כשהממשלות, המדענים או סוקרים מנסים ללמוד משהו על אוכלוסייה שלמה — כמו הכנסה ממוצעת, תפוקת יבול או רמות זיהום — הם כמעט אף פעם לא מודדים את כל האנשים. במקום זאת הם בוחרים מדגם ומקזזים אותו לממדי האוכלוסייה. זה עובד טוב רק אם הנתונים מתנהגים בנימוס. במציאות, עם זאת, סקרים ומדידות מלאים בשגיאות וערכים קיצוניים שיכולים לעוות את התוצאות בצורה משמעותית. מאמר זה מציג שיטה חדשה לחישוב ממוצעים של אוכלוסייה שנשארת מהימנה גם כאשר הנתונים מבולגנים, מה שהופך החלטות המבוססות על סקרים לאמינות יותר.
כשממוצעים פשוטים משתבשים
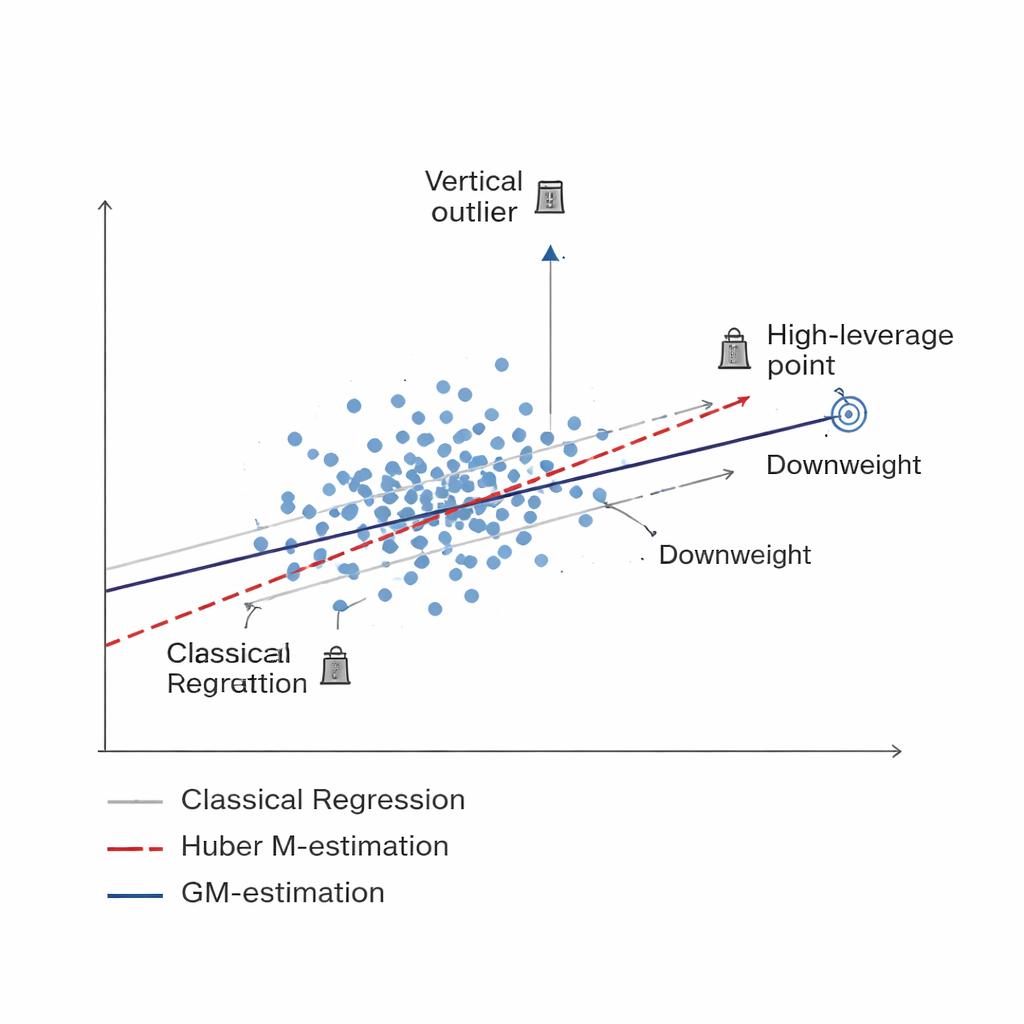
כלי הסטנדרטיים להערכת ממוצע אוכלוסייה, כמו ממוצע המדגם הפשוט או רגרסיה רגילה, מניחים שרוב נקודות הנתונים פועלות לפי דפוסים חלקים, ללא חריגים קיצוניים או מקרים בלתי רגילים. בסקרים חברתיים-כלכליים, במעקב סביבתי ובסטטיסטיקות חקלאיות, תקווה זו לעתים קרובות אינה מתקיימת. כמה קריאות תקולות, אירועים נדירים אך קיצוניים או תשובות מדווחות באופן שגוי יכולים למשוך את ההערכות הרחק מהאמת ולהגביר גם את ההטיה וגם את אי-הוודאות. עבודות קודמות ניסו להחליש את השפעת החריגים באמצעות שיטות חסינות, כולל גישה פופולרית הידועה כהערכת Huber M. למרות היותן מועילות, שיטות אלה מגנות בעיקר מפני ערכים קיצוניים בתוצאה הנמדדת ונשארות פגיעות לתבניות לא שגרתיות במידע המסביר הנלווה.
