Clear Sky Science · he
אמינות של מודלי שפה גדולים כעוזרים רפואיים לציבור הרחב: מחקר מקרי אקראי שנרשם מראש
למה הטלפון שלך אולי לא הרופא הטוב ביותר להיוועצות ראשונית
יותר ויותר אנשים פונים כיום לצ׳אטבוטים מבוססי בינה מלאכותית כשמרגישים רע, בתקווה לקבל תשובות מהירות האם צריך לדאוג, מה המשמעות של תסמינים מסוימים והאם לפנות לבי"ח. המחקר הזה שואל שאלה פשוטה אך דחופה: אם אנשים רגילים ישתמשו במודלי שפה רבי־עוצמה כעוזרים רפואיים בבית, האם הם אכן יקבלו החלטות בריאותיות טובות יותר — או שהטכנולוגיה תעניק תחושת ביטחון שווא?
בדיקת מכונות חכמות בתרחישים בסגנון מציאותי
כדי לבדוק זאת, חוקרים בבריטניה תכננו עשר סיפורי מקרה רפואיים מציאותיים, כמו כאב ראש חזק פתאומי או קושי בנשימה, בהתבסס על מצבים שכיחים שרבים מאיתנו עלולים להתמודד מולם. צוות רופאים מנוסה הסכים על ה"צעד הבא" הטוב ביותר לכל סיפור — החל משהייה בבית וטיפול עצמי ועד קריאה לאמבולנס — וברשום את המחלות המרכזיות שאדם זהיר צריך לשקול. לאחר מכן 1,298 מבוגרים מכל רחבי בריטניה הוקצו באופן אקראי לאחת מארבע אפשרויות: שימוש באחד משלושת הצ׳אטבוטים המובילים, או שימוש במה שהיו נוטים להשתמש בו בדרך כלל בבית, כמו חיפוש באינטרנט או ניסיון אישי.
כיצד אנשים ומכונות הופיעו — בנפרד וביחד
כשהמודלים שנסו מבחן בנפרד, בכך שהוזנו להם תיאורי המקרה המלאים וביקשו מהם ישירות אבחנה והמלצת פעולה, הם הופיעו בביצועים מרשימים. בין שלוש המערכות, הן הציעו נכון לפחות מצב רפואי רלוונטי בכ־95% מהמקרים ובחרו ברמת הדחיפות המתאימה יותר ממחצית הפעמים — הרבה יותר מטעות מקרית. על הנייר, המערכות האלו נראו כמועמדות חזקות להנחות מטופלים מודאגים.
כשהייעוץ של ה-AI פוגש אנשים אמיתיים
אבל ברגע שמשתמשים יום־יומיים נכנסו לתמונה, התמונה השתנתה. המשתתפים שהשתמשו ב־AI לא היו מדויקים יותר מקבוצת הביקורת בבחירת הצעד הבא, ובו־זמנית היו גרועים יותר בזיהוי מצבים נסיבתיים רלוונטיים. אנשים בקבוצת הלא־AI היו בסביבות 1.8 פעמים סבירות גבוהה יותר לזהות מצב נכון לעומת אלה שהשתמשו בצ׳אטבוטים. ברוב הקבוצות המשתתפים העריכו פחות מדי את חומרת המצב. במילים אחרות, גישה למודל שפה מתקדם לא סייעה לאנשים להבין טוב יותר את התסמינים שלהם, ולא הניעה אותם בבירור לבחירות בטוחות יותר.
