Clear Sky Science · he
HEViTPose: לקראת הערכת תנוחת גוף דו־ממדית מדויקת ויעילה עם מנגנון קשב מצטבר של הפחתה מרחבית בקבוצות
ללמד מחשבים לקרוא שפת גוף
מאפליקציות כושר ועד מערכות סיוע לנהג, טכנולוגיות רבות כיום תלויות ביכולת של מחשב להבין כיצד אנשים נעים. מיומנות זו, שנקראת הערכת תנוחת אדם, משמעה מציאת מיקומי מפרקים — כמו כתפיים, ברכיים וקרסוליים — בתמונה או בוידאו. האתגר הוא לעשות זאת גם בדיוק גבוה וגם במהירות מספקת לשימוש בזמן אמת על חומרה יום־יומית. המאמר מציג את HEViTPose, שיטה חדשה שמטרתה לשמור על דיוק גבוה תוך שימוש בפחות כוח חישובי מאשר מערכות רבות קיימות.
מדוע זיהוי מפרקים בתמונות כל כך קשה
מבט ראשון עלול להראות שמיקום מפרקים פשוט: רק לחפש זרועות ורגליים. בפועל, אנשים מופיעים בגדלים שונים, בתנוחות יוצאות דופן, בסצנות צפופות ולעתים מאחורי חפצים כמו רהיטים או מכוניות. מערכות מודרניות להערכת תנוחה בדרך כלל מטפלות בכך על ידי יצירת "מפת חום" מפורטת לכל מפרק, שבה כתמים מוארים מסמנים מיקומים אפשריים. מפות חום מדויקות מאוד אך יקרות לחישוב. מערכות מסורתיות נשענות בעיקר על רשתות נוירונים קונבולוציוניות, הטובות בזיהוי דפוסים מקומיים אך נדרשות לעומק ולמשקל גדולים כדי ללכוד קשרים בטווח ארוך בכל הגוף. דגמים מבוססי טרנספורמר עדכניים מצטיינים בלכידת קשרים אלה, אך לעתים הם זקוקים לסט נתונים גדול ולחישוב כבד, מה שמקשה על שימוש בזמן אמת או במכשירים קטנים.
מבטים חופפים לראייה חלקה יותר
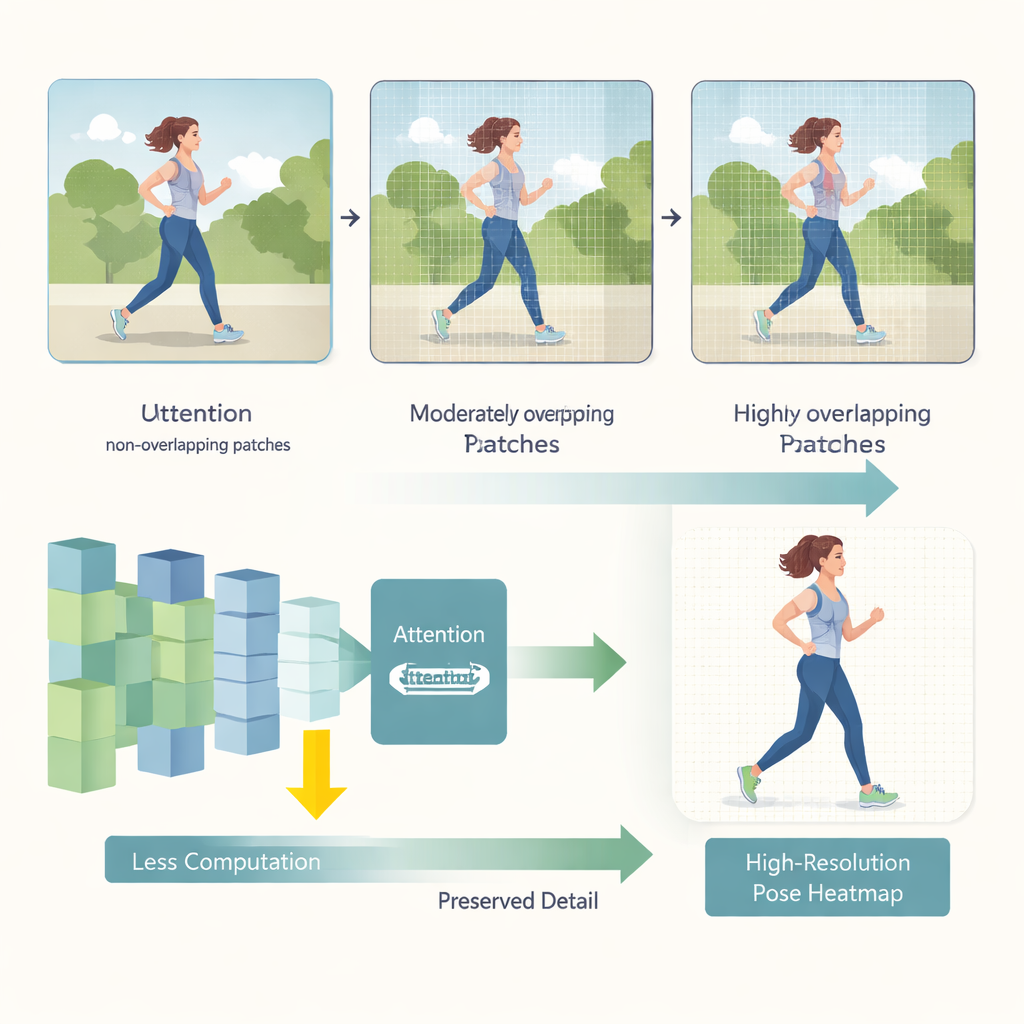
HEViTPose מתחילה מחדש במחשבה על אופן חלוקת התמונה לחלקים לצורך ניתוח. דגמי טרנספורמר מוקדמים לעתים קרובות חותכים את התמונה לריבועים לא חופפים, מה שעלול לשבור את הרצף הוויזואלי בין אזורים שכנים — כמו חיתוך זרוע בקצה חתיכה. HEViTPose בונה על רעיון של הטמעת טלאים חופפים ומציגה מדד ברור וניתן לכוונון בשם רוחב חפיפה בהטמעת טלאים (Patch Embedding Overlap Width, PEOW). PEOW סופר בפשטות כמה פיקסלים טלאים שכנים משתפים לאורך הגבול ביניהם. על ידי שינוי שיטתי של החפיפה הזו, המחברים מראים כי חפיפה מתונה מאפשרת לרשת "להרגיש" טוב יותר את השינוי החלק בצבע ובצורה מטלא לתלא. רצף מקומי עשיר יותר זה מוביל למיקומי מפרקים מדויקים יותר, מבלי להגדיל משמעותית את גודל המודל או את ההטלה החישובית.
