Clear Sky Science · he
גישה של למידת חיזוק עמוקה לניתוח תנועות ריקוד
ללמד מחשבים לצפות בריקוד כמו שאנחנו עושים
מבאלט ועד היפ-הופ, ריקוד מלא בהזזות עדינות של קצב ויציבה שעינינו קולטים מיד — אך מחשבים מתקשים לראות אותן. המחקר הזה מציג דרך חדשה ל"צפייה" של בינה מלאכותית בסרטוני ריקוד בדומה למומחה אנושי, מדלגת על צעדים שגרתיים כדי להתמקד ברגעים קצרים וחושפים שמגדירים כל סגנון. התוצאה היא מערכת שמזהה ז'אנרים של ריקוד בדיוק גבוה יותר תוך צפייה בעיקר בחלק קטן מהוידאו — יתרון פוטנציאלי לארכיונים דיגיטליים, לטכנולוגיות ספורט ובידור ועוד.
מדוע סרטוני ריקוד קשים למכונות
מבט ראשון עשוי לרמז שהכשרת מחשב לזיהוי סגנונות ריקוד קלה: להזין וידאו ולתת ללמידה עמוקה למצוא דפוסים. בפועל, רוב המערכות הקיימות מבזבזות מאמץ. מודלים סטנדרטיים מעבדים כל פריים או דוגמים קטעים ברווחים קבועים, מתוך הנחה שכל רגע חשוב באותה מידה. אבל סגנונות ריקוד נבדלים לעתים בפרטים זעירים — איך כף הרגל מסתובבת, מתי פרטנר מסובב, או תזמון סיבוב — ולא בתנועה רציפה תמידית. משמעות הדבר היא שרבים מהפריימים חזרתיים או חסרי מידע, ופוזות מכריעות עלולות להתרחש בין נקודות דגימה קבועות, מה שמוביל לבלבול בין, למשל, ולס לפוקסטרוט.
דרך חכמה יותר לדפדף בזמן הווידאו
