Clear Sky Science · he
StatLLM: מאגר נתונים להערכת ביצועי מודלים שפתיים גדולים בניתוח סטטיסטי
מדוע זה חשוב למשתמשי נתונים ביום‑יום
ככל שכלים מבוססי בינה מלאכותית כמו עוזרים מבוססי שיחה משתלבים בעבודה היומיומית, יותר אנשים מבקשים מהם לבצע חישובים, להריץ ניסויים ולנתח נתונים. אך כשהבינה המלאכותית כותבת קוד למחקר סטטיסטי — למשל לבדיקת יעילות טיפול רפואי חדש או לחקירת נתוני ביצועי בתי ספר — כיצד נדע שהיא עשתה זאת נכון? מאמר זה מציג את StatLLM, מאגר ציבורי שנועד לבחון עד כמה מודלים שפתיים גדולים מתמודדים עם משימות ניתוח סטטיסטי אמיתיות, ומאפשר לחוקרים ולמיישמים תמונה ברורה יותר מתי ניתן לסמוך על קוד שנכתב על‑ידי בינה מלאכותית — ומתי יש לנקוט זהירות.
מערך מבחן חדש לקוד סטטיסטי שנכתב על‑ידי בינה
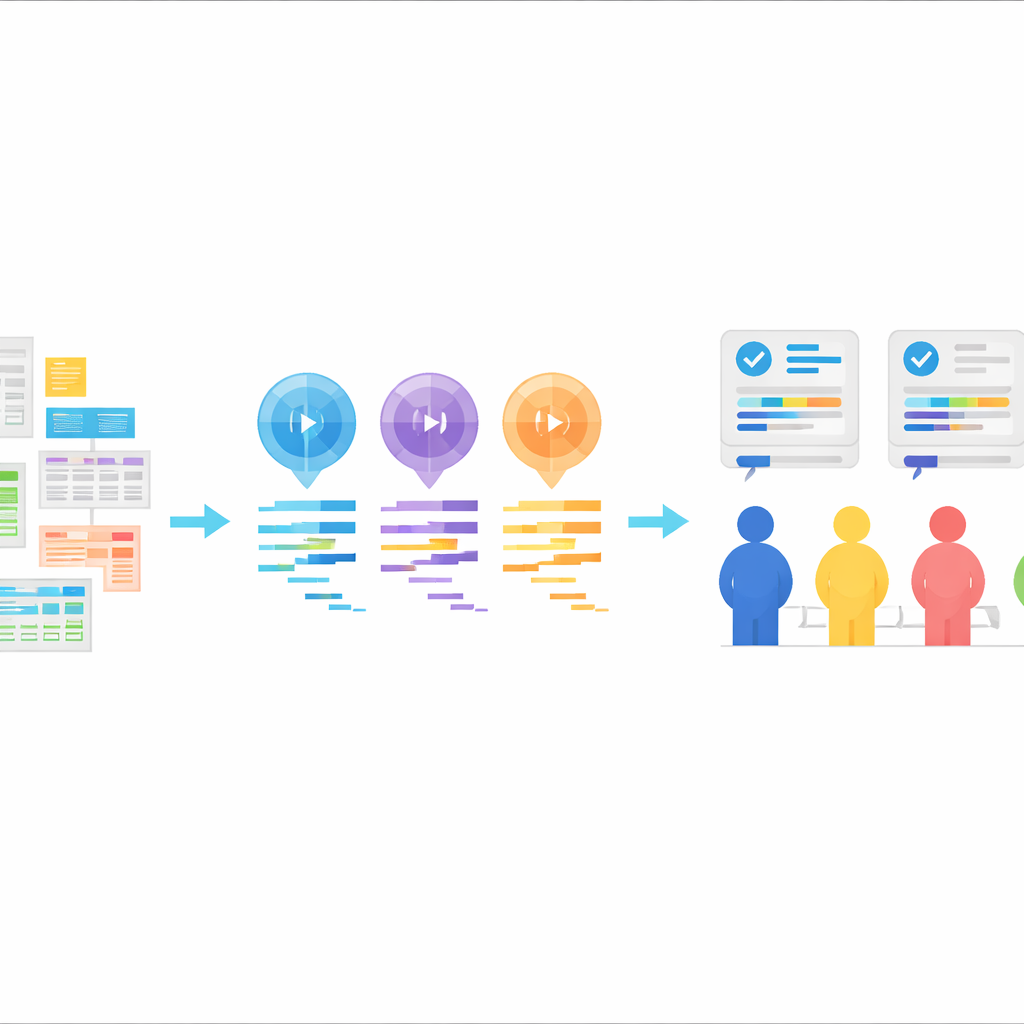
הליבה של StatLLM היא אוסף שנבנה בקפידה של 207 משימות ניתוח סטטיסטי, שהתבססו על 65 מאגרי נתונים אמיתיים מתחומים כמו חינוך, רפואה, עסקים, פיננסים, הנדסה וספורט. לכל משימה מצורף תיאור בשפה פשוטה, הסבר מפורט על מאגר הנתונים והמשתנים שבו, וקטע קוד SAS קצר שנכתב ונבדק על‑ידי מומחים אנושיים. המשימות מתפרשות על טווח היכולות שסטודנט טוב לתואר ראשון או מוסמך בסטטיסטיקה עשוי ללמוד: מסיכומי נתונים פשוטים וגרפים ועד רגרסיה, ניתוח הישרדות ושיטות מתקדמות יותר. זה מספק מבחן בר־מימוש, בסגנון אקדמי ותעשייתי, לבחינת האם כלים של בינה מלאכותית יכולים להבין שאלות מעשיות ולתרגם אותן לצעדי ניתוח תקפים.
