Clear Sky Science · he
IASUNet: חילוץ מבנים מבוסס על Swin-UperNet עם תשומת לב משופרת
למה חשוב לזהות כל מבנה מהחלל
כשהערים מתרחבות והאקלים משתנה, ידיעה מדויקת היכן נמצאים מבנים — ואיך הם משתנים עם הזמן — הופכת לקריטית. מתכנון שכונות בטוחות יותר ומעקב אחרי בנייה בלתי חוקית ועד לניהול תגובה לאסונות אחרי שיטפונות או רעידות אדמה, מפות מבנים מפורטות הן היום מרכיב מרכזי של ערים חכמות ועמידות. מאמר זה מציג את IASUNet, מערכת בינה מלאכותית חדשה הלומדת לזהות מבנים באופן אוטומטי מתמונות לוויין ברזולוציה גבוהה בדיוק מרשים, גם בסצנות אמיתיות צפופות ומלאות רעש.
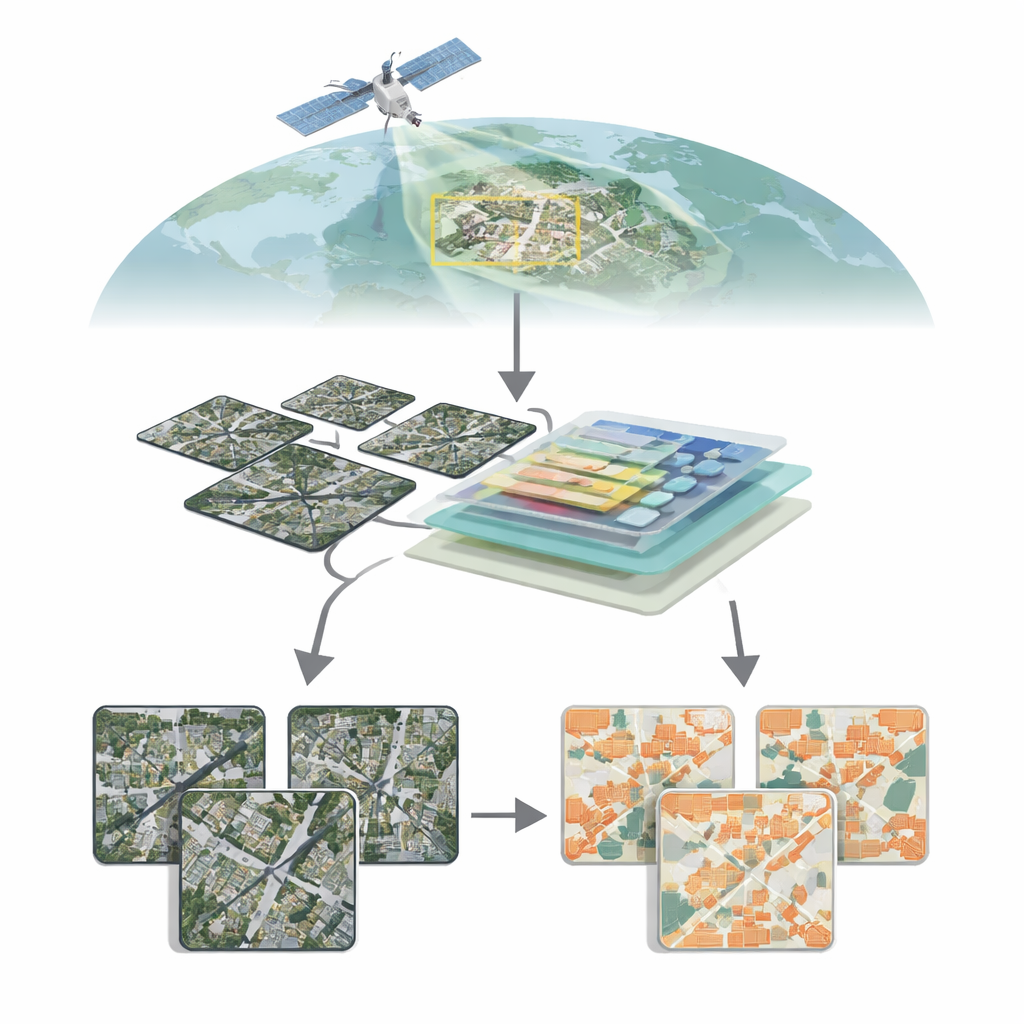
להסתכל על הערים מלמעלה
לווייני דור חדש מצלמים את פני כדור הארץ בפרטי פרטים, חושפים גגות בודדים, דרכים ואפילו סמטאות צרות. להפוך ים פיקסלים זה למפות מבנים נקיות, עם זאת, רחוק מלהיות טריוויאלי. מבנים משתנים באופן קיצוני בגודל, צורה, צבע וסביבה: גורדי שחקים מזכוכית במרכזי ערים, בתים נמוכים בפרברים, מבני חווה מפוזרים בכפרים. באזורים כפריים או מעורבים, מבנים עשויים לתפוס רק חלק קטן מהתמונה, בעוד צמחייה, אדמה ומים שולטים. שיטות ראייה ממוחשבת מסורתיות, המבוססות בעיקר על רשתות קונבולוציה, מתקשות לעתים לתפוס את התמונה הגדולה על פני כל הסצנה ועדיין לשמר גבולות חדים, מה שמוביל להחמצת מבנים קטנים או לקווים מטושטשים.
