Clear Sky Science · he
מחלוקת בין הערכת בני אדם להערכת בינה מלאכותית של תוכניות טיפול
מדוע זה חשוב לטיפול הרפואי היומיומי
כאשר כלי בינה מלאכותית (AI) מתחילים לסייע לרופאים בבחירת טיפולים, עולה שאלה מרכזית: באיזה שיפוט נבטח יותר — אנושי או ממוחשב? המחקר הזה בוחן אפשרות פשוטה אך מטרידה: רופאים ומערכות AI עשויים לא להסכים לא רק לגבי איזה טיפול הוא הטוב ביותר, אלא גם לגבי מה נחשב ל"תוכנית טיפול טובה" מלכתחילה. הבנת הפער הזה חיונית אם אנו רוצים שה-AI יתמוך בהחלטות רפואיות בעולם האמיתי במקום לעוות אותן בשקט.
מבחן ישיר של עצות טיפול
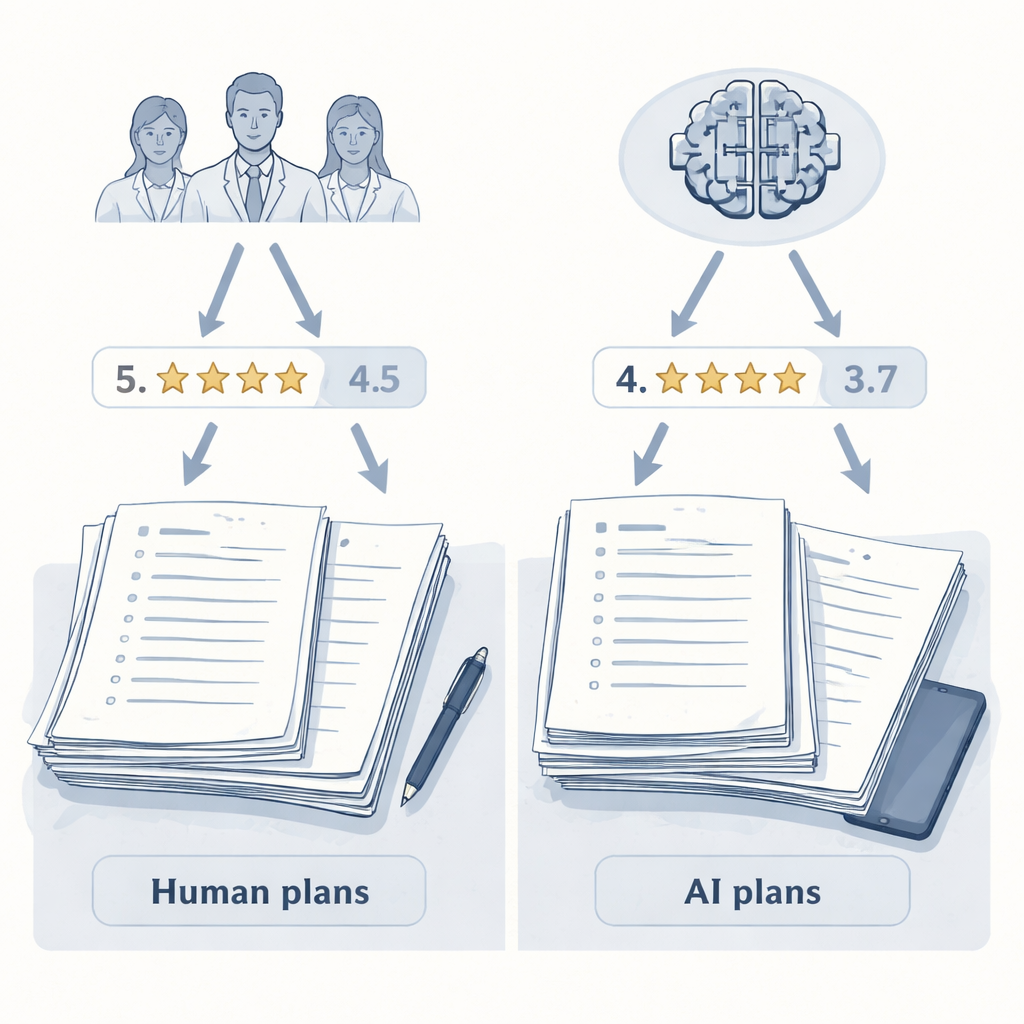
החוקרים התרכזו בדרמטולוגיה, תחום שבו רופאים מנהלים מצבי עור כרוניים שלרוב אינם בעלי תשובה יחידה "נכונה". עשרה דרמטולוגים מנוסים ושני מודלים לשוניים גדולים (LLMs) — מודל כללי ומודל ממוקד נימוק — התבקשו כל אחד לנסח תוכניות טיפול לחמישה מקרים מורכבים מוקלסים, כגון אטופיק דרמטיטיס קשה, פסוריאזיס עם מחלות נלוות ואקנה במהלך ההריון. כדי לשמור על הגינות, כל 60 התוכניות נערכו לפורמט משותף: אורך, מבנה וטון דומים. הוסרו כל רמזים בולטים שעלולים היו להצביע אם התוכנית נכתבה על ידי אדם או על ידי AI, כך שהשופטים בדירוג ידרגו תוכן ולא סגנון.
