Clear Sky Science · he
סינתזה של ספרות מדעית באמצעות דגמי שפה מועשרים בשליפה
מדוע קשה להתעדכן במדע
כל שנה מתפרסמות ברשת מיליוני מאמרים מדעיים חדשים. אין חוקר אנושי שיכול לקרוא את כולם, ועדיין טיפולים רפואיים חשובים, תובנות אקלימיות ופריצות דרך טכנולוגיות עלולים להסתתר בתוך שיטפון המידע הזה. מאמר זה בוחן האם מערכות בינה מלאכותית מתקדמות יכולות לעזור לחוקרים לחפש באוקיינוס המחקרים הזה ולארוג מהם סיכומים ברורים ואמינים—מבלי להמציא נתונים.
עוזר מחקר חדש מסוג אחר
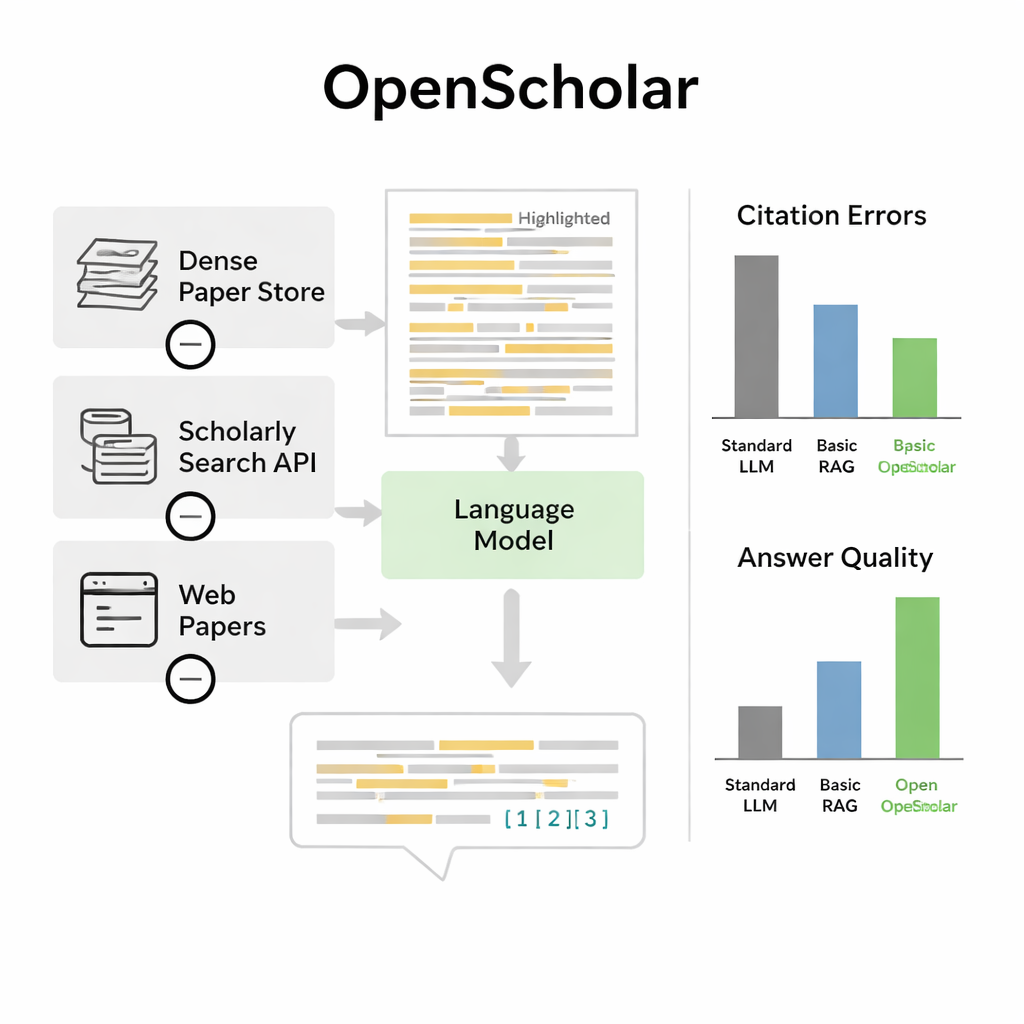
המחברים מציגים את OpenScholar, מערכת בינה מלאכותית שנבנתה במיוחד כדי לקרוא ולסנתז ספרות מדעית. בשונה מתוכנות שיחה כלליות, OpenScholar מחוברת באופן הדוק למסד נתונים פתוח ענק של כ־45 מיליון מאמרים, המכונה OpenScholar DataStore. כאשר חוקר שואל שאלה—למשל כיצד לקרר ננו־חלקיקיםlevitated או אילו שיטות עובדות היטב להדמיית מוח—המערכת תחפש תחילה במסד זה קטעים רלוונטיים, ולאחר מכן תנסח תשובה עם ציטוטים בשורה, בדומה למאמר סקירה שכתב אדם. היא חוזרת על התהליך מספר פעמים, מבקרת ומשפרת את הנוסחים שלה כדי לשפר בהירות, שלמות ואיכות הציטוטים.
