Clear Sky Science · he
מסגרת כללית להצמצום אדפטיבי לא-פרמטרי של מימדים
מדוע חשוב לכווץ נתוני ענק
החיים המודרניים נשענים על נתונים: סריקות רפואיות, היסטוריית קניות באינטרנט, תמונות, עדכוני חדשות ועוד. לכל רשומה יכולים להיות מאות או אלפי מדידות, מה שמקשה על אחסון, ניתוח ואפילו ויזואליזציה. מדענים משתמשים ב"הפחתת מימדים" כדי לדחוס את המורכבות הזו לתמונות ולמודלים פשוטים יותר תוך שמירה על הדפוסים החשובים. אבל הכלים הפופולריים כיום לעתים קרובות דורשים בחירות ידניות רבות וניסיונות וחטאים. מאמר זה מציג דרך לאפשר לנתונים עצמם להחליט כיצד כדאי לכווץ, במטרה לקבל תמונות ברורות יותר, למידה מדויקת יותר ופחות השערות מצד המשתמש.
מפשוט קווים למציאויות מעוקלות
כלי קלאסי לפישוט נתונים, ניתוח רכיבים עיקריים (PCA), פועל כמו להאיר אובייקט ולבדוק את צלו: הוא מוצא כיוונים שטוחים הטובים ביותר שמסבירים את מרבית השונות. זה עוצמתי כאשר מבנה הנתונים הוא בערך ישר או שטוח. אולם נתונים אמיתיים — כמו תמונות, טקסטים או קריאות חיישנים — לעתים קרובות שוכבים על משטחים מעוקלים מוסתרים במרחב ממדי גבוה. בעשרים השנים האחרונות פותחו שיטות "לא-ליניאריות" כגון Isomap, Locally Linear Embedding (LLE), spectral embedding ו‑UMAP במיוחד כדי לחשוף צורות מתפתלות אלו. הן נסמכות על שכונות מקומיות: עבור כל נקודה הן בודקות את השכנים הקרובים ומנסות לשמר את היחסים הקטנים הללו בציור מימד נמוך. עם זאת, שיטות אלו מחייבות את המשתמש לבחור שתי מתזים מרכזיות: כמה שכנים להשתמש וכמה מימדים לבצע עליהם פרויקט. בחירה לקויה עלולה להוביל לתוצאות מטעות או לעלויות חישוב גבוהות.
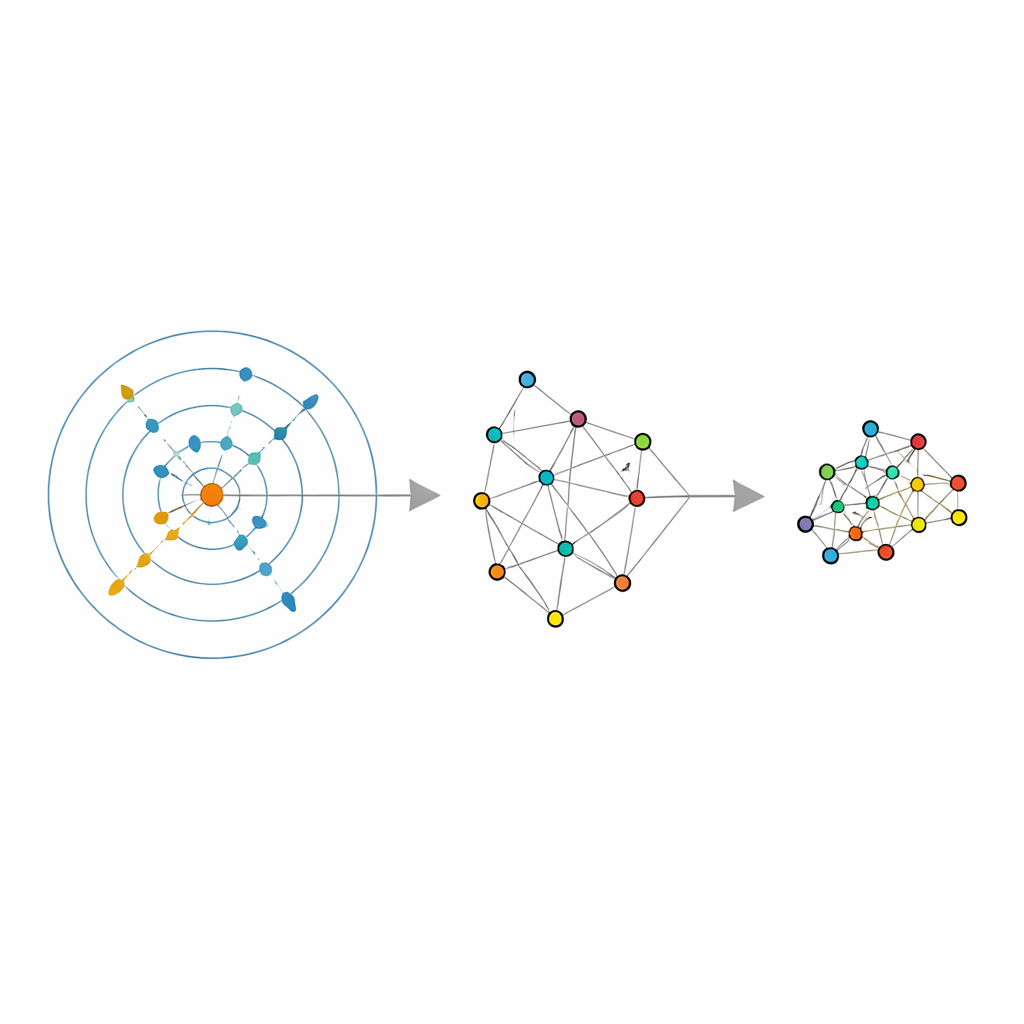