דרך חכמה יותר להמעיט במשקל של נתונים רעים Figure 1.
המחקר מפתח משפחה חדשה של מוקדדים המבוססת על Generalized M-estimation, או GM-estimation. במקום להתייחס לכל יחידת מדגם באותו אופן, שיטות GM מקצות משקלים אדפטיביים התלויים בשני גורמים במקביל: עד כמה תגובת היחידה קיצונית (חריג אנכי) ועד כמה המידע המשויך לה בלתי שגרתי (נקודת השפעה גבוהה). שלוש וריאציות ספציפיות — המכונות Mallows-GM, Schweppes-GM ו-SIS-GM — עוצבו עבור תצורות סקר נפוצות, כולל דגימה אקראית פשוטה ללא החלפה ועיצובים מפולחים מורכבים יותר בהם האוכלוסייה מחולקת לקבוצות יחסית הומוגניות. על ידי שליטה משותפת בשני סוגי התצפיות הבעייתיות, מטרת המוקדדים הללו היא לשמור על היציבות של הערכת הממוצע האוכלוסייתי גם כאשר הנתונים מכילים זיהום חמור.
ניסיון הבוחן את המוקדדים החדשים
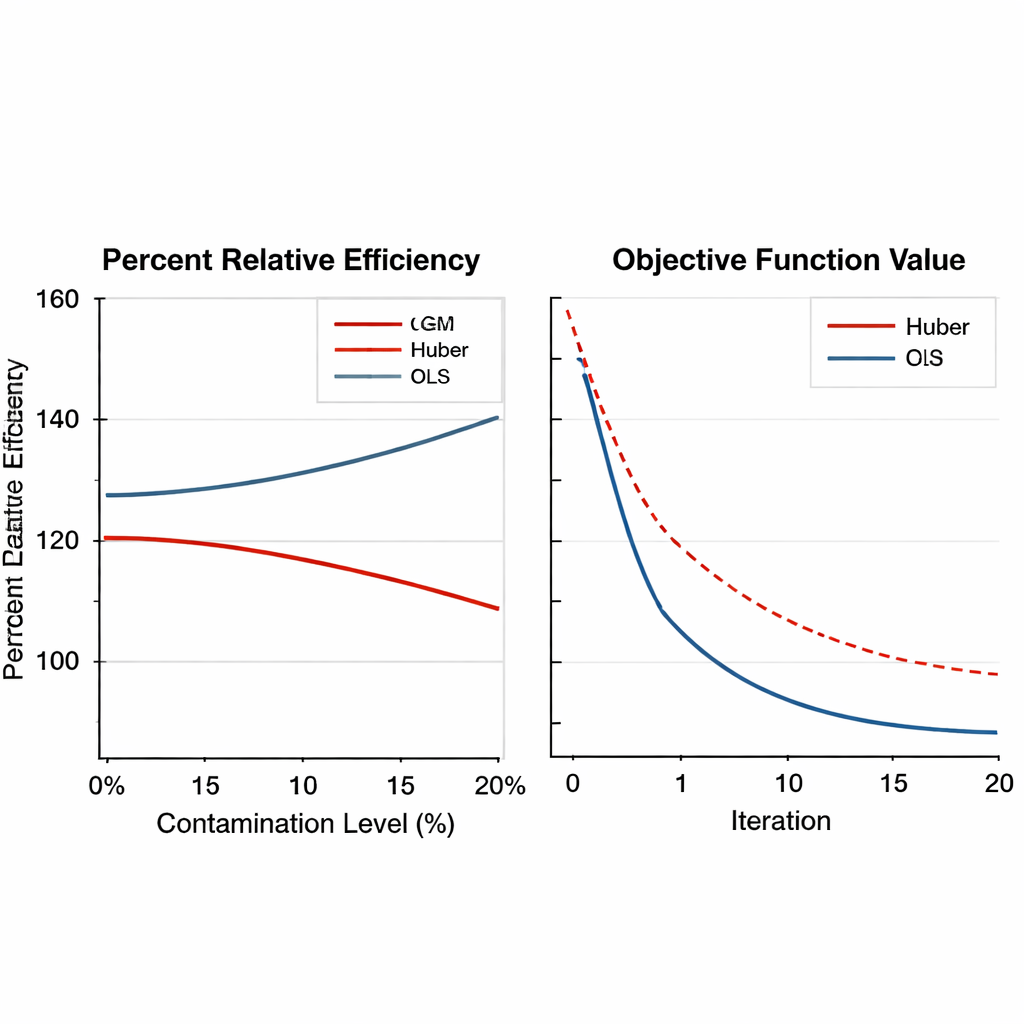
כדי לבדוק עד כמה המוקדדים מבוססי-GM עובדים, המחבר מבצע ניסויים מספריים נרחבים. תחילה מנותחים נתוני חקלאות טבק אמיתיים בשתי צורות: גרסה נקייה וגרסה שנזדהמה בכוונה שבה יחידה אחת הוחלפה בערכים קיצוניים. המוקדדים החדשים מושווים לרגרסיה קלאסית ולשיטות חסינות מבוססות Huber באמצעות מדד הנקרא אחוז היעילות היחסית, שמשקף עד כמה קטן שגיאת ההערכה. על פני מגוון רחב של גדלי מדגם, המוקדדים מבוססי-GM מכריעים בעקביות את השיטות הישנות, במיוחד כאשר הנתונים כוללים ערכים קיצוניים. בתרחישים מסוימים המוקדד הטוב ביותר מבוסס-GM מפחית את השגיאה ביותר מ-50 אחוז בהשוואה לגישת Huber.
