Clear Sky Science · he
זיהוי אוטומטי של ישויות ביומדיקליות רלוונטיות בהקשר בעזרת LLMs מבוססי קרקע
מדוע תיוג חכם יותר של מאמרים רפואיים חשוב
כל שנה מתפרסמים אלפי מחקרים ביומדיקליים, כל אחד מלא בפרטים על גנים, סוגי תאים, מחלות וטיפולים. רוב המידע הזה נשאר לכוד בקבצי PDF ארוכים, מה שמקשה על מדענים אחרים למצוא את הנתונים המדויקים שהם צריכים. מאמר זה בוחן כיצד בינה מלאכותית מודרנית — מודלים גדולים של שפה (LLMs) — יכולה לשלוף באופן אוטומטי את המונחים הביומדיקליים המרכזיים ממאמרים, ולסייע להפוך פרסומים מפוזרים למשאבים מסודרים וניתנים לחיפוש.
ממאמרים מבולגנים לחלקי בניין ניתנים לחיפוש
מרכזי מחקר ביומדיקליים, כמו מרכזי מחקר שיתופיים בגרמניה, נסמכים על נתונים ברורים ומובנים כדי להבטיח שניתן להשתמש במחקרים שוב במשך שנים. מסורתית, חוקרים תייגו ידנית את מערכי הנתונים שלהם בישויות חשובות כגון אורגניזמים, קווי תאים וגנים — משימה מייגעת וגוזלת זמן. LLMs יכולים לקרוא מאמרים שלמים ולהבין הקשר, מה שהופך אותם לכלי מבטיח לאוטומציה של תיוג זה. אך יש תווי אזהרה: קביעה אילו מונחים באמת רלוונטיים תלויה בשאלה המדעית ובאופן שבו הנתונים ישמשו בעתיד. המחברים פועלים במסגרת סכמת מטא-דאטה מעוצבת בקפידה של CRC המתמקד בנפרולוגיה, "NephGen", שמנחה את ה-AI אילו סוגי ישויות לחפש ואיך לארגן אותן.
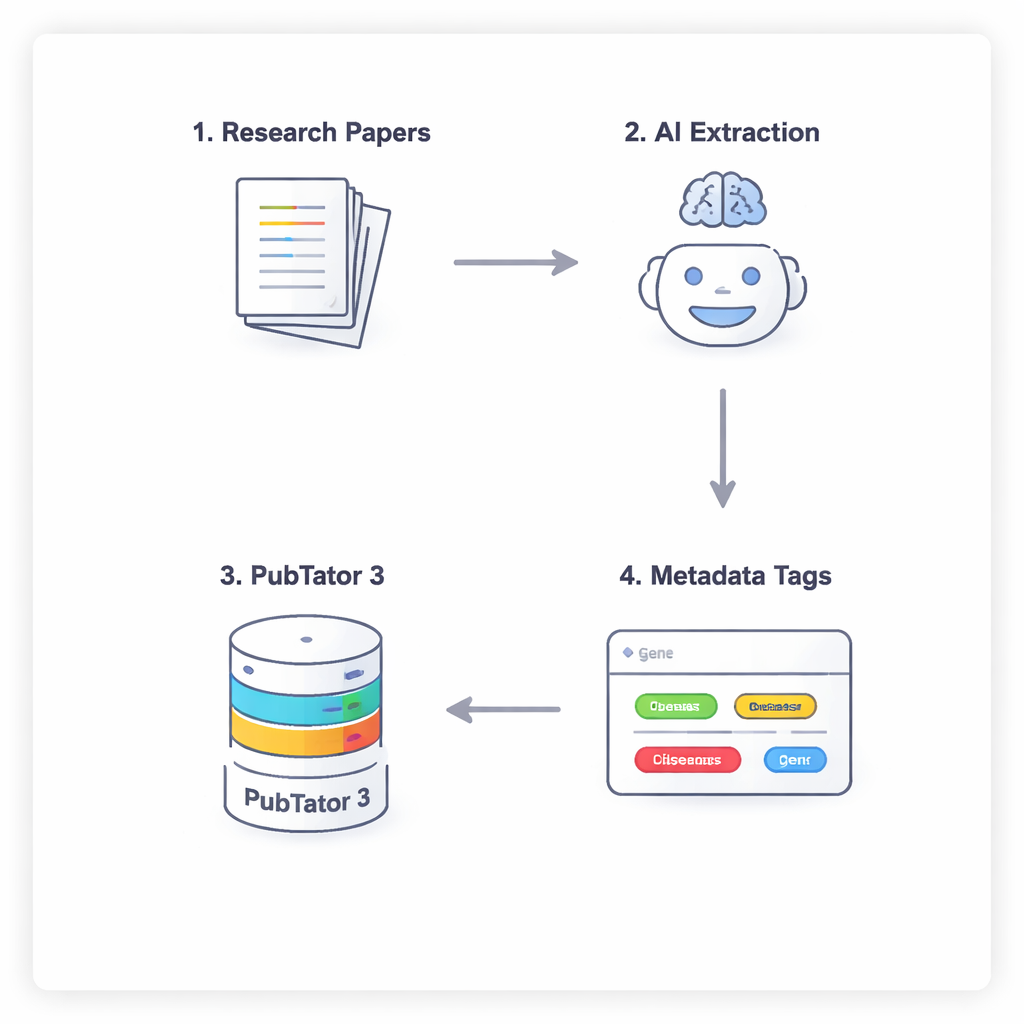
שיחה בת ארבעה שלבים בין ה-AI למסד נתונים ביולוגי
כדי למנוע מה-AI לנחש או "להזות" עובדות ביומדיקליות, החוקרים משתמשים בתהליך בעל ארבעה שלבים שמאליץ את המודלים לחשוב בזהירות ולבדוק את עצמם. ראשית, המודל סורק את הטקסט המלא של המאמר (מטיל בצד את הדיון והרפרנסים) ומציע ישויות פוטנציאליות רלוונטיות. שנית, עליו להתייעץ עם כלי חיצוני, PubTator 3, מסד נתונים ביומדיקלי גדול, כדי לאמת שכל מונח שהוצע אכן קיים ויש לו מזהה מוכר. שלישית, ה-AI ממפה כל ישות מאומתת לשדה במסגרת מטא-דאטה של NephGen, שמקבצת ישויות במבנה היררכי שתוכנן על ידי בני אדם. לבסוף, המודל מאחד את הכל לפורמט JSON מובנה — סיכום מסודר וקריא למכונה של הישויות הביומדיקליות המרכזיות במאמר.
