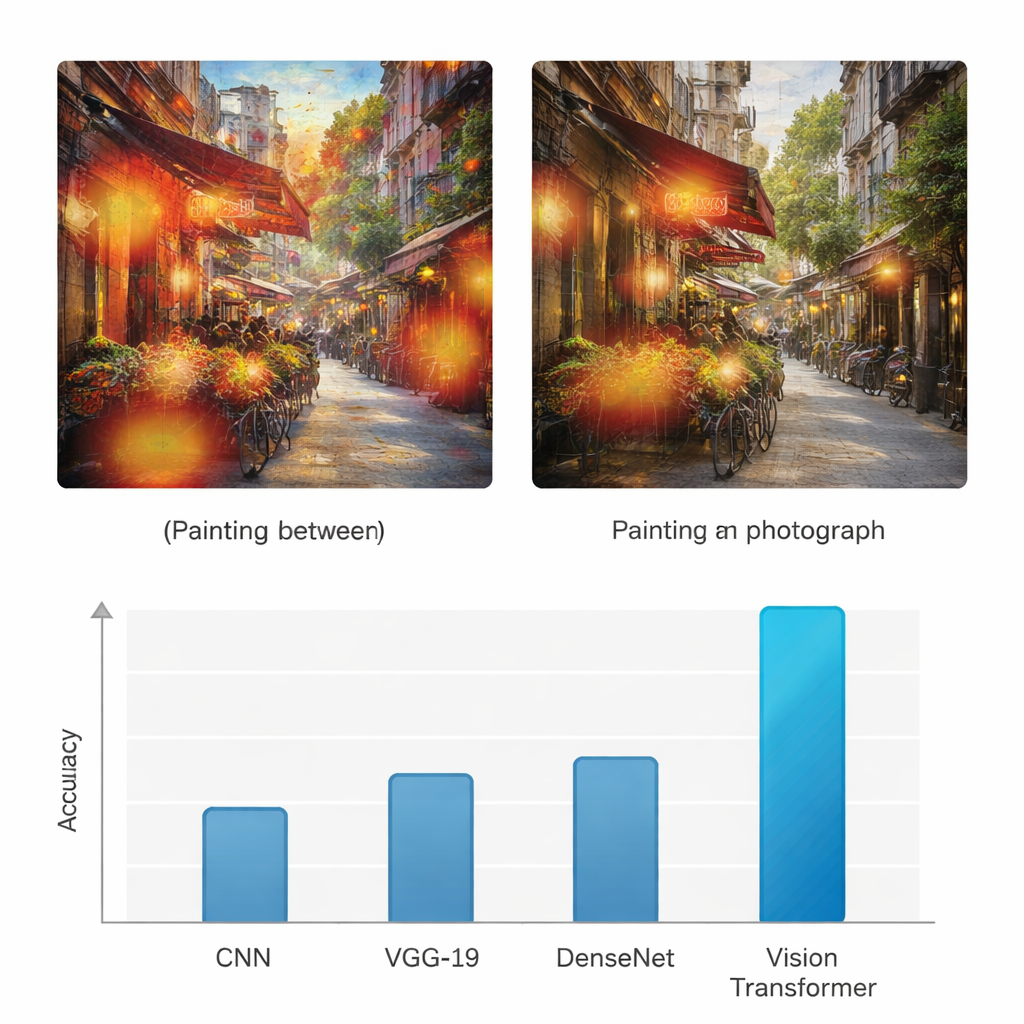
מתעלה על שיטות זיהוי תמונה קודמות
כדי לבחון האם גישה זו אכן מוסיפה ערך, המחקר משווה את ה-Vision Transformer עם שלוש ארכיטקטורות למידה עמוקה נפוצות: רשת עצבית קונוולוציונית סטנדרטית (CNN), רשת VGG-19 ו-DenseNet. כל המודלים מאומנים ונבחנים על אותו סט נתונים, ומוערכים בעזרת מדדים מקובלים כגון דיוק, דיוק חיובי (precision), שליפה (recall) ו-F1-score, שמאזנים בין זיהויים נכונים לטעויות עבור שתי הקטגוריות. בעוד שרשתות הבסיס מגיעות לדיוקים בטווח של אמצע ה-70 עד אמצע ה-80 אחוזים, ה-Vision Transformer משיג דיוק של 95% הן לציורים והן לצילומים, עם דיוק ושליפה גבוהים באופן דומה. המחברים גם מבצעים מספר בדיקות סטטיסטיות כדי לאשר ששיפור זה אינו בגדר מקריות, ומראים שהמודל המבוסס טרנספורמר טוב באופן מהימן על פני ניסויים חוזרים וקריטריונים שונים להערכה.
מה המשמעות של זה עבור אמנות, אמון וטכנולוגיה
הממצאים מרמזים שמודלים מודרניים מבוססי טרנספורמר יכולים לשמש ככלים חזקים ומסבירים להפרדה בין ציורים לצילומים ולזיהוי תמונות שנוצרו על ידי AI המחקות כל אחד מהמדיה. עבור לא-מומחים, המסקנה היא שמחשבים מסוגלים כעת לזהות רמזים עדינים — כגון עבודת מכחול, חלקות או גרדיאנטים תאורה — שאפילו צופים אנושיים זהירים עלולים לפספס, ובקנה מידה גדול. מערכות כאלו יכולות לסייע לגלריות ואספנים לאמת יצירות, לסייע לעורכים וארכיונאים בארגון אוספים דיגיטליים עצומים, ולתמוך בפלטפורמות מקוונות בסימון או סינון של תוכן סינתטי. ככל שמחוללי התמונות ממשיכים לטשטש את הקו בין מציאות לבין המצאה, שיטות כמו זו המוצגת כאן מציעות דרך מעשית לשמור על אמון במה שאנו רואים.
ציטוט: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
מילות מפתח: תמונות שנוצרו על ידי בינה מלאכותית, אימות אמנות, מיון תמונות, Vision Transformer, ניתוח אמנות דיגיטלית