החוקרים מציעים מסגרת שנקראת דגימה זמנית קשובה מבוססת חיזוק, או RATS, המתייחסת לניתוח וידאו כחיפוש פעיל במקום צפייה פסיבית. במקום לעבור פריים אחר פריים, המערכת מחלקת את סרט הריקוד לקליפים קצרים וממירה כל קליפ לתיאור קומפקטי של התנועה באמצעות רשת קונבולוציה תלת־ממדית מתמחה. סיכומי התנועה הללו מאוחסנים בזיכרון. מעליהם פועל סוכן קבלת החלטות שעובר על רצף הקליפים, ובוחן האם לקפוץ קדימה בקפיצה קטנה, בקפיצה גדולה יותר, או לעצור ולהוציא ניבוי של הסגנון. למעשה, המערכת לומדת כיצד לגלוש בזמן — להתעכב על דפוסים מובהקים ולדלג על מקטעים פחות מועילים.
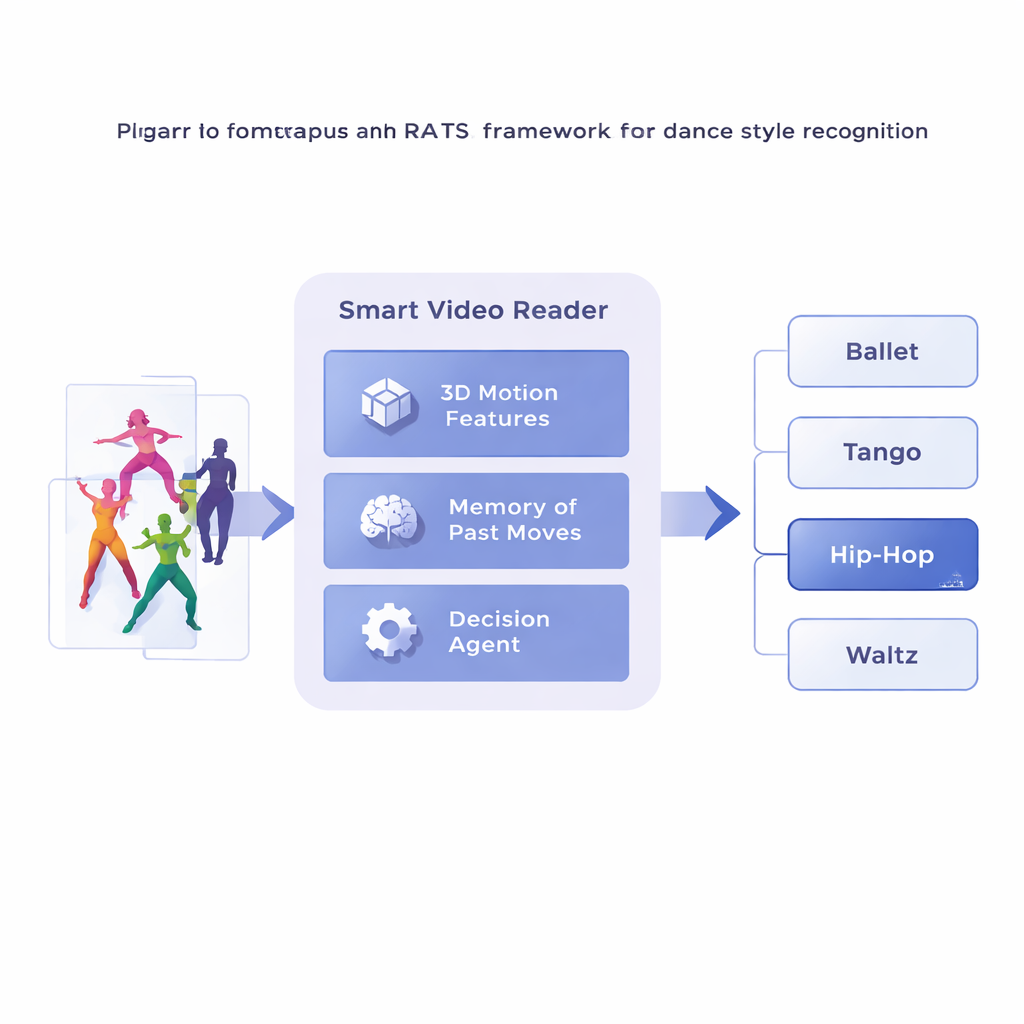
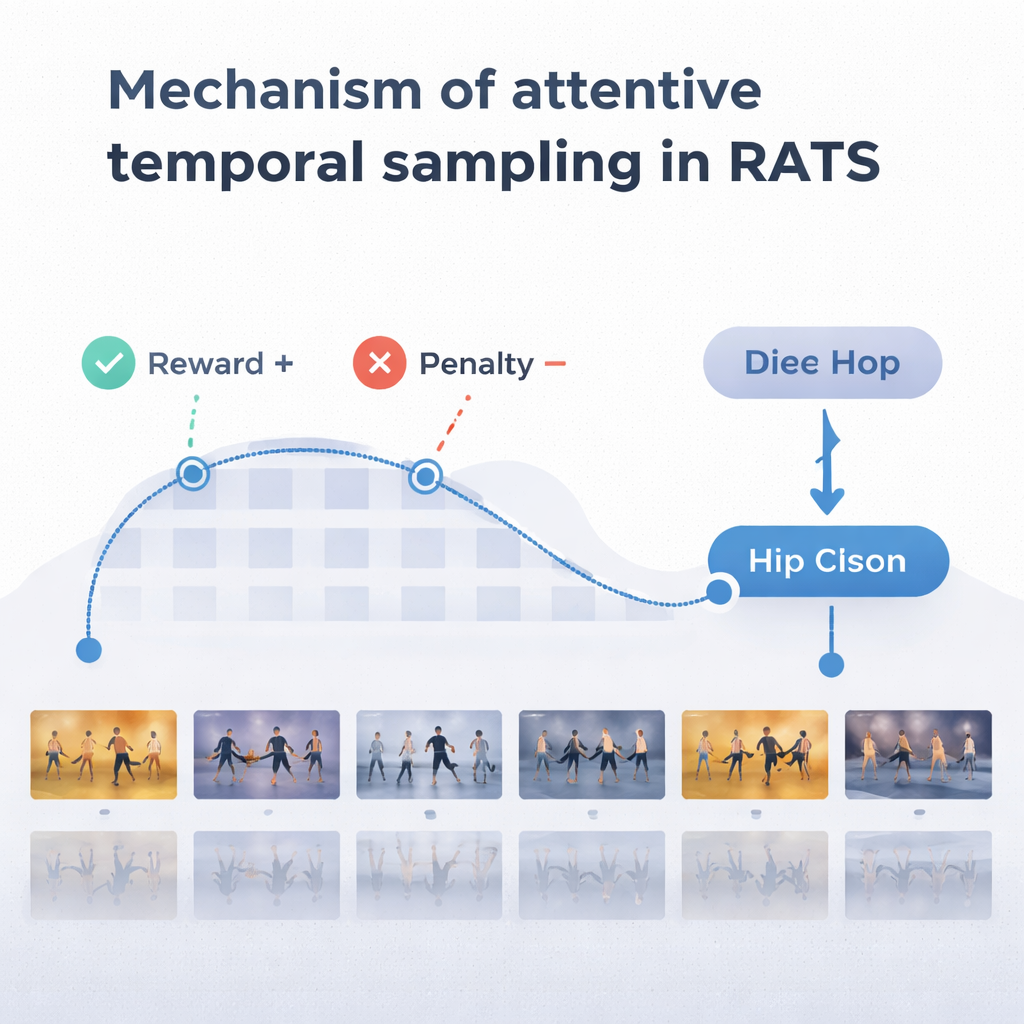
ללמוד מתי להסתכל ומתי להחליט
כדי לקבל החלטות סבירות, הסוכן מסתמך על צורת זיכרון בהשראת האופן שבו אנו זוכרים גם תנועה עברית וגם תנועה מתפתחת. רשת חוזרת דו־כיוונית עוקבת אחר מה שהמערכת כבר "ראתה" וכיצד הקליפים הנוכחיים מתקשרים להיסטוריה הזו. בכל צעד הסוכן שוקל שלוש אפשרויות: לבצע קפיצה קצרה לבחינת פרטים עדינים כמו עבודת רגליים, לקפוץ למרחק גדול יותר מעל תנועה חזרתית, או לעצור ולסווג את הריקוד. המערכת מאומנת בעזרת תגמולים ועונשים: היא זוכה לניקוד חיובי גדול על החלטה נכונה, לניקוד שלילי גדול על החלטה שגויה, ולעונש קטן בכל פעם שהיא קופצת קדימה. האיזון הזה מעודד את הסוכן להיות גם מדויק וגם יעיל — להמתין עד שיש מספיק ראיות, אך לא לשוטט לאורך כל הווידאו.
מתעלה על מסווגי ריקוד מסורתיים
