Clear Sky Science · he
מודל חילוץ יחסי מרחב בסינית על ידי שילוב תכונות סמנטיות גאוגרפיות
להדריך מחשבים להבין היכן מקומות נמצאים
כל יום אנחנו מתארים מיקומים בפורמולציות פשוטות: עיר שוכנת מדרום לנהר, פארק סמוך לאוניברסיטה, כביש עובר דרך פרובינציה. המרת שפה יומיומית מסוג זה לידע דיגיטלי מדויק חשובה למפות חכמות, אפליקציות ניווט ומחקר גאוגרפי. המאמר מציג שיטה חדשה, הקרויה PURE‑CHS‑Attn, שעוזרת למחשבים לקרוא טקסטים בסינית ולבחון אוטומטית את היחסים המרחביים בין מקומות בצורה מדויקת יותר מבעבר.
מדוע שפת מרחב חשובה
יחסי מרחב הם מילים וביטויים שמספרים לנו כיצד מקומות מקושרים בחלל, כגון «בתוך», «ליד», «צפון־מגודר של» או «30 קילומטרים מ‑». הם מהווים גשר בין העולם שאנו רואים במפות לבין המושגים במוחותינו. במערכות מידע גאוגרפיות (GIS) יחסים אלה מהווים בסיס לאופן שבו הנתונים מאורגנים, מחופשים ומנותחים. הם גם מרכזיים בתחומים אחרים: למשל, שילוב תמונות לוויין, מעקב תנועה בסרטון, תכנון תשתיות תעשייתיות או חקירת השפעת אקלים וצורות קרקע על מגוון ביולוגי. כיוון שחלק גדול מהמידע הזה נכתב בשפה טבעית, כלים אמינים שמסוגלים לקרוא וטוחנים יחסי מרחב מטקסט באופן אוטומטי הופכים לחשובים יותר ויותר.
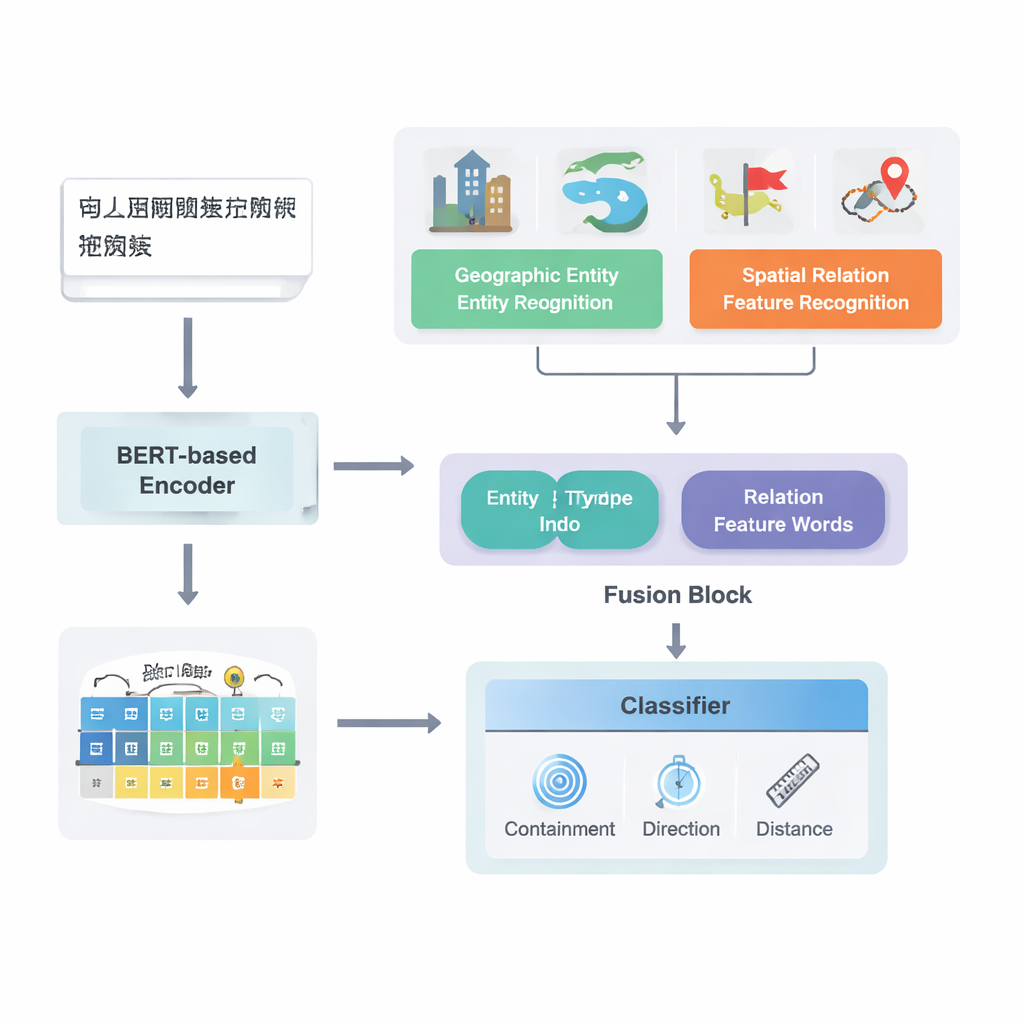
מטקסט גולמי ליחסים ממופים
