Clear Sky Science · he
שיפור חיזוי ציוני פולי-גניים עבור קבוצות שאינן מיוצגות באמצעות לימוד העברה
למה ציון הסיכון הגנטי שלך עשוי שלא לעבוד עבורך
”ציוני סיכון“ גנטיים משמשים יותר ויותר להערכת הסבירות שאדם יפתח מחלות נפוצות כמו סוכרת, מחלות לב או לחץ דם גבוה. עם זאת, רוב הציונים הללו נבנו מתוך נתוני DNA של אנשים ממוצא אירופי. כתוצאה, הם לעתים קרובות מנבאים באופן לקוי לאנשים מרקעים אחרים, מה שמעורר דאגות לגבי הוגנות ושימושיות ברפואה היומיומית. המחקר שואל שאלה פשוטה: האם נוכל reuse (לנצל מחדש) את מה שלמדנו ממערכי נתונים אירופיים גדולים כדי לבנות ציונים גנטיים טובים והוגנים יותר לקבוצות שאינן מיוצגות — מבלי לחלוק את נתוני הגולמים של אף אחד?
ממיליוני סמני DNA לציון סיכון יחיד
ציון פולי-גני הוא כמו דוח ציון שמחבר את ההשפעות הקטנות של סמנים גנטיים רבים המפוזרים לאורך הגנום. לכל סמן מקצהים משקל המשקף כמה חזק הוא קשור לתכונה, בהתבסס על מחקרים גנטיים רחבי היקף. כאשר המחקרים הללו כוללים בעיקר אירופים, הציון שנוצר נוטה לעבוד הכי טוב בקרב אירופים. הבדלים ברקע הגנטי — עד כמה וריאנטים מסוימים נפוצים וכיצד הם נוטים לעבור יחד — גורמים לכך שהמשקלים אותן פעמים לא יעבדו היטב באוכלוסיות אפרו-אמריקאיות, היספניות ואחרות. איסוף מערכי נתונים גדולים באותו קנה מידה לכל קבוצה יקר ואיטי, לכן המחברים פנו לאסטרטגיית למידת מכונה שנקראת למידת העברה: במקום להתחיל מאפס בכל אוכלוסייה, הם מדייקים מודל קיים שאומן במקום אחר.
איך לשאול ידע בלי לשתף נתוני גולמים
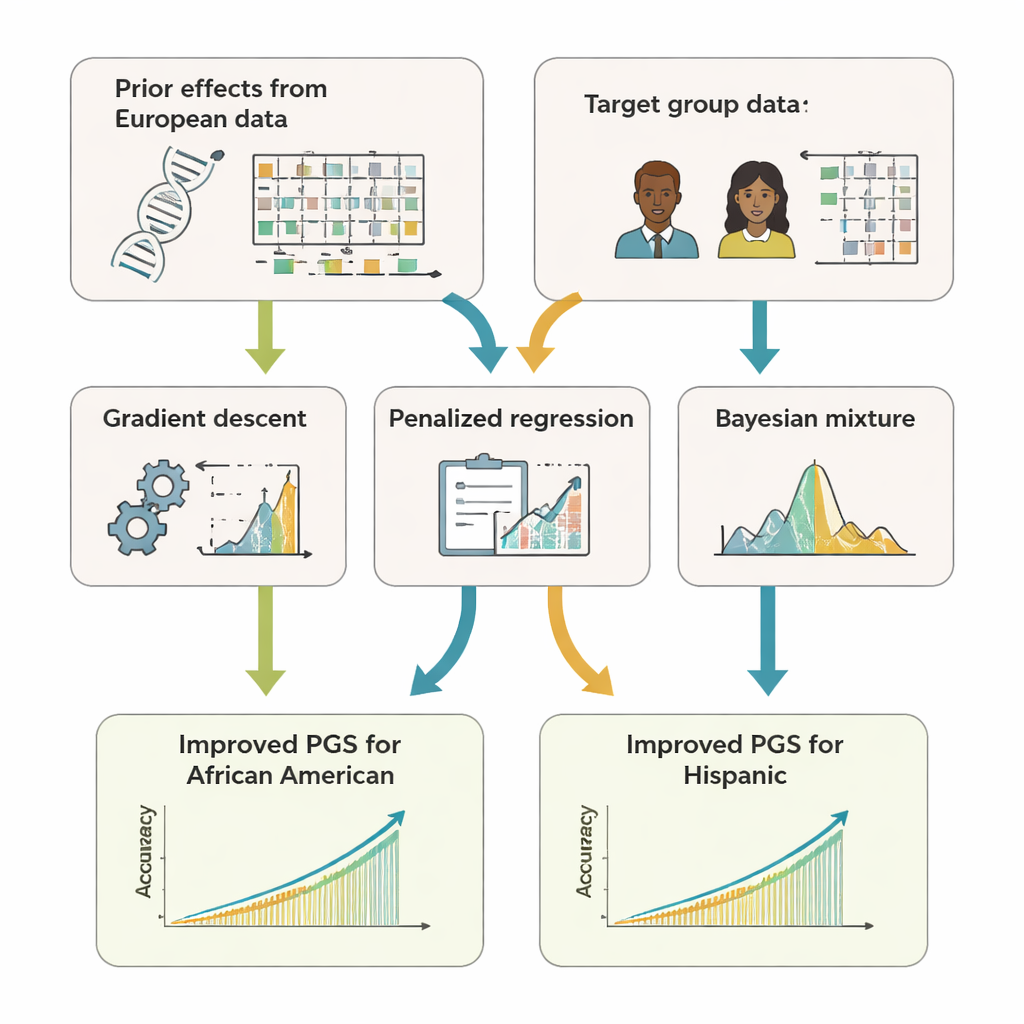
הצוות פיתח את GPTL, חבילת תוכנה קוד-פתוח ב‑R שמממשת שלוש גישות של למידת העברה לציונים גנטיים. שלושתן מתחילות מהערכות קיימות של השפעות DNA שהתקבלו ממערך נתונים גדול של מוצא אירופי ואז מתאימות בעדינות את ההערכות האלה באמצעות נתונים מקבוצת יעד, כמו אפרו-אמריקאים או היספנים. שיטה אחת מלטשת את המשקלים האירופיים צעד אחרי צעד בעזרת ירידת שיפוע ועוצרת מוקדם, לפני שהיא מוחקת אותם לחלוטין. שיטה שנייה, שנקראת רגרסיה מנועלת (penalized regression), מושכת את ההערכות החדשות לעבר הערכים המקוריים אלא אם נתוני היעד מספקים ראיות חזקות אחרת. השלישית, מודל תערובת בייזיאני, מאפשר לכל סמן DNA לבחור בין מספר מקורות מידע — כגון קבוצות מוצא מרובות או אפילו אופציית "ללא השפעה" — וממזג אותם בהתאם לאיך שהם מסבירים את נתוני היעד.
