Clear Sky Science · he
זיהוי יעיל של תקצירי מדע שנוצרו על ידי בינה מלאכותית באמצעות טרנספורמר קל־משקל
מדוע חשוב לזהות כתיבה מדעית שנעשתה על ידי בינה מלאכותית
כשבינה מלאכותית משתפרת בכתיבה, היא כבר מסוגלת לערוך תקצירים מדעיים שנראים כמעט בלתי ניתנים להבחנה מאלו שנכתבו על ידי בני אדם. זה מעלה שאלות קשות: כיצד כתה־עתים, אוניברסיטאות וקוראים יכולים לוודא שתקציר מחקר משקף באמת את עבודתו של המדען ולא המצאה של מכונה? המאמר הזה מתמודד עם הבעיה על ידי בניית כלי מהיר וקומפקטי שיכול לסמן תקצירים מדעיים שנכתבו על ידי בינה מלאכותית באמינות גבוהה, ומציע הגנה מעשית על היושרה האקדמית.
בניית ערכת מבחן של תקצירים אמיתיים וסינתטיים
כדי למדוד ולשפר זיהוי טקסט של בינה מלאכותית, החוקרים נזקקו תחילה לנתונים מהימנים. הם אספו 5,000 תקצירים מדעיים משרת הפרה־פרינט arXiv, שכוללים חמש תחומים: ראייה ממוחשבת, עיבוד אותות, ביולוגיה כמותית, פיזיקה ונושאים אחרים במדעי המחשב. לכל תקציר שנכתב על ידי אדם הם השתמשו במודל שפה גדול כדי ליצור גרסת בינה מלאכותית מתוך כותרת המאמר, וביצעו בדיקה קפדנית למניעת כפילויות קרובות והסירו רמזים בולטים כגון כתובות אינטרנט או קטעי קוד. הם גם דאגו שאורכי הטקסטים של הבינה והאנושיים יהיו דומים, כדי שהגלאי לא יוכל להסתמך בפשטות על סטטיסטיקות גסות כמו ספירת מילים.
מודל קומפקטי מכוייל לעולם האמיתי
במקום להשתמש במודל ענק ויקר, החוקרים בחרו במערכת קטנה יותר הידועה כ‑DistilBERT, גרסה מצומצמת של מודל שפה פופולרי. כיוונו אותה להכריע, עבור כל תקציר, האם נכתב על ידי אדם או נוצר על ידי בינה מלאכותית. המודל קורא עד 256 טוקנים—בערך כמה פסקאות—ומפיק ציון בין אפס לאחד, שמפורש כהסתברות שהטקסט נוצר על ידי מכונה. האימון וההערכה נעשו לפי פרוטוקול מחמיר: הנתונים חולקו לסטים של אימון, ואלידציה ומבחן ללא חפיפה, והצוות דיווח לא רק על דיוק אלא גם על ההתנהגות של המודל כאשר שומרים על שיעור אזעקות שווא נמוך מאוד — מצב שחשוב כשמואשמים מחברים אמיתיים בשימוש בבינה מלאכותית.
כמה טוב הגלאי מתפקד
על תקצירים מתחום הראייה הממוחשבת, ערכת המבחן המרכזית, הגלאי היה מדויק בצורה מרשימה. הוא תייג נכון 499 מתוך 500 טקסטים שנוצרו על ידי בינה מלאכותית ו‑495 מתוך 500 טקסטים אנושיים, והשיג דיוק של כ‑99.4% וציון כמעט מושלם בעקומת ביצוע סטנדרטית. כאשר הכניסו מגבלה של מקסימום טענה שגויה אחת במאה מקרים, הוא עדיין זיהה כ‑90% מהטקסטים של הבינה; עם סובלנות מעט גבוהה יותר של חמש אזעקות שווא במאה, הוא תפס כ‑97%. בהשוואה למגוון חלופות — כולל כלים סטטיסטיים פשוטים ומודלים טרנספורמר נוספים — הגלאי הקומפקטי יצא תמיד בראש, במיוחד בתרחישים תובעניים יותר.