מאפשרים לנתונים לבחור את השכונה שלהם
המחברים בונים על כלי סטטיסטי עדכני שנקרא אומדן ממד פנימי, שמנסה לענות על שאלה פשוטה: בכמה כיוונים בלתי-תלויים הנתונים משתנים באמת, לאחר שהרעש מוסר? האומדן שלהם, שנקרא ABIDE, הולך צעד נוסף. סביב כל נקודה הוא מחפש באופן אוטומטי שכונה שנראית אחידה באופן סביר — לא קטנה מדי ורועשת ולא גדולה מדי ומשוחדת. בכך הוא מחזיר שתי חתיכות מידע: אומדן גלובלי של הממד האמיתי של הנתונים וגודל שכונה מותאם לכל נקודה. זה הופך את "מספר השכנים" הקבוע לכמות אדפטיבית מקומית שיכולה לגדול באזורים דלילים ולהצטמצם באזורים צפופים, בהתאם לצפיפות האמיתית של הנתונים.
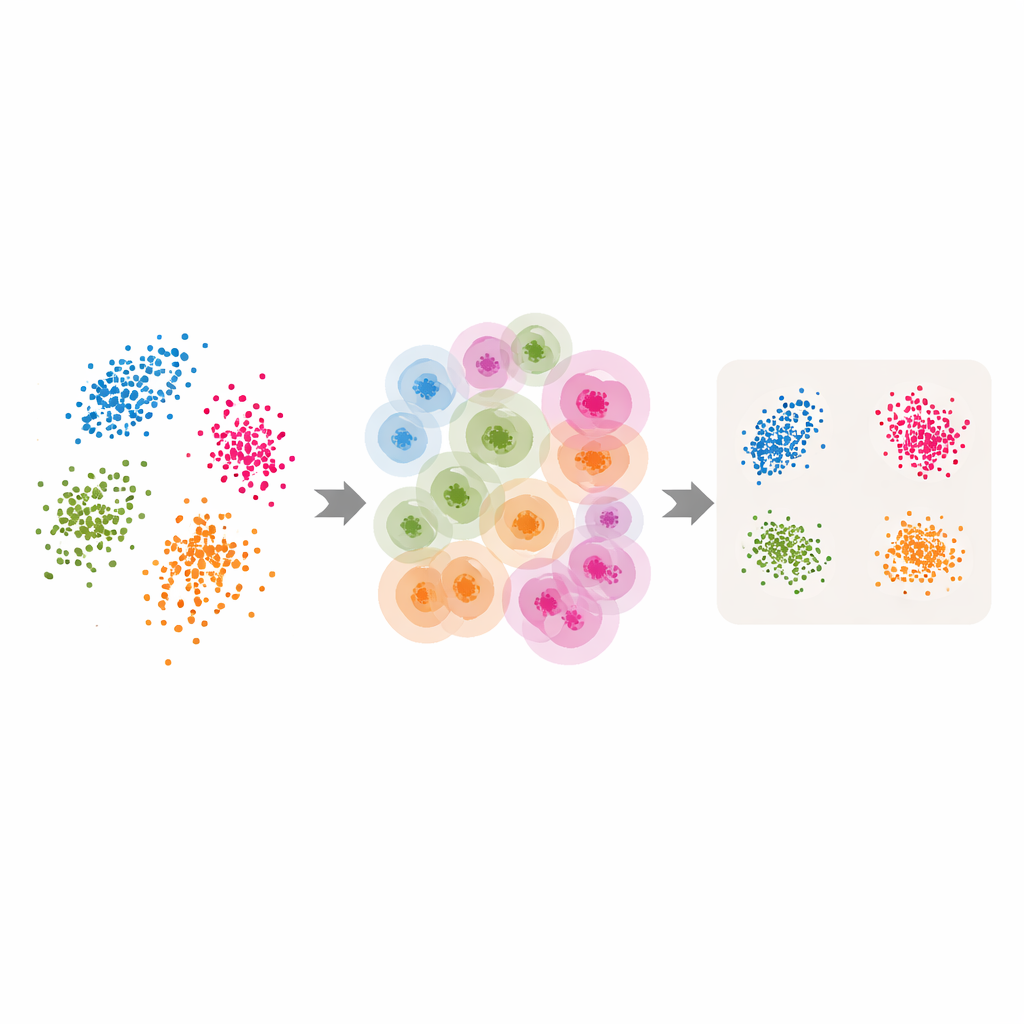
הפיכת כלים קלאסיים לאדפטיביים
מצויידים בשכונות אדפטיביות ובאומדן הממד הפנימי, המחברים משדרגים מספר שיטות פופולריות להפחתת מימדים ולאשכולות. ב‑LLE הם מחליפים את מספר השכנים האחיד שנבחר על ידי המשתמש בערכים הממוקדים לכל נקודה שמחזיר ABIDE, ומגדירים את הממד המטרה כשווה לאומדן הממד הפנימי. האלגוריתם לומד אז כיצד לשחזר כל נקודה מקבוצה מקומית שנבחרה בקפידה לפני שמוצא סידור גלובלי ממדי-נמוך ששומר הכי טוב על השחזורים המקומיים הללו. רעיונות דומים מיושמים ב‑spectral clustering — שבה משתמשים בגרף של דמיון בין נקודות לצורך קיבוץ — וב‑UMAP, שבונה מפה מטוששת של אופן החיבור בין נקודות. בכל מקרה, גודל השכונה הנוקשה מוחלף במבנה גמיש מונחה נתונים העוקב אחרי הגיאומטריה הטבעית של הנתונים.
בדיקות על פרחים, ספרות, טקסט וצורות סינתטיות
