Clear Sky Science · he
איתור IP בעל ביצועים גבוהים באמצעות האצת GPU לתמיכה בנתיביות סקלאבילית ויעילה ברשתות תקשורת מבוססות נתונים
מדוע כבישי האינטרנט המהירים חשובים
כל תמונה שאתם משתפים, כל וידאו שאתם משדרים או כל הודעה שאתם שולחים עוברת בלבול של צמתים דיגיטליים הנקראים נתבים. כל נתב חייב להחליט במהירות לאן לשלוח כל חבילה של נתונים בהמשך. כאשר השימוש העולמי באינטרנט מתפשט בקצב אדיר, ההחלטות האלה מתקבלות מיליארדי פעמים בשנייה, ואפילו עיכובים זעירים עלולים לגרום לדפדוף איטי או לעומסים ברשת. מאמר זה בוחן שיטה חדשה להאצת אחד השלבים הצורכי־זמן בתהליך זה על ידי ניצול כוח המקביליות העצום של מעבדי גרפיקה — אותם שבבים שמניעים משחקי וידאו ובינה מלאכותית — כדי לשמור על רשתות עתידיות מהירות וניתנות להרחבה.
ספר הכתובות הסמוי של האינטרנט
בלב כל נתב נמצא ספר כתובות ענק, הקרוי טבלת העברה, שממפה טווחי כתובות IP לקפיצה הבאה במסע. כשחבילה מגיעה, הנתב צריך למצוא איזו כניסה מתאימה ביותר ליעד החבילה, לפי כלל "התאמת הפרפיקס הארוך ביותר": מבין כל ההתאמות החלקיות הוא בוחר את המפורטת ביותר. שיטות תוכנה מסורתיות מאחסנות את הפרפיקסים במבני עץ והולכות בהם שלב אחר שלב. זה עובד, אך ככל שהטבלאות מתרחבות לעשרות או מאות אלפי רשומות, התהליך הופך לאיטי וצורף זיכרון רב יותר, במיוחד במעבדים מרכזיים רגילים המטפלים במגבלה של משימות בו זמנית.
להפוך שבב גרפיקה לשוטר תנועה
המחברים מציעים להעביר את משימת החיפוש הכבדה הזו ליחידת עיבוד גרפית (GPU), שבב שתוכנן להריץ אלפי משימות קטנות במקביל. העיצוב שלהם מתייחס ל‑GPU כעוזר למעבד הראשי. המעבד המרכזי מכין ומארגן את טבלת הנתיבים, ואז שולח גרסאות דחוסות של הנתונים ל‑GPU. כאשר חבילות מגיעות, כתובות היעד שלהן מפוצלות ונשלחות ל‑GPU, שם אלפי תהליכים מחפשים בו‑זמנית אחר ההתאמה הטובה ביותר. בעזרת ביצוע מאות או אלפי חיפושים במקביל, הנתב מצליח לעמוד בקצב הדרישות של תקשורת מודרנית מבוססת נתונים.
להקטין כתובות כדי להאיץ החלטות
תובנה מרכזית בעבודה היא שכתובות קצרות יותר מהירות יותר לחיפוש. במקום להשתמש בכתובות IP גולמיות, המחברים דוחסים אותן בשיטה ללא אובדן שנקראת קידוד הופמן, שמקצה קודים קצרים יותר לתבניות הכתובת השכיחות ביותר. זה מקטין את ממוצע מספר הסיביות הדרושות לייצוג כל כניסה, חותך גם בשימוש בזיכרון וגם בגובה מבנה החיפוש התחתון. הם מאחסנים אחר כך את הפרפיקסים בעץ "רב‑ביט" שבוחן מספר סיביות בכל שלב במקום רק אחת, ובכך מצמצם עוד את מספר השלבים הנדרשים. כדי להתאים את המבנה לחוזקות ה‑GPU, הם ממירים את העץ למערכים חד‑ממדיים פשוטים, ומחליפים מרדף מצביעים מורכב בחישובי אינדקס קבועים שאלפים של תהליכים יכולים לבצע ביעילות.
