Clear Sky Science · he
מערכת הנתונים Kymata Soto לשפה: מאגר אלקטרו‑מגנטואנצפלוגרפי לעיבוד דיבור טבעי
האזנה לאופן שבו המוח שומע שיחות אמיתיות
הרוב המכריע של מה שאנו אומרים ושומעים ביום‑יום הוא שיחה מזדמנת, לא מילים בודדות או משפטים שנקראו בקפידה. עם זאת, רוב המחקר על שפה במוח הסתמך על מטלות מלאכותיות. מאגר הנתונים Kymata Soto משנה זאת על ידי אספקת אוסף עשיר ופתוח של הקלטות מוח של אנשים שהאזינו פשוט לשיחות רדיו סוערות באנגלית וברוסית, ומעניק למדענים חלון חזק להבנת האופן שבו המוח מעבד דיבור טבעי.
ספרייה חדשה של תגובות מוח לשיחה אמיתית
הפרויקט מאחד שתי שיטות מתקדמות להקלטת מוח — אלקטרואנצפלוגרפיה (EEG) ומגנטואנצפלוגרפיה (MEG) — מ‑35 מבוגרים: 20 דוברי אנגלית ילידים ו‑15 דוברי רוסית ילידים. בעוד הם ישבו בשקט והאזינו לכ־שש וחצי דקות של שיחת רדיו בשפת אם שלהם, פעילות מוחם הוקלטה אלף פעמים בשנייה. כל משתתף שמע את אותו קטע מספר פעמים, מה שאיפשר לחוקרים לממוצע על־פני החזרות ולבודד את התגובות האמינות של המוח מרעש הרקע. התוצאה היא רישום מפורט, מקובע בזמן, של האופן שבו המוח מגיב, רגע אחרי רגע, ככל שאנשים עוקבים אחר שיחה המתפתחת.

שיחות על גלידות וקפה
במקום להשתמש בסיפורים קלאסיים או משפטים מלאכותיים, הצוות בחר נושאים מרתקים אך יומיומיים: היסטוריית הגלידה למאזיני האנגלית והיסטוריית הקפה הקולומביאני למאזיני הרוסית. שתי ההקלטות נלקחו מדיוני סטודיו של ה‑BBC הכוללים שלושה דוברים (שני גברים ואישה אחת). השיחות נערכו לכ־400 שניות והושמעו ברמות נוחות לאוזן דרך אטמי אוזניים. לאחר כל חזרה ענו המשתתפים על שאלה או שתיים של בחירה מרובה לגבי התוכן — מספיק כדי לוודא שהם ערים ועוקבים אחר הסיפור, לא כדי לבדוק אותם בקפדנות.
להשאיר את העיניים עסוקות אך המחשבות על הקול
בזמן שמאזינים הקשיבו, הם הביטו בצלב מרכזי על המסך. סביבו, ענני נקודות צבעוניות שטו ושינו את צבען באופן שנראה אקראי. נקודות נעות אלו שימשו שתי מטרות: הן עזרו לשמור על מבט יציב של הנבדקים, דבר שמשפר את איכות הנתונים, והן יצרו דפוסי תנועה וצבע ויזואליים מבוקרים שחוקרים אחרים יוכלו לנתח מאוחר יותר. חשוב: הנקודות לא היו מסונכרנות עם תכני הדיבור, כך שהן לא 'אילוסטרטו' את הסיפור או הוסיפו משמעות, אך הן סיפקו רקע ויזואלי עקבי שניתן לחקור לצד הקולות.
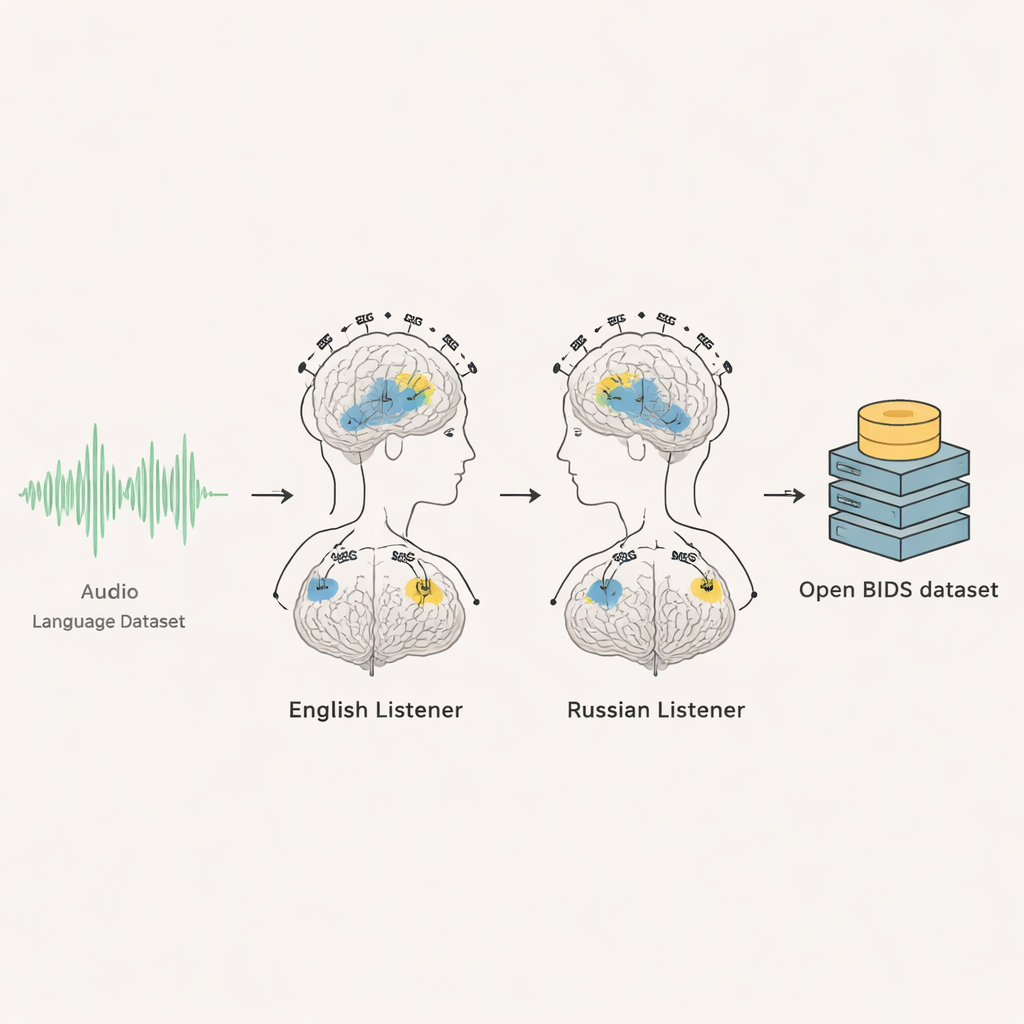