בדיקת שמונה מודלים של AI עם מחקר כלייתי אמיתי
הצוות יישם את זרימת העבודה הזו באמצעות APIs עבור 14 LLMs שונים וגילה שרק שמונה מהן יכלו לעקוב בעקביות אחרי הדרישות המחמירות, כגון החזרת JSON ותקשור נכון עם כלים חיצוניים. הם החילו את שמונת המודלים הללו על שישה מאמרים בנפרולוגיה וביקשו מכל מחבר מאמר לסקור את הרשימה הסופית של הישויות במסגרת ראיון קצר פנים-אל-פנים. מאחר שאין מספר "נכון" קבוע של ישויות לחילוץ, החוקרים התמקדו בדיוק (precision): איזה חלק מהמונחים שהוצעו המדענים שפטו כנכונים. באמצעות שיטות מטא-אנליזה סטטיסטיות המותאמות לפרופורציות הקרובות ל-100%, הם העריכו דיוק לכל מודל תוך התחשבות בשונות בין המאמרים.
דיוק גבוה, אך פשרות במאמץ, עלות ומהירות
בכל המודלים ביחד הושג דיוק כולל של כ-91%, כלומר הרוב המוחלט של הישויות שהוצעו נשפטו כנכונות. GPT-4.1, GPT-4o Mini ו-Gemini 2.0 Flash הציגו את הדיוק הגבוה ביותר — בסביבות 94% עד 98% — אם כי ההבדלים ביניהן לא היו ברורים סטטיסטית. דגמי Gemini נטו להציע יותר ישויות בסך הכל, מה שהוביל ליותר תגים נכונים אך גם ליותר בדיקות שנדרשות מהאנשים. חלק מהמודלים הקטנים או הזולים יותר, כגון GPT-4.1 Nano, היו מהירים וזולים אך פחות מדויקים במידה משמעותית. המחברים ויזואליזו מתחים אלה באמצעות חזיתות פארטו, וזיהו שילובים של מודלים שמאזנים בין דיוק, מספר הישויות הנכונות, עלות וזמן עיבוד: לדוגמה, GPT-4o Mini עלה כפתרון אטרקטיבי כאשר גם דיוק וגם עלות נמוכה הם בראש סדר העדיפויות.
מדוע בני אדם עדיין שייכים לתהליך
למרות הביצועים החזקים, המחקר מדגיש מגבלות חשובות. המודלים לפעמים ערבבו מידע שנמצא במאמר המתפרסם עם פרטים שאינם באמת רלוונטיים למערך הנתונים שהמשתמשים העתידיים ירצו לשחזר. בלב הבעיה עומדת אתגר רחב יותר בכריית טקסט אוטומטית: מאמרים מדעיים דנים בהרבה מעבר למה שעובר בסופו של דבר למאגר משותף. לפיכך המחברים ממליצים שמומחים אנושיים ימשיכו לסקור את התיאורים שה-AI יוצר לפני פרסום. הם גם מציינים שההערכה שלהם כיסתה רק שישה מאמרי נפרולוגיה, ולכן נדרשת בדיקה רחבה יותר בתחומים אחרים. עם הזמן, זרימת עבודה שגרתית של "אדם בתווך" תוכל ליצור סט ייחוס מוסכם, ולאפשר מדידה לא רק של דיוק אלא גם של כמה ישויות ה-AI פספס.
מה משמעות הדבר לשיתוף נתונים ביומדיקליים בעתיד
המחקר מראה כי, כשהם מונחים בקפידה ומוצמדים למסדי נתונים מהימנים, מודלים גדולים של שפה מודרניים יכולים לסייע באופן אמין בתיעוד מאמרים ביומדיקליים, ולהקטין משמעותית את העומס הידני על החוקרים. הדגמים הטובים ביותר מתקרבים לדיוק ברמה מומחית ומציעים מגוון פשרות בין מקיפות, עלות ומהירות. לעת עתה סקירה אנושית נשארת חיונית כדי להבטיח שהתיאורים תואמים באמת את מערכי הנתונים והקונטקסט המחקרי. עם זאת, ככל שהכלים והמודלים בקוד פתוח ימשיכו להתפתח, זרימות עבודה מסוג זה עלולות להפוך לשרשרת עיקרית שתהפוך את הצפה של מאמרים רפואיים של היום למשאב נתונים מאורגן ושמיש של מחר.
ציטוט: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
מילות מפתח: כריית טקסטים ביומדיקליים, מודלים גדולים של שפה, תיאום מטא-דאטה, בינה מלאכותית מבוססת קרקע, מחקר נפרולוגי