קשב חכם יותר בעבודה פחותה
החידוש המשני המרכזי הוא מודול קשב חדש שנקרא קשב מרובה־ראשי מצטבר עם הפחתה מרחבית בקבוצות (Cascaded Group Spatial Reduction Multi-Head Attention, CGSR-MHA). מנגנוני קשב אומרים לרשת אילו חלקים בתמונה צריכים להשפיע על כל תחזית, אך הם נוטים לגדול בצורה לקויה ככל שהתמונות גדלות. CGSR-MHA מתמודד עם זה בשלוש דרכים. ראשית, הוא מחלק את התכונות לקבוצות, כך שכל קבוצה מטפלת רק בחלק מהמידע במקום בכל דבר בבת אחת. שנית, הוא מצמצם את הרזולוציה המרחבית בתוך כל קבוצה לפני חישוב הקשב, ובכך מקטין משמעותית את כמות הפעולות. שלישית, הוא משתמש בכמה ראשים קטנים של קשב במקום בכמה ראשים גדולים, וכך שומר על גיוון במה שהמודל יכול "לתשומת לב" אליו תוך כדי שמירה על עלות נמוכה. בחירות קפדניות לגבי כמה קבוצות להשתמש, כמה לצמצם וכמה ראשים לכלול מאזנות בין מהירות לדיוק.
מודלים קלים שעדיין מתחרים בחזית
כדי לבחון את HEViTPose, המחברים מעריכים אותה על שני תקנים מקובלים: מאגר ה‑MPII של פעילויות יומיומיות ושל סט הנתונים הגדול יותר COCO עם אנשים בסצנות מגוונות. במספר גדלים של מודלים, HEViTPose משווה או כמעט משווה את הדיוק של מערכות הערכת תנוחה מובילות תוך שימוש בהרבה פחות פרמטרים ובכמות חישוב נמוכה יותר. לדוגמה, גרסה אחת מגיעה לדיוק דומה לרשת ברזולוציה גבוהה פופולרית (HRNet) תוך קיצוץ מספר הפרמטרים הנלמדים ביותר מ‑60% והפחתת כמות החישוב בלמעלה מ‑40%. בהשוואה למודל היברידי מודרני אחר ששילב קונבולוציות וטרנספורמרים, HEViTPose מספקת ביצועים דומים אך רצה בקירוב 2.6 פעמים מהר יותר על מעבד גרפי. החסכונות הללו מתרגמים ישירות לביצוע חלק יותר בזמן אמת ולדרישות חומרה נמוכות יותר.
מה זה אומר עבור יישומים יומיומיים
במילים פשוטות, HEViTPose מראה שאינו חובה לבחור בין דיוק ליעילות כשמלמדים מחשבים לקרוא שפת גוף אנושית. על ידי חפיפה זהירה של חלקי התמונה שהיא בוחנת, ועל ידי עיצוב מחדש של אופן חישוב הקשב בתוך הרשת, המערכת יכולה לאתר מפרקים בדיוק גבוה תוך שהיא נשארת קומפקטית ומהירה. זה הופך אותה לאטרקטיבית לשימושים בעולם האמיתי כמו מעקב ספורט, מעקב וידאו, אינטראקציה בין אדם לרובוט וניטור בתוך רכב, שבהם גם מהירות וגם צריכת חשמל משמעותיים. הרעיונות שמאחורי HEViTPose — חפיפה חכמה וקשב יעיל — יכולים גם להיות מותאמים למשימות קשורות כמו מעקב תנוחות של בעלי חיים או זיהוי נקודות ציון בפנים, ובכך להביא "עיניים דיגיטליות" חדות יותר למכשירים רבים מבלי לדרוש חומרת-על.
ציטוט: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
מילות מפתח: הערכת תנוחת אדם, ראייה ממוחשבת, טרנספורמר חזותי, למידה עמוקה יעילה, מנגנון קשב