המחברים מתמקדים בטקסטים בסינית ובונים על צינור למידה עמוקה חזק קיים הידוע כ‑PURE. המודל המשופר שלהם, PURE‑CHS‑Attn, פועל בכמה שלבים. ראשית, הוא סורק משפטים כדי לאתר ישויות גאוגרפיות כגון הרים, נהרות, ערים ואזורים מנהליים, ומסווג כל אחת לפי סוג (למשל פני קרקע, גוף מים, מתקן ציבורי, אתר היסטורי או חלוקה מנהלית). לאחר מכן הוא מזהה "מילות תכונה" של יחסי מרחב כמו «גובל», «נוזל דרך», «דרומית ל‑» או «ליד», שמאותתות כיצד שני מקומות קשורים. מודל שפה חזק, BERT‑wwm‑ext, ממיר את התווים בכל משפט לווקטורים מספריים שתופסים משמעות והקשר. וקטורים אלה מוזנים לרכיבים נפרדים שמזהים ישויות ומילות יחס, ואז מעבירים את תוצאותיהם למודול מיזוג.
שילוב ידע אנושי עם למידת מכונה
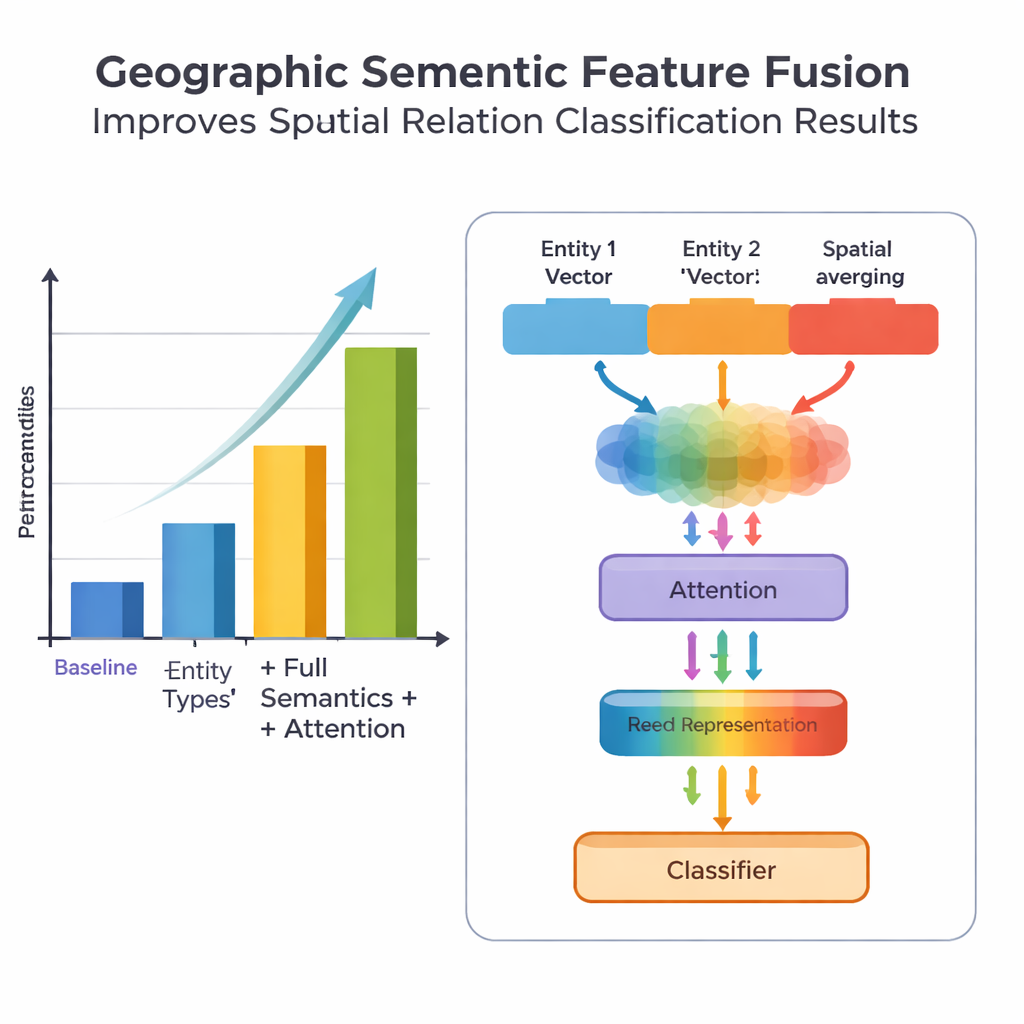
החידוש המרכזי בעבודה נעוץ באופן שבו היא ממזגת ידע גאוגרפי עם תבניות טקסט שלמדו. במקום להתייחס לכל מילה שווה, המודל מנצל שני סוגי מידע סמנטיים שאנשים משתמשים בהם באופן טבעי: סוג כל ישות גאוגרפית והמילות תכונה המרחביות הספציפיות שמקשרות ביניהן. מודול המיזוג משלב תחילה את הווקטורים של שתי היישויות באמצעות משקלים התלויים בתדירות שבה סוגי מקומות שונים (כמו שתי יחידות מנהליות לעומת נהר ומחוז) משתתפים בסוגי יחסים שונים. לאחר מכן הוא משלב את וקטורי מילות התכונה המרחביות. בנוסף ל"מיזוג בסיסי" זה, המחברים מוסיפים מנגנון תשומת לב שמאפשר למודל להתמקד באופן דינמי בחלקים המידעיים ביותר בצירוף ישות–מילה. הייצוג הממוזג הסופי מועבר למכסוֵת, שיכול להקצות סוגי יחסים—טופולוגיים (כמו הכלה או סמיכות), כיווניים (צפון, דרום וכו') או מבוססי־מרחק—לבין כל זוג מקומות במשפט.
