Clear Sky Science · he
חישוב ציון דמיון משפטים באמצעות למידה עמוקה היברידית עם דגש מיוחד על משפטי שלילה
מדוע משמעות המילה משנה להערכת ציון הוגנת
כאשר תלמידים עונים במילים שלהם, המחשבים המסייעים למורים להעריך את התשובות צריכים להבין יותר מאשר מילות מפתח משותפות. מילה קטנה כמו "לא" יכולה להפוך את משמעות המשפט, ואם מערכות אוטומטיות מפספסות את ההיפוך הזה, תלמידים עלולים להיות מדורגים בצורה לא הוגנת. מאמר זה מתמודד עם הבעיה על‑ידי עיצוב שיטה חדשה שבה מחשבים משווים בין המשמעויות של משפטים תוך תשומת לב מיוחדת לאופן שבו מילי שלילה משנות את המשמעות.
האתגר של מילים זעירות בעלות השפעה גדולה
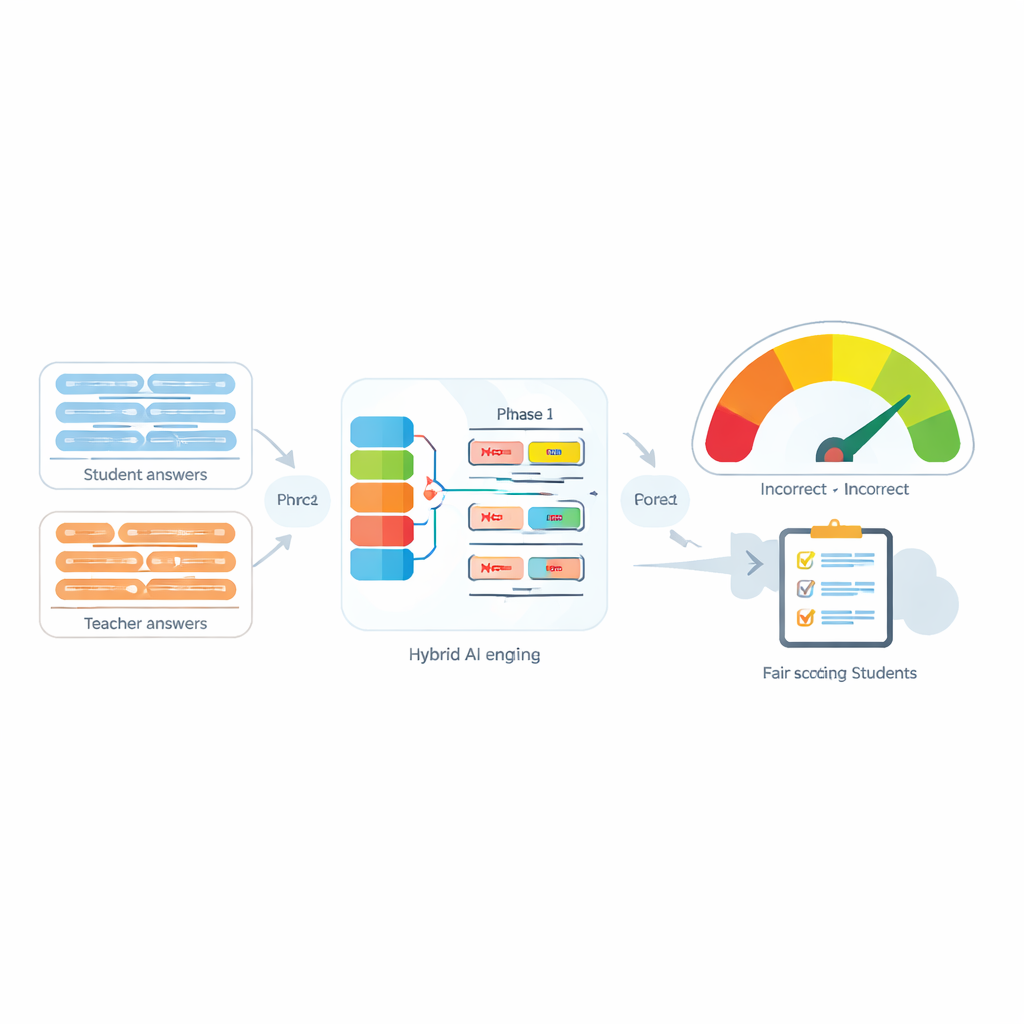
מערכות הערכה אוטומטיות משמשות יותר ויותר להקל על עומס העבודה של המורים על‑ידי השוואת תשובת התלמיד לתשובת המודל של המדריך. כלים מודרניים רבים עושים זאת על‑ידי המרת כל משפט ל"טביעת אצבע" מספרית ואז מדידת הקרבה בין טביעות אלה. כלים אלה עובדים די היטב כאשר אין שלילה, אך הם נכשלים לעתים קרובות כאשר מופיעות מילים כמו "לא", "מעולם" או "אין". לדוגמה, "המתודולוגיה מדויקת" ו"המתודולוגיה אינה מדויקת" עלולות להיראות למחשב דומות להפתיע, למרות שהן משמעותית מנוגדות. המחברים מראים שלא רק נוכחות השלילה חשובה, אלא גם כמה מילי שלילה קיימות ואיפה הן ממוקמות במשפט — כל אלו יכולים לשנות לחלוטין את הכוונה.