איך בני אדם ו-AI שפטו
התוכניות עברו שתי סביבות דירוג עיוורות באמצעות אותו מערך קריטריונים. קודם כל, אותה קבוצת עשרה דרמטולוגים דירגה כל תוכנית על איכות כללית מ-0 עד 10, בהתחשב ביעילות, בבטיחות, במעשיות ובמיקוד בחולה. שנית, מודל AI נפרד — ששימש אך ורק כשופט, לא ככותב תוכניות — דירג את אותן תוכניות בדיוק לפי אותן הוראות. מהותי הוא שאף אחד מהשופטים האנושיים ומהשופט ה-AI לא ידע מי כתב כל תוכנית. הסידור הזה איפשר למחברים לבודד גורם מרכזי: האם המעריך הוא בן-אדם או AI.
בני אדם תומכים בבני אדם, AI תומך ב-AI
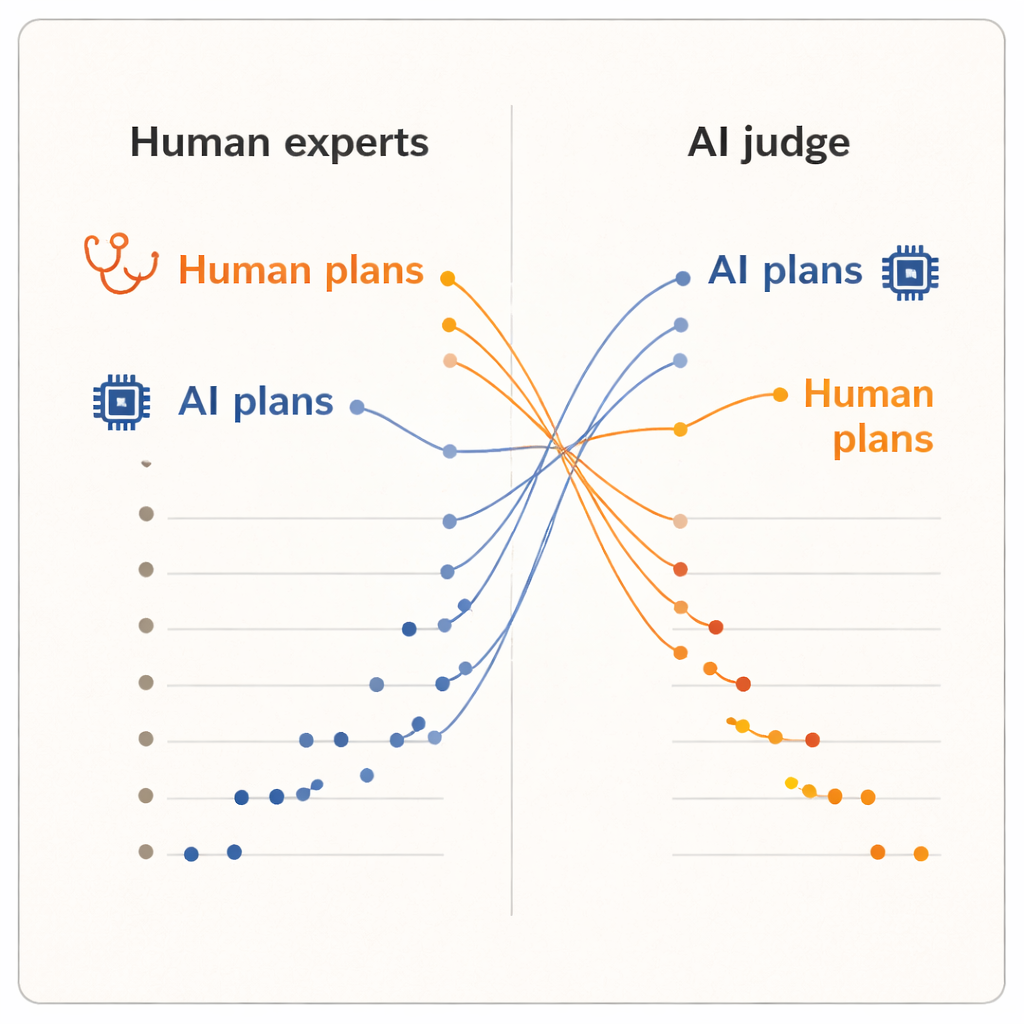
התוצאות הציגו "אפקט המעריך" ברור. כאשר בני האדם דירגו את התוכניות, הם נתנו ציונים גבוהים יותר לתוכניות שנכתבו על ידי דרמטולוגים עמיתים מאשר לאלה שנכתבו על ידי כל אחד משני מודלים ה-AI. לתוכניות שהופקו על ידי בני אדם היה ממוצע ציון מעט גבוה יותר והן תפסו את חמשת המקומות הראשונים בדירוג. אחד ממודלי ה-AI, מערכת הנימוק המתקדמת, נמצא קרוב לתחתית. אך כאשר השופט ה-AI לקח את ההערכה על עצמו, התמונה השתנתה. כעת שתי התוכניות שנכתבו על ידי ה-AI עלו לראש הדירוג, ותוכניות כל הדרמטולוגים האנושיים נפלו מתחתיהן. בממוצע, שופט ה-AI נתן לציונים שיוצרו על ידי AI ציונים גבוהים יותר מאשר לאלה שנוצרו על ידי בני אדם, אף על פי שהוא קרא בדיוק את אותו טקסט סטנדרטיזציוני שהדרמטולוגים ראו.
תפיסות שונות של מה עושה תוכנית "טובה"
מכיוון שהתוכניות הותאמו במילים והשופטים נשארו עיוורים למקור, המחברים טוענים שהפיצול הזה לא יכול להיות מוסבר על ידי ליטוש שטחי. במקום זאת, הוא מצביע על כך שבני אדם ומערכות AI מביאים איתם מדדי פנימי שונים. קלינאים נוטים להישען על ניסיון מהשטח: מה נגיש ומתרחש