מאותות מוח גולמיים לנתונים מוכנים לשימוש
החוקרים תיעדו בקפידה כל חלק בניסוי וארגנו את מאגר הנתונים לפי תקן בינלאומי לנתוני מוח שנקרא BIDS. עבור כל מתנדב קיימות הקלטות EEG ו‑MEG גולמיות, סימני תזמון להתחלת האודיו, אירועים ויזואליים שנרשמו שנייה אחרי שנייה, וקטעי תרגול. הצוות מספק גם את קבצי האודיו המקוריים, תמלולים מלאים ותזמון מדויק של תחילת כל מילה ואפילו של כל פונמה בנפרד. הם כוללים סקריפטים כך שאחרים יוכלו לשחזר אוטומטית את קטעי האודיו המדויקים שנשמעו. לקבוצת האנגלית משותפים סריקות MRI מעוצמות שם כך שניתן למפות תגובות מוח לאנטומיה המוחית האישית; עבור קבוצת הרוסית, ההסכמה לא אפשרה שיתוף תמונות MRI, ולכן מומלץ למשתמשים להיעזר בתבניות מוח ממוצעות סטנדרטיות.
בדיקה שהאותות הגיוניים
כדי לוודא שהנתונים מהימנים מבחינה מדעית, המחברים ערכו ניתוחי אימות שהתמקדו באיך המוח עוקב אחרי שינויים בעוצמת הקול לאורך זמן. הם המירו את האודיו למספר תיאורים מתמטיים של "עוצמה משתנה בזמן" ואז בחנו היכן ומתי תגובות המוח תיאמו את דפוסי העוצמה הללו. הן עבור מאזיני האנגלית והן עבור מתנדבי הרוסית הראתה המוח דפוסי תזמון דומים, תואמים למה שתואר בעבודות קודמות. ההסכמה הזו בין שפות ובין ממצאים קודמים היא אינדיקציה חזקה שההקלטות נקיות, אמינות ומוכנות לשימוש של חוקרים אחרים.
מדוע הדבר חשוב למחקר עתידי על מוח ושפה
לציבור הלא‑מומחה, המסקנה העיקרית היא שמאגר נתונים זה הוא משאב ציבורי חדש המאפשר לצוותי מחקר שונים לחקור כיצד דיבור ספונטני ומציאותי מעובד במוח. היותו פתוח, מתועד היטב ומוקלט בשתי שפות שונות מאפשר לתמוך בפרויקטים הנעים משאלות בסיסיות על אופן הבנת שיחה, דרך השוואות בין שפות, ועד למאמצים שאפתניים לפענח דיבור ישירות מפעילות מוחית. בקצרה, מאגר הנתונים Kymata Soto פחות עוסק במענה על שאלה יחידה ויותר במתן יסוד משותף, איכותי, לחקירה מדעית של האופן שבו המוחות שלנו מבינים את השיחות שממלאות את חיי היומיום שלנו.
ציטוט: Yang, C., Parish, O., Klimovich-Gray, A. et al. Kymata Soto Language Dataset: an electro-magnetoencephalographic dataset for natural speech processing. Sci Data 13, 254 (2026). https://doi.org/10.1038/s41597-026-06579-8
מילות מפתח: מוח ושפה, תפיסת דיבור, EEG MEG, שיחה טבעית, נתוני נוירו‑הדמיה פתוחים