תשומת לב חכמה יותר לפרטים
IASUNet מתמודד עם האתגרים הללו על ידי שילוב שתי רעיונות עוצמתיים: מקודד מבוסס Transformer בשם Swin Transformer, ודקודר גמיש הידוע כ-UperNet. ה-Swin Transformer מחלק תמונה להרבה טלאים קטנים ולומד כיצד הם קשורים זה לזה על פני כל הסצנה, במקום להסתכל רק במסגרת חלון בגודל קבוע. זה עוזר למודל להבין הקשרים רחבים — למשל האם מלבן מואר נמצא בתוך בלוק עירוני צפוף או בשדה מבודד — ובו בזמן לשמר פרטים. בנוסף משולב מנגנון תשומת לב בשם Convolutional Block Attention Module (CBAM) בכמה שלבים. CBAM לומד, ערוץ אחר ערוץ ואזור אחר אזור, אילו מאפייני תמונה נוטים להיות שייכים למבנים ואילו מהווים רעש ברקע, מחזק את הראשונים ומדכא את האחרונים לפני שהדקודר מרכיב חזרה את המפה המלאה של המבנים.
לאזן את הסיכויים כשהמבנים נדירים
מחסום מעשי נוסף הוא חוסר איזון: בהרבה סצנות לוויין רוב הפיקסלים מציגים דרכים, שדות, עצים או מים, בעוד המבנים תופסים רק איים קטנים. שיטות אימון סטנדרטיות נוטות להעדיף את מה שמופיע בתדירות הגבוהה ביותר, מה שמסכן ללמד את המודל להתייחס למבנים הפחות שכיחים כתוספת שולית. כדי להתגבר על כך, המחברים מתאימים פונקציית הפסד בשם Focal Cross‑Entropy. אסטרטגיה זו מקטינה את השפעת פיקסלי הרקע "הקלים" ומגבירה את המשקל של פיקסלי המבנה שקשה לסווג במהלך האימון. כתוצאה מכך המודל מעניק תשומת לב מוגברת למבנים קטנים, חלשים או יוצאי דופן שאחרת עלולים להישמט, ומשפר את ה-recall מבלי להציף את המפה באזעקות שווא.
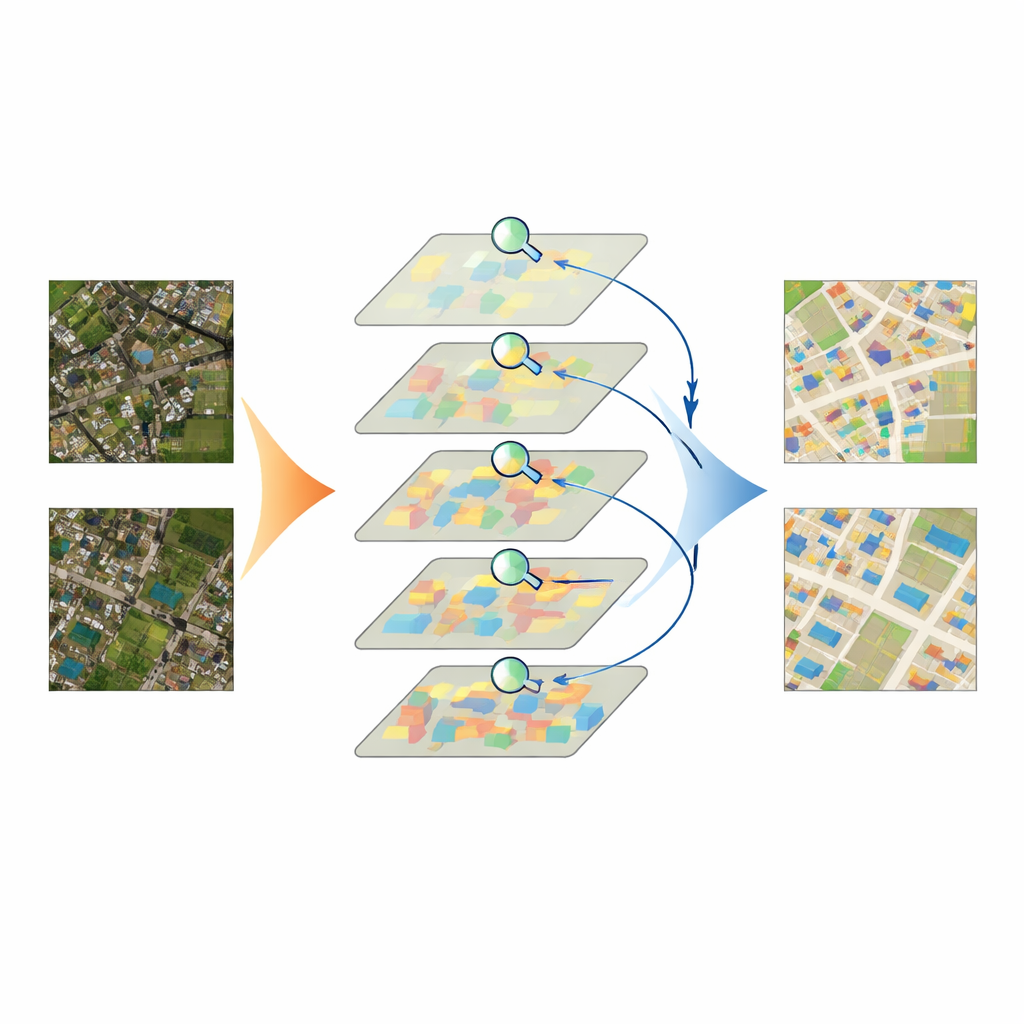
לבחון את המודל במבחן