מבחן המודל
להערכת הגישה שלהם, הצוות אסף וסימן בקפידה מערך נתונים מתוך "אנציקלופדיה של סין: גיאוגרפיה סינית", המכיל 1381 משפטים ו‑368 זוגות יחסי מרחב. הם השוו כמה גרסאות של המודל: בסיסי שמשתמש רק במידע מיקום גס, גרסה עם טיפוסי ישות מדויקים יותר, גרסה שמוסיפה גם מילות תכונה מרחביות, והגרסה המלאה שלהם PURE‑CHS‑Attn עם עיצוב המיזוג והתשומת הלב החדש. על פי מדדים סטנדרטיים של דיוק, שליפיות (recall) וניקוד F1, PURE‑CHS‑Attn שיפר ביצועים בכ־7% בדיוק, 6.5% בשליפיות ו‑6.7% ב‑F1 מול הבסיס. הוא היה חזק במיוחד בזיהוי יחסים טופולוגיים וכיווניים, וטיפל טוב יותר בסוגי יחסים נדירים "מעט‑דוגמאיים" מאשר מודלים פשוטים יותר. בהשוואה לשלוש מערכות מתקדמות עכשוויות, כולל אחת מבוססת מודלים גדולים של שפה, PURE‑CHS‑Attn הגיע קרוב למקום השני בעודו נשאר קל יותר ומשתמשי פריסה פשוטה יותר.
אתגרים וכיווני עתיד
למרות השיפורים, המודל עדיין מתקשה עם יחסי מרחק, במיוחד כאשר קיימות רק מספר דוגמאות אימון מועטות. המחברים מראים שמערך הנתונים שלהם מכיל מעט מקרים כאלה, מה שמגביל את מה שכל שיטה הצמאה לנתונים יכולה ללמוד. הם גם מציינים כי ממוצע עיוור של מילות תכונה מרחביות רבות במשפט יכול להכניס רעש, שמנגנון התשומת לב שלהם מסייע להפחית אך לא פותר במלואו. מבט לעתיד מציע שני מסלולים מבטיחים: הגדלה ואיזון של נתוני האימון באמצעות הגברה, ושילוב המיזוג הסמנטי הגאוגרפי שלהם עם טכניקות ממודלים גדולים של שפה ולמידה מבוססת‑הנחיה (prompt‑based) כדי להגביה עוד יותר ביצועים בתרחישים דלי‑נתונים תוך שמירה על יעילות המערכת.
מה משמעות הדבר למיפוי יומיומי
במונחים פשוטים, המחקר הזה מלמד מחשבים לקרוא תיאורים מרחביים בסינית יותר כמו בני אדם, על ידי שימת לב לאילו סוגי מקומות מוזכרים וכיצד בדיוק מנוסחים יחסיהם. מודל PURE‑CHS‑Attn מראה ששילוב ידע גאוגרפי מובנה עם למידה עמוקה מודרנית מוביל לחילוץ מדויק ויציב יותר של "מי היכן, יחסית למה" מתוך טקסט. זה פותח את הדרך למערכות GIS חכמות ואוטומטיות יותר, גרפים של ידע גאוגרפי עשירים יותר וכלים טובים יותר לחקר האופן שבו מרחב מתואר במדע, במדיניות ובתקשורת היומיומית.
ציטוט: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
מילות מפתח: חילוץ יחסי מרחב, בינה גאו‑מكانية, סמנטיקה גאוגרפית, כריית טקסטים בסינית, אוטומציה GIS