בניית מאגר נתונים שמלמד דקויות
כדי לאמן מערכת שמבינה באמת שלילה, המחברים נזקקו תחילה לנתונים המדגישים את המקרים הבעייתיים האלה. הם יצרו את "מאגר דמיון‑משפטי‑שלילה", המכיל 8,575 זוגות משפטים מארבעה תחומי מדעי המחשב: מערכות הפעלה, מסדי נתונים, רשתות מחשבים ולמידת מכונה. עבור כל זוג, בני אדם העניקו ציון דמיון שלקח בחשבון כבר את השלילה. המאגר גם רושם כמה מילי שלילה מופיעות בכל משפט ואיזה דפוס שלילה מופיע, כמו "לא" בודד, מספר זוגי או אי‑זוגי של שלילות, או מקרים מורכבים שבהם השלילה מתקשרת עם מילים מקשרות כמו "מפני ש" או "אבל". תיוג מפורט זה מעניק למודל רמזים ברורים לגבי האופן שבו השלילה מעצבת את המשמעות.
מנוע היברידי המאגד נקודות מבט רבות
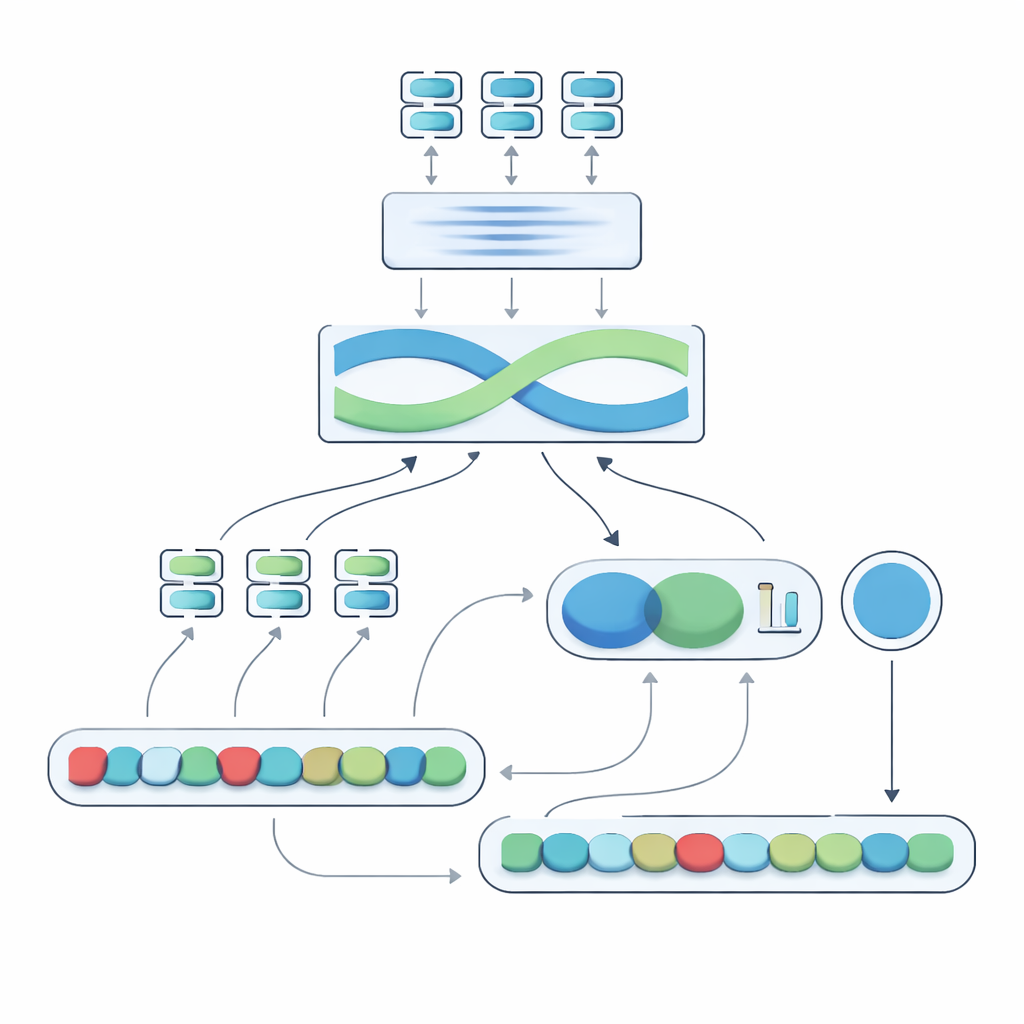
הליבה של המערכת המוצעת, אשר נקראת "מדד הדמיון המותאם לשלילה", היא מנוע בעל שתי שלבים. בשלב הראשון, המערכת מעבירה כל משפט דרך מספר מודלי שפה שונים, שכל אחד מהם לוכד היבטים מעט שונים של המשמעות. הפלטים שלהם נאחסנים יחד ולאחר מכן עוברים דרך רשת רקורנטית דו‑כיוונית שבוחנת את המשפט כמכלול, לוקחת בחשבון סדר מילים והקשר מקומי. זה מייצר תמצית קומפקטית של כל משפט שמותאמת טוב יותר לניסוחים עדינים, כולל מיקומן של מילי שלילה ביחס למילים אחרות.
ללמד את המודל להרגיש את ההיפוך של השלילה
בשלב השני המערכת משווה בין שתי תמציות המשפט ומוסיפה מידע מפורש על השלילה. היא בוחנת עד כמה התמציות שונות, עד כמה הן חופפות, ומשלבת אותן עם שלושה מאפיינים פשוטים: ההפרש במספר מילי השלילה, האם למשפטים יש ספירות שלילה אי‑זוגיות או זוגיות (שיכולות להפוך או לבטל משמעות שלילית), והאם השלילה מופיעה במיקומים המתאימים זה לזה. כל הרמזים האלה מתמזגים ברשת חיזוי קטנה שמוציאה ציון דמיון בטווח 0–100. מאומנת מקצה‑אל‑קצה על המאגר הממויין, התוצאה הזו נעשית רגישה לאופן שבו השלילה מעצבת משמעות במקום להתייחס ל"לא" כאל מילה רגילה נוספת.