הצוות בחן את RATS על מאגר Let’s Dance, אוסף מאתגר של 1,000 סרטונים המכסים עשרה סגנונות, מפמנקו וטנגו ועד סווינג וריקוד ריבועי. בהשוואה למספר שיטות קיימות, כולל רשתות עמוקות סטנדרטיות ומודלים ממוקדי ריקוד אחרים, RATS השיגה את הדיוק הגבוה ביותר — כ־92% — ואת האיזון הטוב ביותר בין דיוק לזכירות. היא הוכחה גם כטובה מבחינה סטטיסטית לעומת מתחרים חזקים, ולא רק שונה במקרה. חשוב לציין כי המערכת הגיעה לתוצאות אלו בעוד שבממוצע ניתחה רק כ־38% מהפריימים בסרטון. דגימה אחידה כל כמה פריימים הייתה מהירה יותר אך החמיצה רגעים מכריעים וירדה בביצועים; עיבוד כל הפריימים היה איטי יותר ועדיין פחות מדויק מהגישה הממוקדת.
מה המשמעות מעבר לרחבת הריקודים
עבור לא־מומחה, המסר המרכזי פשוט: מחשבים יכולים לבצע משימה טובה יותר כשהם לומדים להיות צופים סלקטיביים. על ידי לימוד בינה מלאכותית להתרכז ב"רגעים זהב" בזמן, העבודה הזו מראה שמכונות יכולות לזהות תנועות אנושיות מורכבות בדיוק רב יותר תוך שימוש במשאבים מועטים יותר. למרות שהמחקר מתמקד בריקוד, אותה הרעיון יכול לסייע למערכות לבודד אלמנטים מרכזיים בשגרת ספורט, בצילומי אבטחה או בכל וידאו ארוך שבו האירועים החשובים קצרים ומפוזרים. במילים אחרות, צפייה חכמה — לא צפייה מרובה יותר — עשויה להיות העתיד של הבנת וידאו.
ציטוט: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
מילות מפתח: זיהוי ריקוד, ניתוח וידאו, למידה עמוקה, למידת חיזוק, תנועת אדם