כדי לבדוק האם הגישה האדפטיבית משתלמת, המחברים מריצים ניסויים על מספר רכיבי מבחן: המדידות הקלאסיות של פרחי איריס, תמונות ספרות כתובות יד (MNIST), מאמרי חדשות המיוצגים על ידי הטמעות מודל-שפה, וצורות סינתטיות תלת-ממדיות עם רעש נוסף. הם משווים את הגרסאות האדפטיביות להגדרות תוכנה סטנדרטיות ולרשתות כיוונון מוקפדות של היפר‑פרמטרים. במשימות לא‑מנחות כגון אשכולות ויזואליזציה, השיטות האדפטיביות בדרך כלל מניבות אשכולות ברורים יותר, קיבוצים צפופים יותר וציונים טובים יותר במדדי איכות סטנדרטיים. למשל, על רב-ממדים מורכבים עם צפיפות נקודות לא אחידה, השיטות האדפטיביות משחזרות את המבנה האמיתי הרבה יותר טוב מאשר גרסאות עם שכנים קבועים. במבחנים מונחים, שבהם הנתונים המופחתים מוזנים לממיין, הגישה האדפטיבית שוב תואמת או עולה על בחירות ההגדרות הקבועות הטובות ביותר, ללא כיוונון אינטנסיבי.
מה זה אומר לניתוח נתונים יומיומי
עבור לא־מומחים ומבצעים כאחד, המסר המרכזי הוא כי כיווץ נתונים אינו חייב להסתמך על גישוש. על ידי שימוש בגיאומטריה של הנתונים כדי להחליט "כמה שכנים" ו"כמה מימדים", המסגרת הזו הופכת כלים שכיחים כגון LLE, spectral clustering ו‑UMAP לגרסאות חכמות ועמידות יותר של עצמם. התוצאה היא תצוגות ממד-נמוך אמינות יותר — תרשימים ותכונות המשקפים טוב יותר את צורת הנתונים האמיתית — תוך קיצור הזמן שמושקע בחיפוש ידני אחר היפר‑פרמטרים. במונחים מעשיים, זה אומר שפעולות כמו ויזואליזציה של אוספי תמונות גדולים, קיבוץ מסמכים או הכנת קלטים למודלים חיזויים יכולות להפוך לקלות ואמינות יותר, פשוט על ידי כך שמאפשרים לנתונים להנחות באופן אדפטיבי את אופן דחיסתם.
ציטוט: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
מילות מפתח: הפחתת מימדים, למידת רב-ממדנים, שכנים הקרובים, ממד פנימי, ויזואליזציה של נתונים