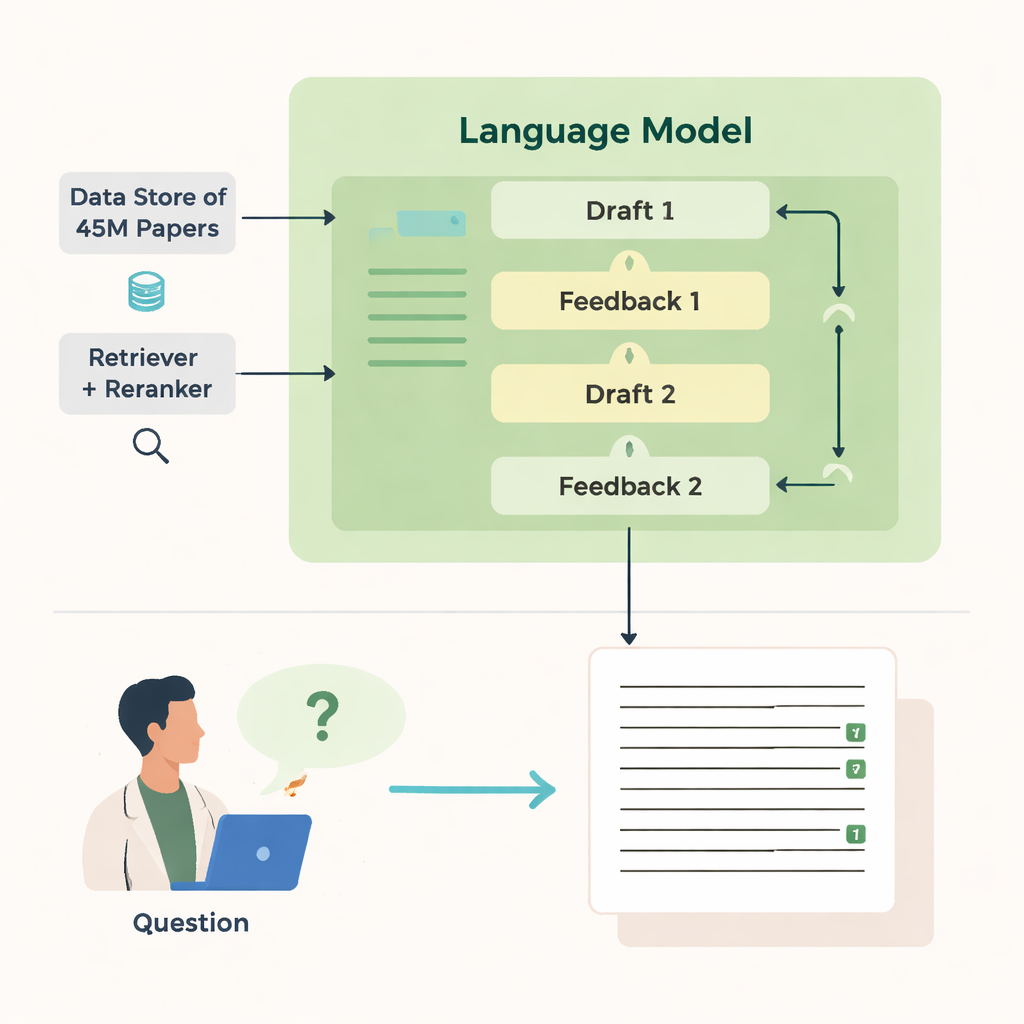
איך היא מחפשת וכותבת
כוחו של OpenScholar נובע ממספר רכיבים מתואמים. מודול "מושך" סורק הטבעות טקסט מחושבות מראש ממיליוני מאמרים כדי למצוא קטעים מבטיחים, בעוד "מדרג מחדש" (reranker) מסדר את הקטעים כדי למקד את תשומת הלב באלו הרלוונטיים ביותר. דגם השפה משתמש אחר כך בעדויות אלה ליצירת תשובה ארוכה עם הפניות ממוספרות. לאחר טיוטה ראשונה, המודל מייצר משוב לעצמו—מצביע על נקודות מבט חסרות, מבנה חלש או עדות דלה—וכאשר נדרש מפעיל חיפושים ממוקדים נוספים. הוא כותב מחדש את התשובה, משלב מאמרים חדשים ומתאים את הציטוטים. בדיקה סופית מוודאת שההצהרות שזקוקות לתמיכה מגובות על ידי לפחות מקור שנשלף.