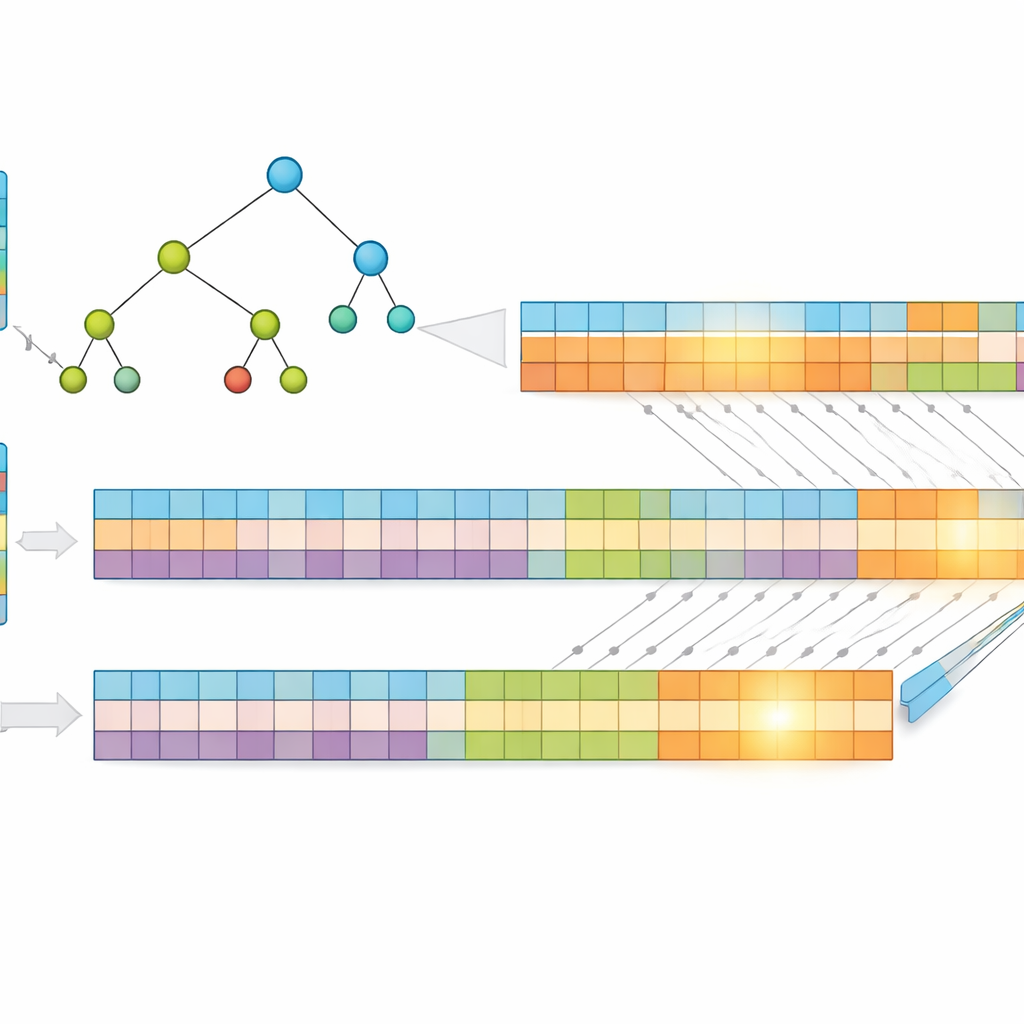
לפרק את הבעיה למקביליות עצומה
כדי לדחוף את הביצועים עוד יותר, החוקרים מחלקים כל כתובת דחוסה לשני חצאים שווים ובונים שני עצים נפרדים — אחד לחצי הראשון ואחד לחצי השני. כשחבילה מגיעה, ה‑GPU מחפש בשני העצים במקביל. כל חיפוש מחזיר קבוצה קטנה של התאמות אפשריות, והתשובה הסופית מתקבלת מהחיתוך של קבוצות אלו כדי למצוא את הפרפיקס המשותף והמפורט ביותר. מאחר שהעבודה מחולקת ומעובדת סימולטנית, הזמן הנדרש תלוי בעיקר באורך הפרפיקס המקסימלי ובמספר הסיביות הנבדקות בכל שלב, ולא במספר הרשומות שבטבלה. בדיקות על נתוני ניתוב אמיתיים מראות שעיצוב זה שומר על זמן חיפוש כמעט קבוע גם כאשר הטבלה מתרחבת.
מה מגלות הניסויים
הצוות השווה את השיטה המבוססת GPU שלו למגוון שיטות ידועות, כולל עצי בינארי קלאסיים, עצים דחוסים ותכניות GPU קודמות כמו hashing ועצי חיפוש בינאריים. על מאגרי נתוני ניתוב אמיתיים, המערכת שלהם סיפקה שיפורים דרמטיים: כ‑83–91 אחוז מהירה יותר משיטות עץ פופולריות המבוססות על מעבד מרכזי, וכ‑89–97 אחוז מהירה יותר משיטות GPU קודמות. הדחיסה גם קיצרה את צריכת הזיכרון בכ‑שליש בממוצע, מה שהקל על הלחץ על זיכרון המצוי על השבב ועזר לשמור על מבני החיפוש של ה‑GPU רדודים ויעילים. חשוב לציין כי ביצועי השיטה נשארו יציבים על פני גדלים שונים של טבלאות ניתוב, מה שמדגים את התאמתה לרשתות מתפתחות.
מה זה אומר למשתמש היומיומי
עבור הקורא הלא‑מומחה, התמצית היא שהמחברים מראים כיצד להפוך שבב גרפיקה לשוטר תנועה יעיל מאוד עבור נתוני אינטרנט, באמצעות כיווץ חכם וחלוקה של מידע הכתובות. על ידי שילוב דחיסה, סידורי עצים חכמים וחיפוש מקבילי מסיבי, הגישה שלהם מוצאת את הנתיב הטוב ביותר לכל חבילה הרבה יותר מהר מהרבה טכניקות קיימות, מבלי להאט כשהספרי כתובות של האינטרנט מתרחבים. בעוד שהעבודה מוצגת בעיקר עבור מערכת הכתובות של היום, רעיונות דומים ניתנים להרחבה למרחב כתובות גדול יותר בעתיד, ועוזרים לשמור על תגובתיות השירותים המקוונים ככל שצמאנו לנתונים ימשיך לגדול.
ציטוט: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
מילות מפתח: ניתוב באמצעות GPU, איתור IP, סקלאביליות רשת, העברת חבילות, חישוב מקבילי