לתת לבינה לכתוב את הקוד — ואז לדרג את עבודתה
בהתבסס על המשימות הללו, המחברים ביקשו משלושה מודלים שפתיים גדולים — GPT‑3.5, GPT‑4 ו‑Llama‑3.1 70B — לייצר קוד SAS. כל מודל קיבל את אותם מרכיבים: תיאור המשימה, תיאור מאגר הנתונים, קובץ הנתונים עצמו והנחיה מפורשת להפיק קוד SAS. המודלים הופעלו במצב "אפס דוגמאות" (zero‑shot), כלומר לא הוצגו להם דוגמאות של קוד SAS תקין מראש. התגובות שלהם נוקו כך שנשאר רק הקוד, ללא הסברים. סידור זה מדמה דפוס נפוץ בעולם האמיתי: משתמש מסביר מה הוא רוצה, הבינה המלאכותית מחזירה קוד, והקוד מריץ בחבילת סטטיסטיקה.
מומחים אנושיים כתקן זהב
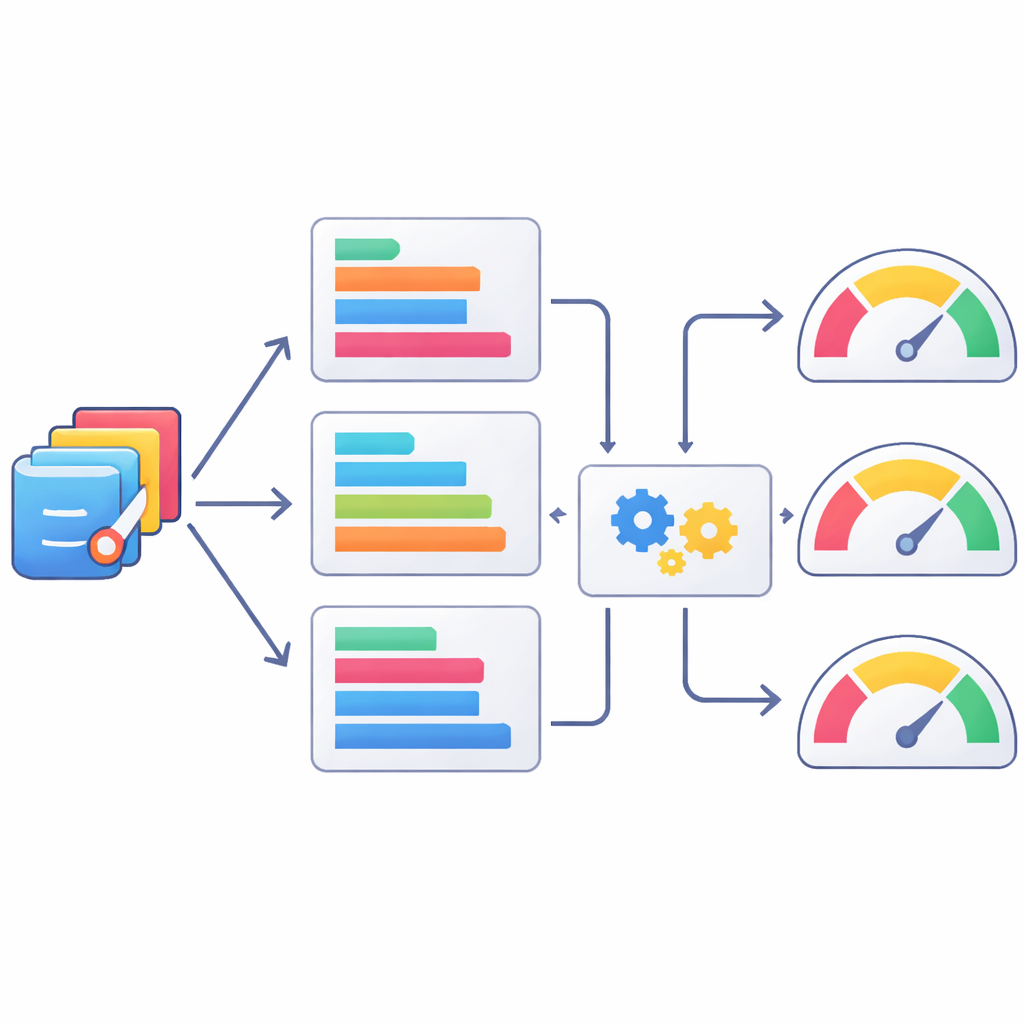
כדי להעריך עד כמה הקוד שנכתב על‑ידי הבינה טוב באמת, הצוות ארגן סקירה אנושית מחמירה. תשעה משתמשי SAS מנוסים התחלקו לשלוש קבוצות, כאשר כל קבוצה התמקדה בחלק אחר של הביצועים: האם הקוד עצמו נכון והקריא מבחינה לוגית, האם הוא רץ בפועל ללא שגיאות, והאם הפלט שנוצר עונה על השאלה המקורית בצורה ברורה ומדויקת. עבור כל משימה, תוכניות ה‑SAS מהשלושה נערבבו כך שהמדרגים לא ידעו איזה מודל הפיק את הקוד. ניקודים הוענקו על סולם חמש‑נקודות וצוינו לציון כולל, מה שסיפק תמונה מורכבת של חוזקות וחולשות במאות זוגות מודל‑משימה. דירוגי המומחים הללו מצורפים כעת לצד כל הקוד והמשימות במאגר StatLLM.
ללמד מכונות לשפוט קוד כפי שאנשים שופטים
מכיוון שסקר אנושי הוא איטי ויקר, המחברים בדקו גם עד כמה מדדי טקסט אוטומטיים יכולים לשמש כשופטים משוערים של איכות קוד סטטיסטי. הם השוו תוכניות SAS שיוצרו על‑ידי בינה לגרסאות שאומתו על‑ידי בני אדם בעזרת מערך מדדי עיבוד שפה טבעית ידועים, ואז בדקו כיצד מדדים אלה מתיישבים עם דירוגי האנשים. כמה מדדים, כמו וריאנטים של ציון ROUGE שעוקבים אחר חפיפות ברצפים קצרים של טוקנים, הראו מתאם