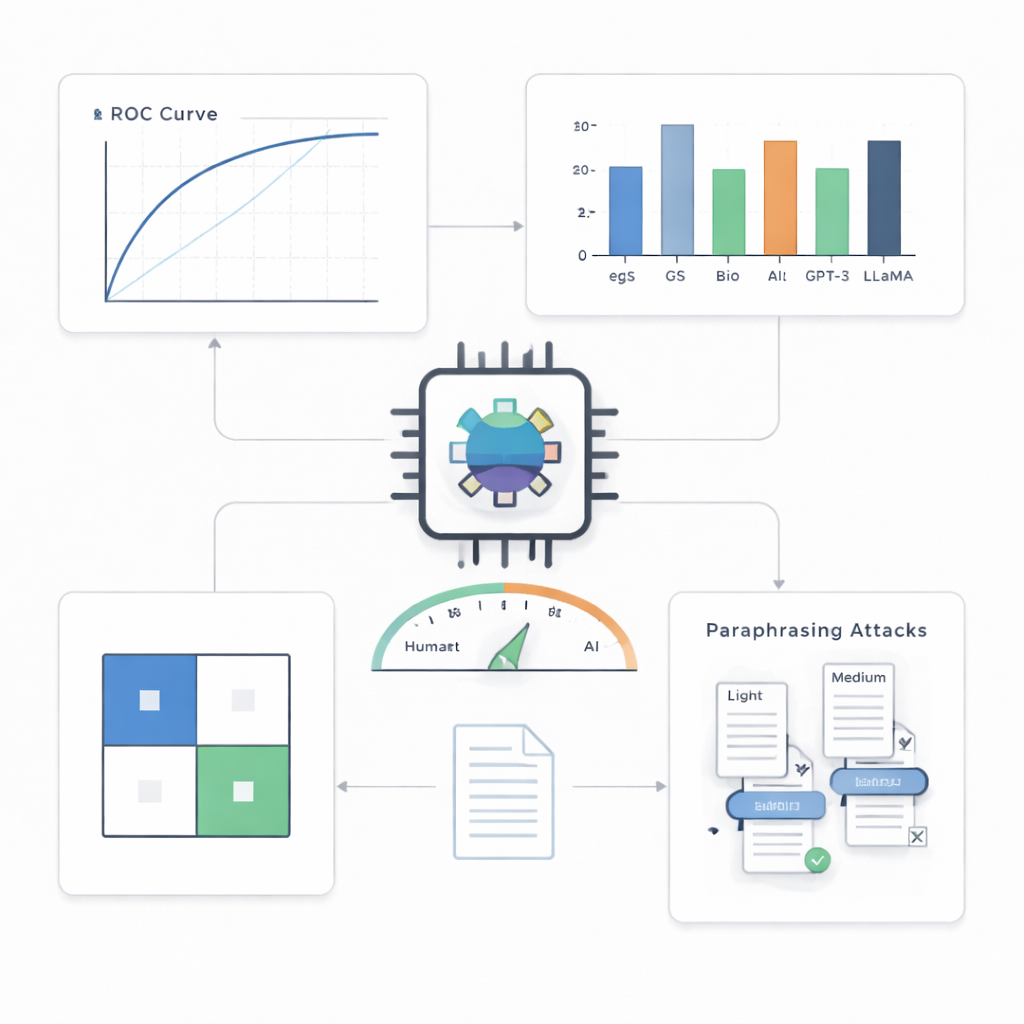
מעבר לתחום אחד, מודל אחד וטריקים פשוטים
שאלה מרכזית היא האם גלאי כזה יכול להתמודד עם סגנונות כתיבה ומערכות בינה מלאכותית שהוא לא פגש קודם. החוקרים בחנו אותו על תקצירים מתחומים מדעיים אחרים ועל טקסטים שנוצרו על ידי כמה מודלים מתקדמים שונים. כללית, הביצועים נשארו חזקים עם ירידות מתונות בלבד, מה שמרמז שהמערכת לוכדת דפוסים כלליים של כתיבת בינה מלאכותית ולא רק מאפיינים של תחום אחד. מול מודלים בלתי מוכרים היא גם הופיעה טוב, אם כי פחות מושלם מאשר בסביבת האימון שלה. האתגר הקשה ביותר הגיע מהתקפות של ניסוח מחדש: כאשר בינה מלאכותית נוספת ניסחה מחדש תקצירים שנוצרו על ידי מכונה כדי להישמע שונה תוך שמירה על המשמעות, הגילוי הפך לקשה משמעותית. בניסוח מחדש בעוצמה בינונית, חלק הטקסטים של הבינה שחלפו ללא זיהוי עלה לכמעט 30%, מה שמראה שגם גלאים מתקדמים יכולים להתבלבל על ידי הסוואה מכוונת.
מסקנות לגבי המדע והאמצעים לשמירתו
המחקר מראה שעבור עכשיו, תקצירים מדעיים שנוצרו על ידי בינה מלאכותית עדיין משאירים עקבות עדינים שמודל מתוכנן היטב יכול לזהות, גם כאשר אותו מודל קטן מספיק כדי לפעול על חומרה צנועה. זה הופך לסביר שמוציאים לאור, כנסים ואוניברסיטאות יסננו כמויות גדולות של הגשות בלי עלויות מחשוב עצומות. יחד עם זאת, הפגיעות לניסוח מחדש מדגישה שכלים כאלה אינם תרופת פלא. החוקרים טוענים שיש לשלב זיהוי טקסט של בינה מלאכותית עם אמצעי זהירות נוספים — כגון שיקול דעת עריכתי, בדיקות גניבה ספרותית ודרישות לשקיפות — כדי להגן על אמינות התקשורת המדעית ככל שמערכות ה‑AI ממשיכות להשתפר.
ציטוט: Zhang, C., Zhou, W. Efficient detection of AI-generated scientific abstracts with a lightweight transformer. Sci Rep 16, 4975 (2026). https://doi.org/10.1038/s41598-026-35203-3
מילות מפתח: זיהוי טקסט של בינה מלאכותית, תקצירים מדעיים, יושרה אקדמית, מודלים שפתיים גדולים, טקסט שנוצר על ידי מכונה