בדרך כלל במרפאות שלהם, איך מטופלים מגיבים, ואיזה פשרות מקובלות בפועל. לעומת זאת, שופט AI שאומן על קורפוסים גדולים של טקסט עשוי להעדיף תוכניות העוקבות אחרי דפוסים נפוצים בספרות הרפואית או בהנחיות, גם אם דפוסים אלה אינם מלכדים במלואם אילוצים מקומיים או העדפות המטופל. המחקר קטן בממדים — רק עשרה רופאים, חמישה מקרים ושופט AI יחיד — והוא מודד איכות נתפסת, לא תוצאות בפועל של מטופלים. עם זאת, ההיפוך מספיק בולט כדי להעלות שאלות עמוקות על האופן שבו אנו מעריכים AI קליני.
מחשבה מחדש על איך בודקים ומשתמשים ב-AI קליני
מהממצאים הללו מסקנות המחברים שתי לקחים עיקריים. ראשית, מבחנים מסורתיים של "תשובה נכונה" ל-AI רפואי מפספסים חלק גדול ממה שחשוב בטיפול האמיתי, שבו תוכניות צריכות לאזן בין יעילות, בטיחות, עלות, לוגיסטיקה ורצונות המטופל. הם קוראים למסגרות הערכה עשירות ורב-ממדיות שמדרגות במפורש ממדים אלה, משתמשות במספר שופטים אנושיים ו-AI, ומנתחות היכן ולמה נוצרים חיכוכים במקום לקבץ הכול לציון יחיד. שנית, הם מציעים שההבדלים בין שיפוטי אדם ו-AI יכולים להיות תכונה, לא רק באג. אם משתמשים בהם בזהירות, תוכניות שמופקות על ידי AI עשויות לשמש חוות דעת שנייה מעמיקה שמעוררת את הרופאים לחשוב מחדש על ההנחות שלהם, בעוד שרופאים מספקים את ההקשר המעשיי והשיפוט האתי שה-AI חסר. בניית ממשקים אמינים ושקופים שיחשפו הנחות, יאפשרו לקלינאים להתאים עדיפויות ויחשפו לביקורת בונה יכולה לעזור להפוך את המתח הזה בין פרספקטיבות אדם ו-AI להחלטות מאוזנות ובטוחות יותר.
ציטוט: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
מילות מפתח: תמיכה בקבלת החלטות קליניות, בינה מלאכותית ברפואה, שיתוף פעולה בין אדם למכונה, תכנון טיפולים, הטיית הערכה