המאמר מרחיב אז את הבדיקות באמצעות סימולציות ממוחשבות בקנה מידה גדול. אוכלוסיות מלאכותיות מונפקות תחת מספר צורות — נורמלית, מסולקת וזנבות כבדים — ונזדהמות בשיעורי חריגים משתנים, מאפס ועד 20 אחוז. נבחנות גם תכניות דגימה פשוטות וגם מדגמי-שכבות, ועוצמת הקשר בין המשתנה הראשי לעוזרים שלו נעה מחלשה לחזקה. המוקדדים מבוססי-GM לא רק שומרים על היתרון שלהם תחת זיהום כבד, לעתים משיגים רווחי יעילות מעל 150 אחוז, אלא גם מראים התכנסות מספרית חלקה ואמינה. חשוב מכך, ביצועיהם משתנים במעט כאשר הגדרות הכוונון הפנימיות מותאמות בטווחי סבירים, מה שאומר שמבצעי סקר אינם נדרשים לכוונון עדין במיוחד עבור כל סקר חדש.
מה משמעות הדבר לסקרים בעולם האמיתי
במילים פשוטות, המאמר מראה שהמוקדדים המוצעים מבוססי-GM מספקים דרך בטוחה יותר להפוך מדגמים בלתי מושלמים להערכות של ממוצעים ברמת האוכלוסייה. בתנאי נתונים אידיאליים ונקיים הם מדויקים בערך כמו השיטות הקלאסיות. אך כאשר הנתונים כוללים שגיאות מדידה, ערכים מדווחים באופן שגוי או אירועים נדירים קיצוניים — כפי שרווח בסקרים לאומיים, במעקב סביבתי ובסטטיסטיקה פיננסית — הם מספקים תשובות אמינות בהרבה. מכיוון שהם ישימים חישובית ועובדים היטב במגוון עיצובים והגדרות, המוקדדים הללו מציעים למבצעי סקרים שדרוג מעשי שיכול להכשיר קבלת החלטות מבוססת ראיות לעמידות מול הבלגן הבלתי נמנע של נתוני העולם האמיתי.
ציטוט: Abuhasel, K.A. A robust methodology for finite population mean estimation based on Generalized M estimation.
Sci Rep16, 5182 (2026). https://doi.org/10.1038/s41598-026-35592-5
מילות מפתח: דגימה בסקרים, הערכה חסינת-שיבושים, חריגים, הערכת M כללית, ממוצע אוכלוסייה סופי