כמה טוב המדד החדש עובד בפועל
כדי לבחון את הגישה הם ערכו הערכה הן על מאגר הנתונים המותאם שלהם והן על סט בדיקה מקובל של דמיון משפטי. בהשוואה לבסיסים חזקים מבוססי‑טרנספורמר שמשתמשים בשיטות סטנדרטיות, המדד החדש משיג שגיאת חיזוי נמוכה יותר ואיכות סיווג גבוהה בהרבה, עם F1 קרוב ל‑0.97. בדוגמאות שנבחרו בקפידה הוא נותן ציוני דמיון נמוכים כאשר השלילה הופכת בבירור את המשמעות וציונים גבוהים כאשר שלילה כפולה מבטלת למעשה את עצמה, בעוד שמודלים מתחרים נוטים עדיין להערכת יתר של הדמיון. מחקר אבולוציוני (ablation) מאשר ששני המרכיבים המרכזיים — השכבה הרקורנטית הרגישה לרצף והתכונות המפורשות של השלילה — חשובים לתוספת הביצועים הזו.
מה זה אומר עבור תלמידים וכלים עתידיים
לקורא שאינו מומחה, המסקנה ברורה: הדרך שבה אנו מביעים "לא" חשובה, ומכונות ניתנות ללימוד לזהות זאת. על‑ידי שילוב של מספר מודלי שפה, עיבוד קונטקסטואלי וספירות ומיקומים פשוטים של מילי שלילה, המדד המוצע מציע דרך הוגנת ומהימנה יותר לקבוע מתי שני משפטים באמת מביעים את אותה המשמעות. זה יכול לסייע למערכות הערכה אוטומטיות להימנע מטעויות חמורות, כמו להתייחס ל"אסור" כאילו הוא "מותר". למרות שהשיטה תובענית יותר חישובית ועדיין ממוקדת בתחומים טכניים, היא מצביעה על כלים עתידיים שיתפסו טוב יותר את הלוגיקה הדקה של השפה היומיומית, מה שיהפוך את טכנולוגיות השפה האוטומטיות לחכמות ואמינות יותר.
ציטוט: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
מילות מפתח: דמיון בין משפטים, שלילה בשפה, הערכה אוטומטית, עיבוד שפה טבעית, מודלי למידה עמוקה