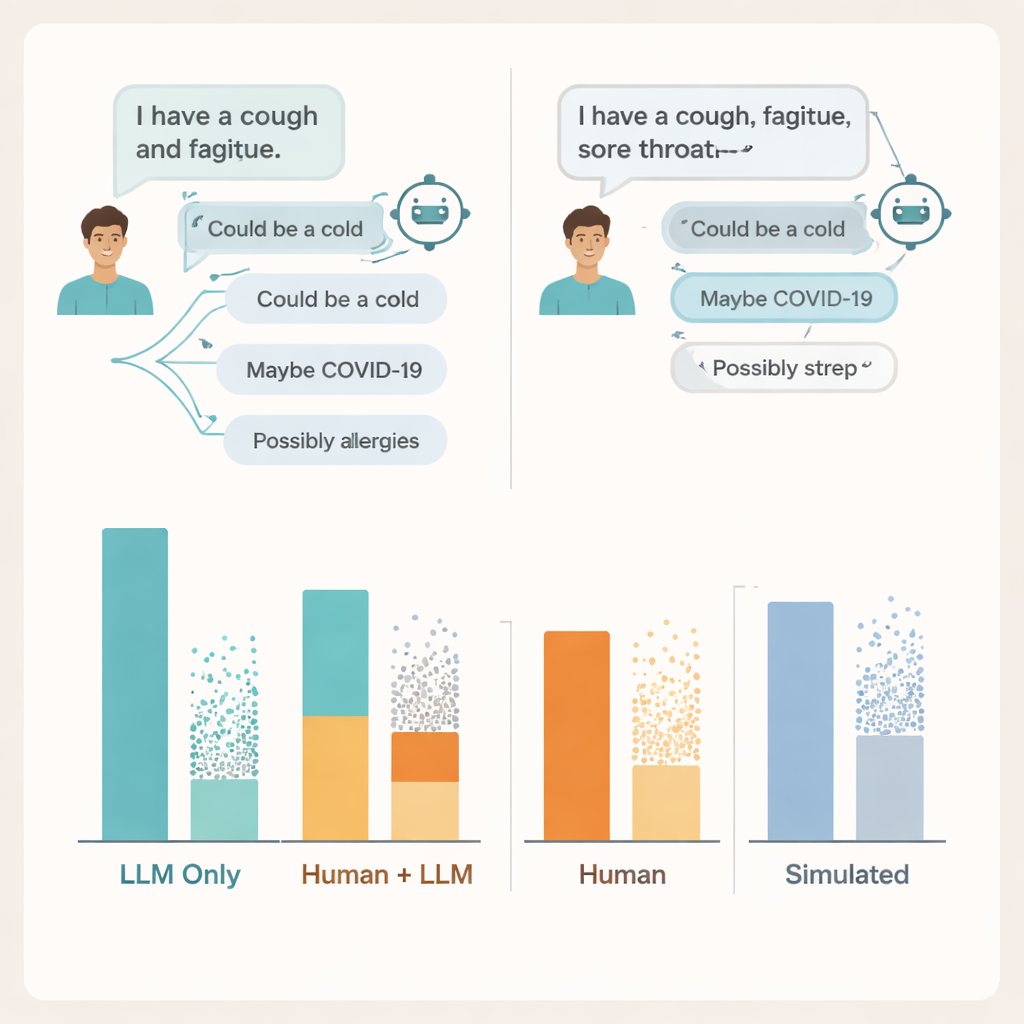
איפה השיחה קורסת
כדי להבין מדוע, החוקרים חקרו את תמלילי השיחות בפועל. הם מצאו בעיות משני צדי השיחה. משתמשים רבים לא שיתפו מספיק פרטים על תסמיניהם כדי שה־AI יוכל לתת ייעוץ מוסמך — בדומה לכך שמטופלים לפעמים משמיטים מידע חשוב כשמדברים עם רופא. המודלים עצמם לעתים קרובות הזכירו לפחות מצב רלוונטי אחד, אך גם הוסיפו מספר אפשרויות שגויות או מבליטות, ומשתמשים נאבקו להבחין אילו הצעות חשובות. במקרים מסוימים, תיאורי תסמינים כמעט זהים הובילו להמלצות שונות באופן חד מאותו מודל, מה שהקשה על אנשים להבין מתי ניתן לסמוך על מה שהם ראו על המסך.
מדוע מבחנים סטנדרטיים מפספסים את הסיכונים האמיתיים
הצוות השוותה גם את התוצאות האלו לשתי שיטות פופולריות להערכת מיכון רפואי: שאלות בבחינת רב־ברירה ושיחות "מטופל" מדומות המופעלות בין שני מודלים. בשתי השיטות המערכות שוב נראו חזקות, והגיעו או עברו ציונים מקובלים בבחינות בסגנון בחינה ועשו עבודה טובה יותר עם מטופלים מדומים מאשר עם מטופלים אמיתיים. ואולם ציונים גבוהים במבחנים ושיחות מדומות מלוטשות לא עמדו בקנה אחד עם האופן שבו אנשים אמיתיים התמודדו כששתמשו באותם כלים. המדדים שבודקים ידע בניכוס, כותבים המחברים, מפספסים את טבען המבולגן ושברירי של אינטראקציות אנוש־מכונה במציאות.
מה המשמעות עבור מטופלים ומערכות בריאות
כרגע, מסכם המחקר, מודלי שפה כלל־תכליתיים עכשוויים אינם מוכנים לפעול כיועצים קדמיים ללא השגחה לציבור. ברור שהם מכילים כמות רבה של ידע רפואי, אך ידע זה אינו מתורגם אוטומטית לבחירות בטוחות יותר כאשר אנשים מודאגים מקלידים שאלות חלקיות ומבולבלות בבית. כדי שה־AI יהיה מועיל באמת בסביבות בעלות משקל גבוה כמו בריאות — יידרש יותר מציונים טובים במבחנים: עיצוב קפדני, בדיקות עם משתמשים אמיתיים ומגוונים ובקרות מחמירות על האופן שבו מידע נאסף, מוסבר ומהימנותו בהדדיות של השיחה.
ציטוט: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
מילות מפתח: צ׳אטבוטים רפואיים, אבחון עצמי, בינה מלאכותית בתחום הבריאות, קבלת החלטות של מטופלים, מודלים של שפה גדולים