טוב יותר עם שיפוטי האנשים מאשר אחרים, אך כולם היו רק מותאמים במידה בינונית. הצוות התקדם צעד נוסף ואימן מודלים של למידת מכונה לחזות ניקודים אנושיים משילובים של מדדים אלה. שיטות כמו XGBoost שיפרו את ההתאמה לניקודי האנשים, אך עדיין לא הגיעו לתיאור מדויק של שיפוט המומחים, מה שמדגיש שמדדים אוטומטיים הם לכל היותר תחליפים חלקיים.
בנייה לעבר כלי סטטיסטיקה מונעי בינה בעתיד
מעבר להערכת ביצועים, המחברים מראים כיצד StatLLM יכול לתמוך בכלים וכיווני מחקר חדשים. מכיוון שכל משימה מתוארת במונחים כלליים, אותן בעיות יכולות לשמש לבחינת יצירת קוד בשפות אחרות כמו R או Python, או אפילו לשילוב קוד ממספר שפות. המאמר מדגיש גישות אנסמבל שיכולות לערבב פתרונות שונים שנוצרו על‑ידי בינה לשם אמינות גבוהה יותר, ומדגים אפליקציית פרוטוטיפ ב‑R Shiny שבה משתמשים מעלים מאגר נתונים ותיאור משימה, ומערכת בינה מלאכותית מייצרת ומריצה קוד R באופן אוטומטי. StatLLM מספק גם פלטפורמה לעיצוב ובחינת תוכנות סטטיסטיות דור הבא שמבינות הוראות בשפה טבעית תוך שמירה על סטנדרטים ברורים ומדידים.
מה זה אומר לשימוש בבינה בניתוח נתונים
למשתמשים שאינם מומחים, המסקנה העיקרית היא שבינה מלאכותית כבר מסוגלת לכתוב קטעי קוד סטטיסטיים קצרים — אך האמינות רחוקה מלהיות מובטחת, במיוחד במשימות שעולות על דוגמאות פשוטות. StatLLM מציע דרך שקופה וחוזרת לבחינת ביצועי מודלים שונים, לשיפור בדיקות אוטומטיות של עבודתם ולתכנון כלי ניתוח נתונים בטוחים ועמידים יותר. עם הופעתם של דגמי שפה חדשים, ניתן לחברם למאגר החי הזה, ולשמור על המיוחדיות של התחום לגבי מה שבינה יכולה ולא יכולה עדיין לעשות בעבודה סטטיסטית מהותית.
ציטוט: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
מילות מפתח: מודלים שפתיים גדולים, ניתוח סטטיסטי, הערכת קוד, מאגד בוחן, תכנות SAS