הצוות בחן את IASUNet על שלוש מערכי נתונים מוכרים לחילוץ מבנים מגרמניה, ניו זילנד וארצות הברית, וכן על אוסף מתואם בקפידה של תמונות לוויין מסין שהכינו ובדקו בעצמם. על פני קריטריונים אלו, IASUNet התאמה באופן עקבי או עלה על גישות מובילות, כולל רשתות קונבולוציה חזקות ומודלים אחרים מבוססי Transformer. במערך הנתונים המפורט מאוד של Potsdam, הוא הגיע לחפיפה כמעט מושלמת בין אזורי המבנה החזויים לאמת, ובו זמנית רץ במהירויות מעשיות על חומרת גרפיקה מודרנית. גם בנופים בלתי סדירים יותר, שבהם מבנים מפוזרים, מוסתרים חלקית או צפופים מאוד, IASUNet שרטט קווים נקיים יותר, זיהה יותר מטרות קטנות והימנע מהרבה מהשמטות ושגיאות גבול שנראו בשיטות מתחרות.
מפיקסלים לערים טובות יותר
במונחים יום־יומיים, המחקר מראה שאנו יכולים כעת ללמד מחשבים לקרוא נופי עיר מהחלל בבהירות חסרת תקדים. על ידי כיוונון מדויק של "התשומת לב" של המודל לחלקים הנכונים בתמונה ומשקלול מכוון של פיקסלי מבנים נדירים אך קריטיים, IASUNet הופך תמונות לוויין גולמיות למפות מבנים מדויקות ומעודכנות בעלות עלות חישובית מתונה נוספת. מפות כאלה יכולות לתמוך בתכנון עירוני, מחקרי אנרגיה ואי חום עירוני, רגולציה של שימושי קרקע והערכת נזקים מהירה לאחר אסונות. למרות שהעבודה טכנית במהותה, מסקנתה פשוטה: בינה מלאכותית חכמה יותר יכולה להעניק למקבלי החלטות תמונה חדה ואמינה יותר של המרחב הבנוי, ולסייע לערים לגדול באופן בטוח וברת‑קיימא.
ציטוט: Zhang, H., Ma, Y., Wang, G. et al. IASUNet: building extraction based on impoved attention Swin-UperNet. Sci Rep 16, 7969 (2026). https://doi.org/10.1038/s41598-026-36270-2
מילות מפתח: חישה מרחוק, חילוץ מבנים, סגמנטציה סמנטית, רשתות טרנספורמר, מיפוי עירוני