בדיקת טענות וציטוטים
כדי לבדוק האם OpenScholar אכן מסייע, המחברים יצרו את ScholarQABench, מבחן גדול שתוכנן לחקות שאלות סקירת ספרות אמיתיות. הוא כולל כמעט 3,000 שאלות שנכתבו על ידי מומחים ומאות תשובות ארוכות בתחומי מדעי המחשב, פיזיקה, מדעי המוח וביומדיצינה. חשוב, שאלות אלה בדר"כ דורשות קריאה במספר מאמרים, לא רק תקציר אחד. הצוות העריך מערכות על פני צירים מרובים: נכונות עובדתית, עד כמה התשובות כיסו נקודות מפתח, בהירות הכתיבה וכמה באופן מדויק הציטוטים שיקפו את המאמרים הבסיסיים. הם שילבו בדיקות אוטומטיות עם דירוגים מפורטים של מומחים בדרגת דוקטורט שהשוו תשובות שנוצרו על ידי בינה מלאכותית לתשובות שנכתבו על ידי בני אדם.
עקיפה של צ’אטבוטים חזקים והתקרבות לרמת מומחים
במבחן זה OpenScholar השיג תוצאות טובות יותר הן ממודלי שפה סטנדרטיים והן מכלים מוקדמים שפשוט הוסיפו שליפה על גבי צ’אטבוט כללי. גרסה קומפקטית של שמונה מיליארד פרמטרים, שאומנה כולה על נתונים פתוחים, ביצעה טוב יותר במשימת סינתזה תובענית על פני מספר מאמרים לעומת GPT‑4o ומערכת מתחרה בשם PaperQA2, למרות אלו הסתמכו על דגמים פרטיים גדולים יותר. ממצא בולט הוא תדירות ההזיות של ציטוטים אצל צ’אטבוטים רגילים: ב־78–90 אחוז מהמקרים, רשימות הציטוטים שלהם כללו מאמרים שלא קיימים או שלא תמכו בטענות. לעומת זאת, דיוק הציטוטים של OpenScholar התקרב לזה של מומחים אנושיים. כאשר מומחים השוו תשובות ישירות, הם העדיפו את OpenScholar‑8B על פני תשובות שנכתבו על ידי מומחים בערך במחצית מהמקרים, ואת צינור OpenScholar המבוסס על GPT‑4o בערך ב־70 אחוז מהמקרים, בעיקר משום שהאינטליגנציה הכילה יותר מחקרים רלוונטיים וארגנה אותם בצורה ברורה.
מגבלות ושיפורים עתידיים
למרות השיפורים הללו, המחברים מדגישים כי OpenScholar אינה תחליף לחוקרים. המערכת עדיין עלולה לפספס את המאמרים המייצגים ביותר, להדגיש יתר על המידה עבודות פחות חשובות או להכניס שגיאות עובדתיות, במיוחד בדגמים קומפקטיים יותר. גם למבחן עצמו קיימים מגבלות: הוא מתמקד בעיקר במדעי המחשב, ביומד ובפיזיקה, והשאלות שמסומנות בקפידה עדיין מעטות יחסית כי זמן המומחים יקר. ההערכות גם מתקשות ללכוד במלואן תכונות עדינות יותר, כגון האם הציטוטים מדגישים עבודה באמת יסודית או האם תשובה תדריך בפועל ניסוי חדש.
מה זה אומר למדע היומיומי
ללא־מומחים, המסקנה המרכזית היא שכלים מבוססי בינה מלאכותית שעוצבו בקפידה כבר יכולים לעזור לחוקרים לנווט בספרות המדעית ביעילות רבה יותר, בתנאי שהם מקושרים לנתונים אמיתיים ומוחזקים לסטנדרטים מחמירים של עדות ושקיפות. OpenScholar מראה כי כאשר מערכת AI נבנית מהיסוד כדי לשלוף, לבדוק ולצטט מאמרים אמיתיים—וכאשר ביצועיה נבדקים מול מומחים אנושיים—היא יכולה לייצר סיכומי ספרות שאינם רק קריאים, אלא גם ניתנים לאימות. למעשה, כלים כאלה עשויים לשחרר חוקרים להתמקד更多 בתכנון ניסויים ובפירוש תוצאות, בעוד שבני אדם נשארים אחראים להערכת מה נכון ומה חשוב.
ציטוט: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
מילות מפתח: סקירת ספרות מדעית, דגמי שפה מועשרים בשליפה, OpenScholar, דיוק הציטוטים, כלי מחקר מבוססי בינה מלאכותית