בדיקה מעשית של השיטות
כדי לבחון עד כמה הגישות האלו עובדות, המחברים השתמשו גם בסימולציות ממחושב וגם בנתונים אמיתיים ממאות אלפי מתנדבים בבנק הביולוגי של בריטניה ובתוכנית המחקר האמריקאית All of Us. הם התרכזו במשתתפים אפרו-אמריקאים ובהיספנים כקבוצות יעד והשתמשו בנתוני מוצא אירופי כמקור העיקרי למידע קודם. לאורך 11 תכונות — כולל גובה, מדד מסת גוף, ליפידים בדם, לחץ דם וסמנים כלייתיים — ציוני למידת ההעברה ניבאו בעקביות טוב יותר מציונים שנבנו רק בתוך קבוצת היעד או שנאמצו ישירות מהאירופים. לעתים קרובות, דיוקם השווה או השאיר מאחור במעט שיטות מורכבות יותר של "רב-מוצא" שדורשות שילוב נתוני גולמים ממספר אוכלוסיות. באופן מכריע, השיטות של GPTL זקוקות רק לסטטיסטיקות מסכמות — מספרים מצטברים על השפעות גנטיות — כך שמוסדות יכולים לשתף פעולה ללא גילוי רשומות גנטיות ברמת הפרט.
כשיותר DNA לא תמיד אומר טוב יותר
החוקרים גם בדקו כיצד הכי טוב לבחור אילו סמנים גנטיים לכלול. בניגוד לאמונה הנפוצה ששימוש בכל סמן זמין תמיד עוזר, הם מצאו שעבור קבוצות אפרו-אמריקאיות ובמיוחד היספניות, הכללת מיליוני אותות חלשים מאוד עלולה בפועל לפגוע בביצועים, במיוחד בעת שימוש בייצוגים מפושטים מאוד של קורלציות גנטיות. התמקדות בסמנים הנתמכים טוב יותר ושימוש במידע עשיר יותר על איך וריאנטים עוברים יחד הניבה לעתים קרובות ציונים מדויקים יותר. המחקר גם הראה שהוספת מידע קודם מקבוצות מוצא מרובות ודגימה מדוקדקת של ההבדלים בין אוכלוסיות שיפרו עוד יותר את הניבויים.
מה המשמעות של זה עבור חיזוי סיכון גנטי הוגן יותר
לאוכלוסיות שאינן אירופאיות, ציוני סיכון גנטיים זמינים על המדף עלולים להניב ביצועים נמוכים בהבדלים משמעותיים, מה שעלול להרחיב את פערי הבריאות. עבודה זו מדגימה שלמידת העברה — ליטוש חכם של ציונים מבוססי אירופים באמצעות מערכי נתונים צנועים מקבוצות שאינן מיוצגות — יכולה לצמצם חלק גדול מהפער הזה. במבצע, משמעות הדבר היא שמערכות בריאות וחוקרים יכולים לבנות כלי גנטי מדויק והוגן יותר בלי לאחד נתוני גולמים בין מוסדות או מוצאים, מה שמקל על חששות פרטיות. אף שדרך אחת לא תהיה מיטבית לכל תכונה ולכל אוכלוסייה, ערכת הכלים GPTL מראה שחיזוי גנטי הוגן יותר אפשרי מבחינה טכנית אם נטפל במודלים קודמים לא כמוצרים סופיים, אלא כנקודות התחלה שניתן להתאים לכולם.
ציטוט: Wu, H., Pérez-Rodríguez, P., Boehnke, M. et al. Improving polygenic score prediction for underrepresented groups through transfer learning. Nat Commun 17, 1973 (2026). https://doi.org/10.1038/s41467-026-68696-7
מילות מפתח: ציוני סיכון פולי-גניים, למידת העברה, חיזוי גנטי, פערי בריאות, גנטיקה של אוכלוסיות